目录
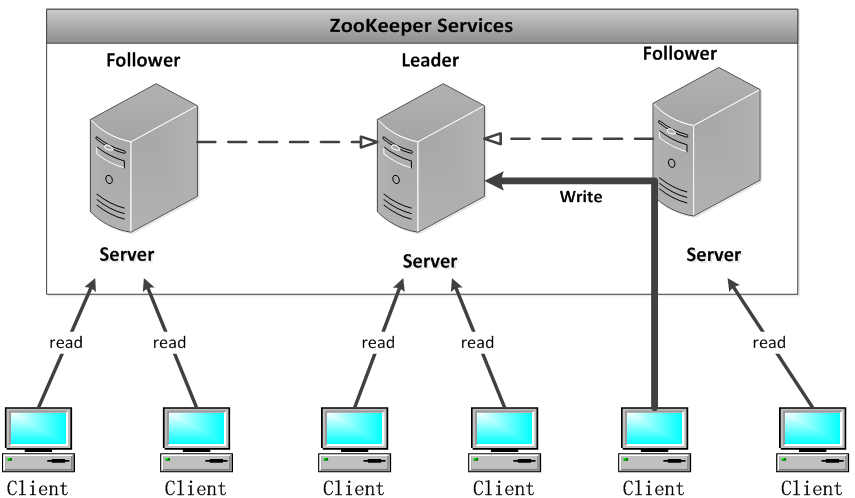
集群中的角色
- 群首 leader
作为中心点处理所有对Zookeeper系统变更的事务请求
他像一个定序器,建立了所有事务处理的顺序性
- 追随者 follower
处理非事务请求,转发事务请求给leader
参与leader选举
leader会向所有follower发送事务请求提议Proposal,过半的follower回复ACK,则事务才commit
- 观察者 observer
不参与投票,不处理事务请求且转发给leader
同步leader的状态
提高读请求的可扩展性
zookeeper集群一般是由2n+1台服务器组成
我是跑了三个虚拟机,部署了zookeeper集群 (一主两从)
事务请求的细节
只读请求:exists,egtData,getChildren
事务请求:新增create,更新setData,删除delete
Zookeeper的事务请求具有幂等性
当群首产生一个事务,就会为该事务分配一个标识符
即Zookeeper会话id ——-zxid
通过zxid,事务就可以按照leader指定的顺序在各个服务器中按序执行。
服务器之间在进行新的leader选举时也会交换zxid信息,
这样就可以知道哪个无故障服务器接收了更多的事务,同步他们之间的状态信息。
leader选举
leader无疑时zookeeper集群中最重要的角色,那他是怎么产生的呢?
我之前写的有篇zookeeper投票机制是比较片面的,真正的leader选举是比较复杂的。
什么时候需要leader选举?
(1) zookeeper集群初始化启动,还没有leader,节点相互通信选举leader。
(2) 集群当前leader挂了,需要重新选举leader。
org.apache.zookeeper.server.quorum.Vote
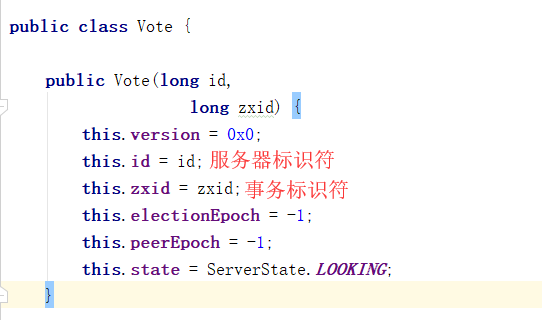
peerEpoch:被推举的Leader的epoch。
state:当前服务器的状态。
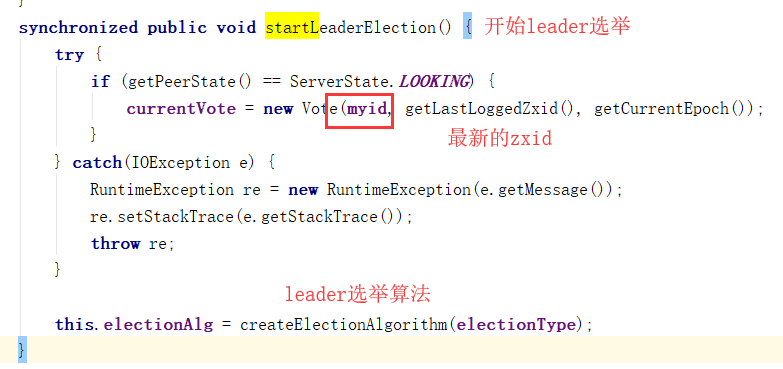
/**
* returns the highest zxid that this host has seen
*
* @return the highest zxid for this host
*/
public long getLastLoggedZxid() {
if (!zkDb.isInitialized()) {
loadDataBase();
}
return zkDb.getDataTreeLastProcessedZxid();
}返回最新的事务请求的标识符zxid
源码我还看不太懂,不熟,暂时先看到这里,之后再慢慢研究。
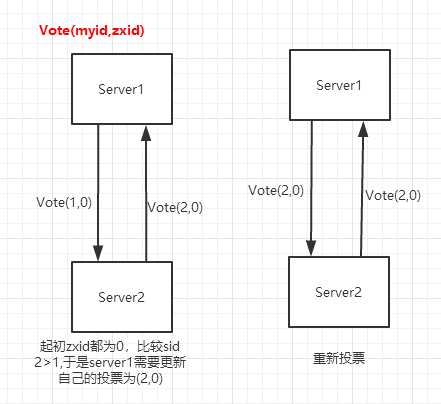
leader选举过程:
每一次投票都会发给集群中的每一台服务器。
起初Zookeeper集群初次启动,zxid都为0
针对每一次投票,要和别人发来的投票和自己手里拽着的投票对比,
如果别人发来的投票的zxid大于我手里拽着的投票 或者
zxid相等但发来的id大于myid,
修改我的投票Vote(myZxid,myId)为发来的投票Vote(zxid,id)。
即投票给zxid最大的(状态)最新的服务器
图解leader选举过程:
我们为了简单,先只分析2台服务器,实际上在集群中的分析方法是一样的,


拜占庭问题
在很久很久以前,拜占庭是东罗马帝国的首都。那个时候罗马帝国国土辽阔,为了防御目的,因此每个军队都分隔很远,将军与将军之间只能靠信使传递消息。
在打仗的时候,拜占庭军队内所有将军必需达成一致的共识,才能更好地赢得胜利。但是,在军队内有可能存有叛徒,扰乱将军们的决定。
这时候,在已知有成员不可靠的情况下,其余忠诚的将军需要在不受叛徒或间谍的影响下达成一致的协议。
莱斯利·兰伯特( Leslie Lamport )通过这个比喻,表达了计算机网络中所存在的一致性问题。这个问题被称为拜占庭将军问题。
解决拜占庭问题: Paxos,raft,Zab
Zab协议
Zab Zookeeper Atomic Broadcast 原子消息广播协议
Zab协议是特别为Zookeeper设计的崩溃可恢复的原子消息广播算法
Zab协议有效的解决了Zookeeper集群崩溃恢复,以及主从同步数据的问题。
Zab协议包含2种基本的模式:
(1)崩溃恢复
(2)消息广播
当Zookeeper集群初始启动,或者leader挂了,Zab协议就会进入恢复模式并选举差生新的Leader,而且集群种已经有过半的机器与leader完成状态同步后,
进入消息广播模式。
Zab协议的核心是定义了对于那些会改变Zookeeper服务器数据状态的事务请求的处理方式:
leader把客户端的事务请求转换成一个事务Proposal(提议),并将该提议广播,之后leader等待follower的反馈,如果过半follower返回ack,则leader再次广播commit,
将前一个Proposal提交。
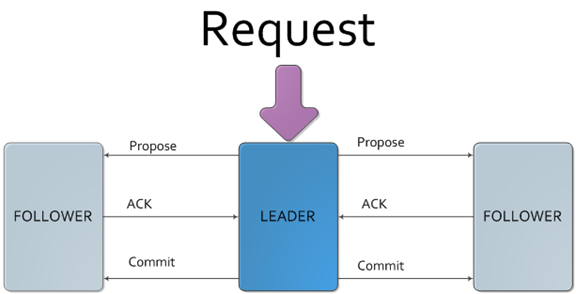
类似分布式事务的2pc(two-phrase commit 两阶段提交)
Leader提起一个决议,由Followers进行投票,Leader对投票结果进行计算决定是否通过该决议,如果通过执行该决议(事务),否则什么也不做。
Zab协议要确保那些已经在leader上提交的事务最终被所有服务器提交,丢弃只在leader上被提出的事务。
Zab协议既不是强一致性,也不是弱一致性,而是处于两者之间的单调一致性。它依靠事务ID和版本号,保证了数据的更新和读取是有序的。
转载请注明:汪明鑫的个人博客 » Zookeeper原理

说点什么
您将是第一位评论人!