没有用过Guava Cache的同学先看一下介绍的文章 http://xinyeshuaiqi.cn/2020/06/08/local-cache/
本文主要介绍一些Guava Cache的一些数据结构和底层原理
先看一眼核心类图:
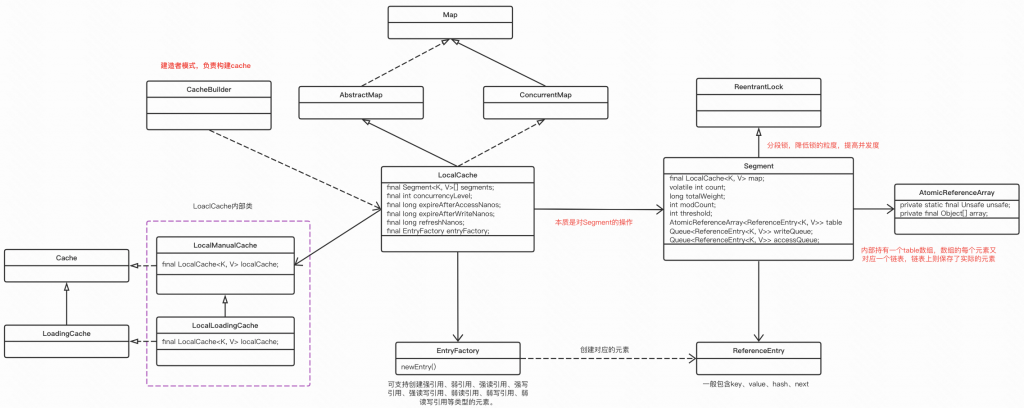
吗的,图有点大,看着好糊。。。
CacheBuilder使用了建造者模式,负责构建cache
LocalCache本身是一个Map,内部封装了Segment,通过分段锁,降低锁的粒度,提高并发度
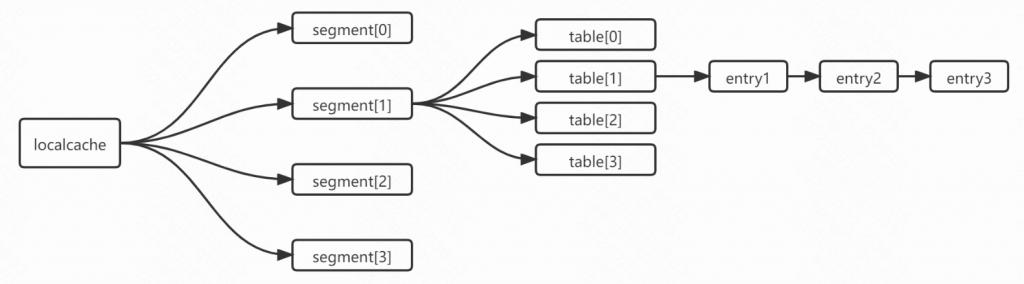
Segment内部又有一个数组,数组的元素是ReferenceEntry, 又是一个链表
然后LocalCache还有2内部类:
1、LocalManualCache实现了Cache,具有了所有cache方法。
2、LocalLoadingCache实现了LoadingCache,具有了所有LoadingCache方法。
3、LocalLoadingCache继承了LocalManualCache,那么对外暴露的LocalLoadingCache的方法既有自身需要的,又有cache应该具有的。
4、通过LocalLoadingCache和LocalManualCache的父子关系实现了LocalCache的细节。
这个操作到底有多大意义,我没太看明白,是不是要一个内部类也可以做到,甚至不要内部类,感觉还更清晰点。
存储结构大概是这个样子:
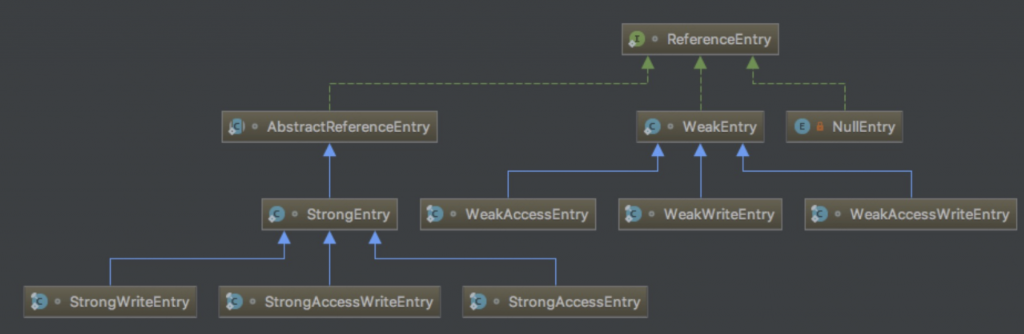
ReferenceEntry 支持不同的引用类型:
回想我们是如何操作一个Map呢?put KV, get K
但是LocalCache并不需要我们主动put值,而是构造缓存时指定loader,get时不存在再触发缓存load
@CheckReturnValue
public <K1 extends K, V1 extends V> LoadingCache<K1, V1> build(
CacheLoader<? super K1, V1> loader) {
checkWeightWithWeigher();
return new LocalCache.LocalLoadingCache<>(this, loader);
}那我们就顺着这个build的主流程往下去看!
核心的初始化代码就在这里:
/**
* Creates a new, empty map with the specified strategy, initial capacity and concurrency level.
*/
LocalCache(
CacheBuilder<? super K, ? super V> builder, @Nullable CacheLoader<? super K, V> loader) {
concurrencyLevel = Math.min(builder.getConcurrencyLevel(), MAX_SEGMENTS);
// 。。。
// 一些赋值操作
int segmentShift = 0;
int segmentCount = 1;
// evictsBySize()表示是否限制容量
while (segmentCount < concurrencyLevel && (!evictsBySize() || segmentCount * 20 <= maxWeight)) {
// 这时的segmentShift还是表示segmentCount是2的多少次幂
++segmentShift;
// segmentCount是满足while条件的最大值的2倍
segmentCount <<= 1;
}
// 最终的segmentShift用于取hash的高位的相应位数,用来计算寻找一个元素在哪个segment中
this.segmentShift = 32 - segmentShift;
// 掩码,取hash的低位的相应位数的值,即为在segment中的角标
segmentMask = segmentCount - 1;
// 先创建数组
this.segments = newSegmentArray(segmentCount);
// 设置每个segment中数组的大小,保整每个segmentSize大小为2的n次方
// 总的segmentSize大于等于initialCapacity
// segmentCapacity = initialCapacity 除以 segmentCount 向上取整
int segmentCapacity = initialCapacity / segmentCount;
if (segmentCapacity * segmentCount < initialCapacity) {
++segmentCapacity;
}
// segmentSize = 不小于segmentCapacity的 最小的 2的整数幂
// segmentSize用作段的初始容量
int segmentSize = 1;
while (segmentSize < segmentCapacity) {
segmentSize <<= 1;
}
// 初始化数组的每个segment
if (evictsBySize()) {
// Ensure sum of segment max weights = overall max weights
long maxSegmentWeight = maxWeight / segmentCount + 1;
long remainder = maxWeight % segmentCount;
for (int i = 0; i < this.segments.length; ++i) {
if (i == remainder) {
maxSegmentWeight--;
}
this.segments[i] =
createSegment(segmentSize, maxSegmentWeight, builder.getStatsCounterSupplier().get());
}
} else {
for (int i = 0; i < this.segments.length; ++i) {
this.segments[i] =
createSegment(segmentSize, UNSET_INT, builder.getStatsCounterSupplier().get());
}
}
}
Segment(
LocalCache<K, V> map,
int initialCapacity,
long maxSegmentWeight,
StatsCounter statsCounter) {
this.map = map;
this.maxSegmentWeight = maxSegmentWeight;
this.statsCounter = checkNotNull(statsCounter);
initTable(newEntryArray(initialCapacity));
keyReferenceQueue = map.usesKeyReferences() ? new ReferenceQueue<>() : null;
valueReferenceQueue = map.usesValueReferences() ? new ReferenceQueue<>() : null;
recencyQueue =
map.usesAccessQueue() ? new ConcurrentLinkedQueue<>() : LocalCache.discardingQueue();
writeQueue = map.usesWriteQueue() ? new WriteQueue<>() : LocalCache.discardingQueue();
accessQueue = map.usesAccessQueue() ? new AccessQueue<>() : LocalCache.discardingQueue();
}OK,下面来看下核心的加载数据流程
@Override
public V get(K key, final Callable<? extends V> valueLoader) throws ExecutionException {
checkNotNull(valueLoader);
return localCache.get(
key,
new CacheLoader<Object, V>() {
@Override
public V load(Object key) throws Exception {
return valueLoader.call();
}
});
}V get(K key, CacheLoader<? super K, V> loader) throws ExecutionException {
int hash = hash(checkNotNull(key));
return segmentFor(hash).get(key, hash, loader);
}通过hash定位segment, 从segment取数
V get(K key, int hash, CacheLoader<? super K, V> loader) throws ExecutionException {
checkNotNull(key);
checkNotNull(loader);
try {
// count 表示segment中的元素个数
if (count != 0) { // read-volatile
// don't call getLiveEntry, which would ignore loading values
// 找到对应的entry
ReferenceEntry<K, V> e = getEntry(key, hash);
if (e != null) {
long now = map.ticker.read(); // 获取当前纳秒时间戳
// 拿到存活数据
V value = getLiveValue(e, now);
if (value != null) {
recordRead(e, now); // 记录accessTime
statsCounter.recordHits(1);
// 缓存刷新 --- 后面再聚焦看下
return scheduleRefresh(e, key, hash, value, now, loader);
}
// 如果值为空,看看是不是因为正在加载,如果正在加载阻塞等待
ValueReference<K, V> valueReference = e.getValueReference();
if (valueReference.isLoading()) {
return waitForLoadingValue(e, key, valueReference);
}
}
}
// at this point e is either null or expired;
// segment为空或者key、value不存在或者缓存过期了
return lockedGetOrLoad(key, hash, loader);
} catch (ExecutionException ee) {
Throwable cause = ee.getCause();
if (cause instanceof Error) {
throw new ExecutionError((Error) cause);
} else if (cause instanceof RuntimeException) {
throw new UncheckedExecutionException(cause);
}
throw ee;
} finally {
postReadCleanup();
}
}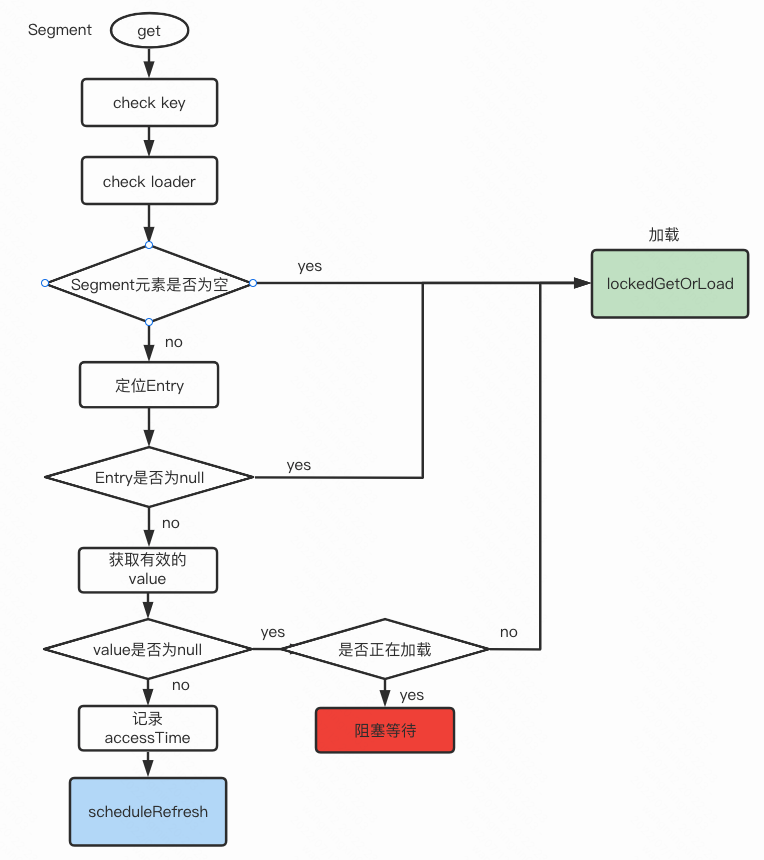
整个流程图看着就会清楚些
多个线程请求,只会有一个线程去真正加载,其他线程阻塞
我们再来看下scheduleRefresh 和 lockedGetOrLoad
V scheduleRefresh(
ReferenceEntry<K, V> entry,
K key,
int hash,
V oldValue,
long now,
CacheLoader<? super K, V> loader) {
if (map.refreshes()
&& (now - entry.getWriteTime() > map.refreshNanos)
&& !entry.getValueReference().isLoading()) {
V newValue = refresh(key, hash, loader, true);
if (newValue != null) {
return newValue;
}
}
return oldValue;
}如果新值没刷出来,直接返回旧值
@Nullable
V refresh(K key, int hash, CacheLoader<? super K, V> loader, boolean checkTime) {
final LoadingValueReference<K, V> loadingValueReference =
insertLoadingValueReference(key, hash, checkTime);
if (loadingValueReference == null) {
return null;
}
ListenableFuture<V> result = loadAsync(key, hash, loadingValueReference, loader);
if (result.isDone()) {
try {
return Uninterruptibles.getUninterruptibly(result);
} catch (Throwable t) {
// don't let refresh exceptions propagate; error was already logged
}
}
return null;
}
刷新是开启一个新的线程去刷新的再来看下 lockedGetOrLoad
V lockedGetOrLoad(K key, int hash, CacheLoader<? super K, V> loader) throws ExecutionException {
ReferenceEntry<K, V> e;
ValueReference<K, V> valueReference = null;
LoadingValueReference<K, V> loadingValueReference = null;
boolean createNewEntry = true;
// 加锁
lock();
try {
// re-read ticker once inside the lock
long now = map.ticker.read();
preWriteCleanup(now);
int newCount = this.count - 1;
AtomicReferenceArray<ReferenceEntry<K, V>> table = this.table;
int index = hash & (table.length() - 1);
// 定位到entry
ReferenceEntry<K, V> first = table.get(index);
for (e = first; e != null; e = e.getNext()) {
K entryKey = e.getKey();
if (e.getHash() == hash
&& entryKey != null
&& map.keyEquivalence.equivalent(key, entryKey)) {
valueReference = e.getValueReference();
if (valueReference.isLoading()) {
// 是否已经在加载了,已经加载的话,就不用在加载啦
createNewEntry = false;
} else {
V value = valueReference.get();
// value 已经被GC回收啦
if (value == null) {
enqueueNotification(
entryKey, hash, value, valueReference.getWeight(), RemovalCause.COLLECTED);
} else if (map.isExpired(e, now)) {
// 是否过期
// This is a duplicate check, as preWriteCleanup already purged expired
// entries, but let's accommodate an incorrect expiration queue.
enqueueNotification(
entryKey, hash, value, valueReference.getWeight(), RemovalCause.EXPIRED);
} else {
// 如果读到的value存在且没有超时,说明value是有效值
recordLockedRead(e, now);
statsCounter.recordHits(1);
// we were concurrent with loading; don't consider refresh
return value;
}
// 读到无效缓存,则移除
// immediately reuse invalid entries
writeQueue.remove(e);
accessQueue.remove(e);
this.count = newCount; // write-volatile
}
break;
}
}
// 没有找到对应的entry, 需要创建一个新entry
if (createNewEntry) {
loadingValueReference = new LoadingValueReference<>();
if (e == null) {
e = newEntry(key, hash, first);
e.setValueReference(loadingValueReference);
table.set(index, e);
} else {
e.setValueReference(loadingValueReference);
}
}
} finally {
// 写操作完成,释放锁
unlock();
postWriteCleanup();
}
if (createNewEntry) {
try {
// Synchronizes on the entry to allow failing fast when a recursive load is
// detected. This may be circumvented when an entry is copied, but will fail fast most
// of the time.
// 如果当前线程触发了缓存加载的操作,就针对e加锁等待加载完成
synchronized (e) {
return loadSync(key, hash, loadingValueReference, loader);
}
} finally {
statsCounter.recordMisses(1);
}
} else {
// The entry already exists. Wait for loading.
// 如果当前线程不是触发缓存加载的操作的线程,就阻塞等待缓存加载完成
return waitForLoadingValue(e, key, valueReference);
}
}V loadSync(
K key,
int hash,
LoadingValueReference<K, V> loadingValueReference,
CacheLoader<? super K, V> loader)
throws ExecutionException {
ListenableFuture<V> loadingFuture = loadingValueReference.loadFuture(key, loader);
return getAndRecordStats(key, hash, loadingValueReference, loadingFuture);
} public ListenableFuture<V> loadFuture(K key, CacheLoader<? super K, V> loader) {
try {
stopwatch.start();
V previousValue = oldValue.get();
if (previousValue == null) {
// 没有旧值 load
V newValue = loader.load(key);
return set(newValue) ? futureValue : Futures.immediateFuture(newValue);
}
// 有旧值 reload
ListenableFuture<V> newValue = loader.reload(key, previousValue);
if (newValue == null) {
return Futures.immediateFuture(null);
}
// To avoid a race, make sure the refreshed value is set into loadingValueReference
// *before* returning newValue from the cache query.
return transform(
newValue,
newResult -> {
LoadingValueReference.this.set(newResult);
return newResult;
},
directExecutor());
} catch (Throwable t) {
ListenableFuture<V> result = setException(t) ? futureValue : fullyFailedFuture(t);
if (t instanceof InterruptedException) {
Thread.currentThread().interrupt();
}
return result;
}
}加载过程看的差不多了,再来看下元素是什么时候过期移除的
移除不是自动移除的,其实是伴随着get 的行为来做过期移除逻辑
如果是配置的 refreshAfterWrite 就是触发刷新,刷不到新值就直接返回旧值
如果是配置了 expireAfterWrite、expireAfterAccess呢
在上面的get方法中有一个方法调用 com.google.common.cache.LocalCache.Segment#getLiveValue
/**
* Gets the value from an entry. Returns null if the entry is invalid, partially-collected,
* loading, or expired.
*/
V getLiveValue(ReferenceEntry<K, V> entry, long now) {
if (entry.getKey() == null) {
tryDrainReferenceQueues();
return null;
}
V value = entry.getValueReference().get();
if (value == null) {
tryDrainReferenceQueues();
return null;
}
// 判断是否过期
if (map.isExpired(entry, now)) {
// 过期清理
tryExpireEntries(now);
return null;
}
return value;
}/** Returns true if the entry has expired. */
boolean isExpired(ReferenceEntry<K, V> entry, long now) {
checkNotNull(entry);
if (expiresAfterAccess() && (now - entry.getAccessTime() >= expireAfterAccessNanos)) {
// 配置了expiresAfterAccess,上次的accessTime已过期
return true;
}
if (expiresAfterWrite() && (now - entry.getWriteTime() >= expireAfterWriteNanos)) {
// 配置了expiresAfterWrite,上次的writeTime已过期
return true;
}
return false;
}/** Cleanup expired entries when the lock is available. */
void tryExpireEntries(long now) {
// 尝试加锁清理entry
if (tryLock()) {
try {
expireEntries(now);
} finally {
unlock();
// don't call postWriteCleanup as we're in a read
}
}
}@GuardedBy("this")
void expireEntries(long now) {
drainRecencyQueue();
ReferenceEntry<K, V> e;
while ((e = writeQueue.peek()) != null && map.isExpired(e, now)) {
if (!removeEntry(e, e.getHash(), RemovalCause.EXPIRED)) {
throw new AssertionError();
}
}
while ((e = accessQueue.peek()) != null && map.isExpired(e, now)) {
if (!removeEntry(e, e.getHash(), RemovalCause.EXPIRED)) {
throw new AssertionError();
}
}
}从 writeQueue 和 accessQueue 中取出元素清理
最后小结一下:
通过CacheBuilder设置参数创建缓存,LocalCache封装了对Segment的操作,
Segment里又有一个数组,数组的每个元素都是一个entry,entry也是一个链表,存储元素
entry 的key,value支持不同的引用类型
可以自定义刷新时间和过期时间
刷新如果刷不出来新值,直接返回旧值
然后entry的清理是伴随着get操作进行的
通过加锁的方式和设置entry loading 状态来避免重复加载
可以注册 RemoveLienster, 数据移除可以接受通知
支持缓存命中情况的统计
转载请注明:汪明鑫的个人博客 » Guava Cache 原理分析




说点什么
您将是第一位评论人!