简单分析,还有一些地方整不明白
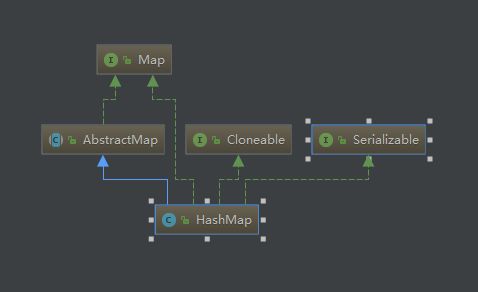
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
/**
* Hash table based implementation of the <tt>Map</tt> interface. This
* implementation provides all of the optional map operations, and permits
* <tt>null</tt> values and the <tt>null</tt> key. (The <tt>HashMap</tt>
* class is roughly equivalent to <tt>Hashtable</tt>, except that it is
* unsynchronized and permits nulls.) This class makes no guarantees as to
* the order of the map; in particular, it does not guarantee that the order
* will remain constant over time.
HashMap允许空值在源码的注释中已经说明了
HashMap与HashTable唯一的不同就是HashMap不是线程安全的而且允许空
如果想用HashMap实现线程安全,可以使用Collections工具类.synchronized方法
如果不用HashMap,可以用HashTable ConcurrentHashMap(分成一个个Segment加锁,减小锁的粒度,听说jdk1.8后源码有改动,不是多熟,之后再看)
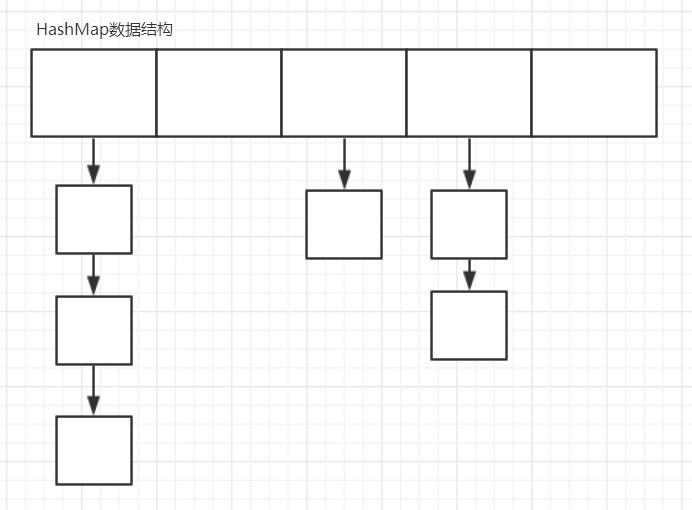
简单来说
HashMap = 数组 + 单向链表
回顾一下数组和链表:
数组:ArrayList —> Object [ ]
链表:LinkedList(双向链表)
内部类Node(就是存储在HashMap的每一个结点,类比LinkedList的结点):
/**
* Basic hash bin node, used for most entries. (See below for
* TreeNode subclass, and in LinkedHashMap for its Entry subclass.)
*/
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}首先要关注三个成员变量:
hash
key
value
内部类重写HashCode()方法
key的HashCode和value的HashCode求异或
内部类重写equals()方法
key相等,value相等,才是真的相等
不是说HashMap有数组嘛,找找这个数组在哪个鬼地方?
table数组
/**
* The table, initialized on first use, and resized as
* necessary. When allocated, length is always a power of two.
* (We also tolerate length zero in some operations to allow
* bootstrapping mechanics that are currently not needed.)
*/
transient Node<K,V>[] table;这个table 在第一次使用时初始化,在需要时增长容量。
分配时,长度是2的次幂,为啥是2的次幂,后面再说(初始容量是2的次幂,后来每次的扩充也是2的次幂,这样设计是有一定道理的)
table就是一个Node数组 ,每个结点又可以纵向的挂结点
那么问题来了,table的初始大小是多少呢?最大能有多少呢?什么时候需要扩容,怎么实现扩容?每个结点又能再挂多少个结点?
这些问题大概都是面试种经常爱问的。
这些问题都可以在源码中找到答案。
默认大小
/**
* The default initial capacity - MUST be a power of two.
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16默认大小1<<4 就是2的4次方16 ,成了,初始大小为16
MUST be a power of two
看到没有,must情态动词表示一定的,必是2的次方
最大容量
/**
* The maximum capacity, used if a higher value is implicitly specified
* by either of the constructors with arguments.
* MUST be a power of two <= 1<<30.
*/
static final int MAXIMUM_CAPACITY = 1 << 30;最大的容量,2的30次方
为什么会有最大容量这个概念,因为虽然初始为16,但如果table装不下了,容量是可以double扩展的,肯定不能一直扩展,内存也吃不消,有一个限定
负载因子
/**
* The load factor used when none specified in constructor.
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;初始容量16
真正的阈值是16*0.75=12
结点到12后,就会double扩容
数组都有最大值了,那么链表有最大值吗
链表的结点也总不能一直往下挂把。。。
会有一个限制
/**
* The bin count threshold for using a tree rather than list for a
* bin. Bins are converted to trees when adding an element to a
* bin with at least this many nodes. The value must be greater
* than 2 and should be at least 8 to mesh with assumptions in
* tree removal about conversion back to plain bins upon
* shrinkage.
*/
static final int TREEIFY_THRESHOLD = 8;
每个节点最多挂8
如果超过8,就要改变链表结构
链表 —— > 平衡二叉树
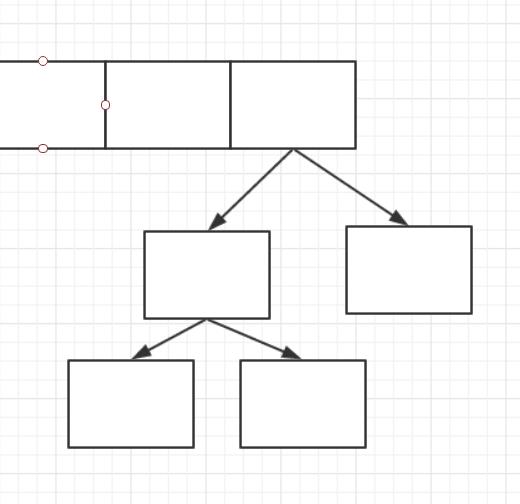
Node ———->TreeNode
/**
* The bin count threshold for untreeifying a (split) bin during a
* resize operation. Should be less than TREEIFY_THRESHOLD, and at
* most 6 to mesh with shrinkage detection under removal.
*/
static final int UNTREEIFY_THRESHOLD = 6;如果小于6,平衡二叉树再变回为链表
TreeNode ————>Node
初始大小为16的数组
那么每塞一个Node的位置怎么确定? node内部类有个变量hash就是用来确定位置的
根据key求hash
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}hashCode()生成32位二进制数
key的hashCode() 与 key的hashCode()向右移16位 做异或
这样设计的意义在于充分利用hashCode()的高16位和低16位
使得到的hash值尽可能的不同
有了hash值 那么就可以通过hash值确定节点的位置
怎么确定位置
table的大小位16
位置= hash % 16
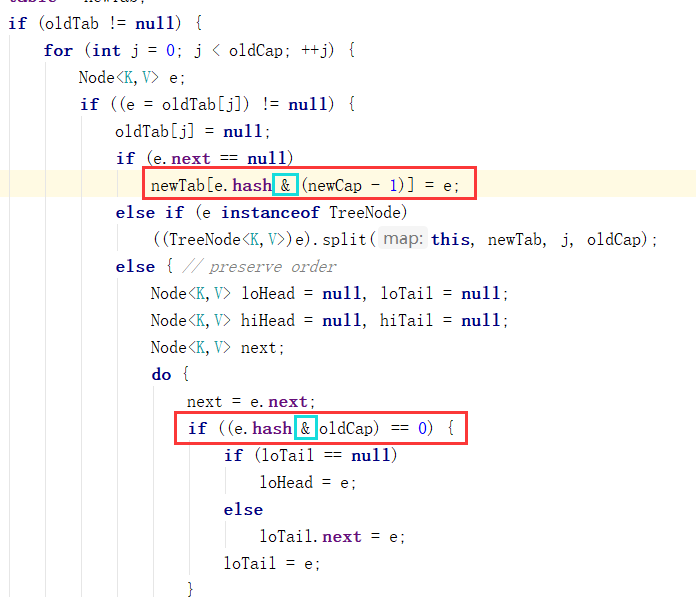
在源码中用&替换% 因为&运算效率更高
hash & (size-1) 即hash & (16-1) —–> hash & 15
再说下上文提到的为什么table的容量大小都是2的次方
原因是这样的
以刚才hash & 15为例

如果double扩容 16*2=32

发现一个特点:
2的n次方(n>=4) 的结果 -1再转化为二进制数,全是1…1
这样设计的意义在于使结点落在table的位置取决于hash值,而不受容量大小的影响
一直说double扩容,double扩容在哪里呢
在一个HashMap核心方法resize( )

double threshold
扩容的结点还需要为其他结点分担挂的结点
每次扩容,需要重新计算hash,重新打散,目的是更好的利用所有结点
假定某结点在原数组中扩容后,这个结点的位置:
可能在两个位置,原位置或( 原位置的下标+原容量)的位置
转载请注明:汪明鑫的个人博客 » HashMap源码分析




说点什么
您将是第一位评论人!