HashMap,HashTable,ConcurrentHashMap 这三兄弟基本面试必问
工作和学习中也会经常遇到
Jdk中的所有数据结构源码都需要过一遍吗?
我也不知道,反正我不会,因为水平不够,再来是代价太大,
Jdk源码写的还是很牛逼的
我是想起来闲的话源码点进去瞅两眼
HashTable的线程安全是通过锁整张table,这样势必会造成性能上的损耗
加锁解锁用脚趾头想都会消耗性能,
而且既然有锁,就一定会有等待,有等待就会造成阻塞,有阻塞,就会降低性能
因此原则上能不用锁就不用锁,如果不能避免使用锁,也要降低锁的粒度,也可以在性能上做一些优化
包括ArrayList,Vector都是列表,Vector是线程安全的,但是他的性能就不如ArrayList
HashMap的源码以前简单的看过,这个源码记得去年面试的时候回回问,我都快会背了。。。
HashMap是线程不安全的,可以通过Collections工具类转为线程安全的
ConcurrentHashMap和HashTable都是线程安全的,那为什么从来没见过HashTable这老哥被人使用过呢
因为ConcurrentHashMap是粒度更细的锁,而HashTable一锁就是锁整张表,这谁顶得住
早期版本 ConcurrentHashMap是通过分段锁来降低锁的粒度,
把整张表分成一段段的segment,操作时定位到一个segment,只锁这一个segment,其他segment同样可以操作
在一个segment可以支持读写兵法,不支持写写兵法
不同segment无所谓,随便操作,不影响
ConcurrentHashMap当中每个Segment各自持有一把锁。在保证线程安全的同时降低了锁的粒度,让并发操作效率更高。
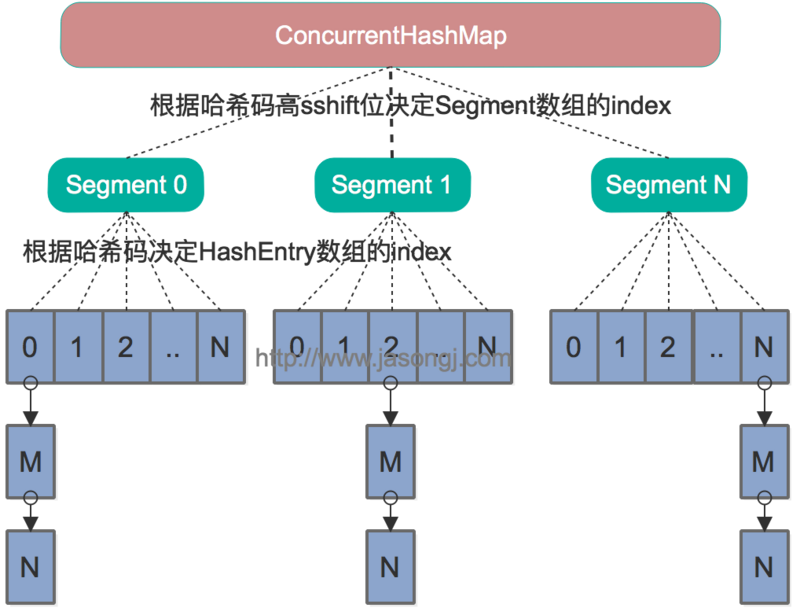
Get方法:
1.为输入的Key做Hash运算,得到hash值。
2.通过hash值,定位到对应的Segment对象
3.再次通过hash值,定位到Segment当中数组的具体位置。
Put方法:
1.为输入的Key做Hash运算,得到hash值。
2.通过hash值,定位到对应的Segment对象
3.获取可重入锁
4.再次通过hash值,定位到Segment当中数组的具体位置。
5.插入或覆盖HashEntry对象。
6.释放锁。
JDK 1.8之后,ConcurrentHashMap是基于CAS实现的
瞅一眼源码
核心静态内部类Node,和HashMap的差不多
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
volatile修饰table,保证可见性
/**
* The array of bins. Lazily initialized upon first insertion.
* Size is always a power of two. Accessed directly by iterators.
*/
transient volatile Node<K,V>[] table;
核心方法 putVal
final V putVal(K key, V value, boolean onlyIfAbsent) {
//不允许为空
if (key == null || value == null) throw new NullPointerException();
//key ---> hash 打散
int hash = spread(key.hashCode());
int binCount = 0;
//遍历table
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
//初始化table
if (tab == null || (n = tab.length) == 0)
tab = initTable();
//如果hash路由到的位置是空的,则利用cas无锁新增结点
//i表示路由到的位置
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
//利用CAS
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
synchronized (f) { //细粒度加锁
if (tabAt(tab, i) == f) {
if (fh >= 0) { //fh就是f的hash
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val; //记录旧值
if (!onlyIfAbsent)
e.val = value; //key、hash都相同,则值覆盖
break;
}
Node<K,V> pred = e; //否则创建新的node,并插在链表尾部
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
//二叉树操作
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
//达到阀值,结点树化
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
初始化table
/**
* Initializes table, using the size recorded in sizeCtl.
*/
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
while ((tab = table) == null || tab.length == 0) {
// 如果发现冲突,进行spin等待
if ((sc = sizeCtl) < 0)
Thread.yield(); // lost initialization race; just spin
// CAS成功返回true,则进入真正的初始化逻辑
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
if ((tab = table) == null || tab.length == 0) {
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
sc = n - (n >>> 2);
}
} finally {
sizeCtl = sc;
}
break;
}
}
return tab;
}
水平原因先到这里,后续有空再接着研究源码, 然后安排时间系统学习下 CAS
转载请注明:汪明鑫的个人博客 » ConcurrentHashMap 浅析




说点什么
您将是第一位评论人!