wget无法使用,但提示已安装
[root@c2023072403887 ~]# wget
-bash: wget: 未找到命令
[root@c2023072403887 ~]# whereis wget
wget: /usr/share/man/man1...
汪明鑫
12个月前 (08-07) 421浏览 0评论
1喜欢
有同学在一次代码调整中,mysql “insert ignore into” 错误改为 “insert into”,导致线上问题
insert ignore into 印象中我们通常用来处理uk重复插入异常,还有另一个坑,...
汪明鑫
1年前 (2023-07-24) 447浏览 0评论
0喜欢
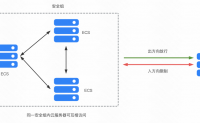
安全组是一种虚拟防火墙,用于在云端划分安全区域。通过配置安全组规则,您可以允许或禁止安全组内的多台云服务器的流量出/入。安全组具备状态检测和数据包过滤能力,可以阻止所有未在规则内明确允许的流量。
一些使用建议:
● 仅允许少量请求访问云服务器...
汪明鑫
1年前 (2023-07-24) 502浏览 0评论
0喜欢
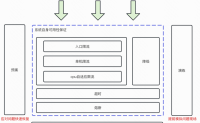
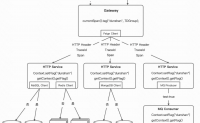
服务整体的可用性,需要方方面面来保证
服务可用性也是衡量系统的一个关键指标
看上图,系统自身我们要配置好入口处的限流、单机限流、cpu自适应限流,对下游做好超时熔断配置,并做好降级方案
通过监控报警发现和定位问题
通过一些演练,来提前模拟...
汪明鑫
1年前 (2023-03-29) 512浏览 0评论
0喜欢
一般来说线上一直在跑的业务需求的迭代无需特意预热,线上一般都有流量在跑
新的接口,但是在老的集群和服务,其实也不需要特意的预热
新接口新的集群服务,一般来说可以做些许的预热,但是一般来说其实功能放量的过程其实也是预热的过程,只不过使用线上的流量来进行预热的
什...
汪明鑫
1年前 (2023-03-29) 702浏览 0评论
1喜欢
Redis原子性
一般我们会通过加锁来控制并发请求,但是加锁肯定是有消耗的,而且加锁本身也会引入其他一系列的问题,如分布式锁失效等。
那么原子操作便是另一个控制并发请求的手段,即无锁操作。
Redis有2种原子操作方法:
1.单命令操作
2.lua...
汪明鑫
1年前 (2023-02-08) 478浏览 0评论
0喜欢
在一些简单的业务场景下,其实不用考虑锁的重入、重试等问题,也很少需要考虑Redis主从切换,分布式锁失效。
那么一种最简单的分布式锁实现,其实就是Redis setNX, 其实已经能满足大多数场景了
直接上代码:
public class RedisD...
汪明鑫
1年前 (2023-02-07) 562浏览 0评论
0喜欢
no code say j8
先把代码fork过来
https://github.com/redis/redis
https://github.com/xinyeshuaiqi/redis
代码下载到本地
再安装一个c/c++开发工具 cl...
汪明鑫
1年前 (2023-02-07) 540浏览 0评论
1喜欢
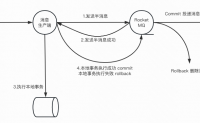
之前记住这个图,就自认为理解了事务消息,然而在生产中真的用的事务消息时,发现还是有很多地方理解不到位的,这里再好好学习,深入理解一下。
RocketMQ可以帮助我们实现最终一致性
比如我们本地执行一个事务,然后还有一个其他系统的事务,我们想保证2个模...
汪明鑫
1年前 (2023-02-06) 488浏览 0评论
0喜欢
“影子”的概念在技术侧最早诞生于阿里的大促全链路压测
那我们先来聊下全链路压测
由于业务不断的架构升级,引入分布式微服务
传统的线下测试已经不能满足我们的测试需求了,因此需要全链路压测
一般需要压测平台,创建配置压测计划,对接口进行发压
这样的压测流...
汪明鑫
2年前 (2022-04-22) 955浏览 0评论
3喜欢