目录
前言
真正工作中目前用的不多,
可能实习接触不到库表索引的创建
大部分都是查询工作
表都是设计好的,索引也都是设计好的
像我在dao层,写简单的sql(mybatis基于注解)
不允许写复杂的sql,比如多表join,子查询等
复杂的逻辑一般都写在service层
工作中索引的影子好像离我们很远
记得在网易的时候,创建索引,还要申请且要注明原因,
先是语法检查,通过后,DBA审核后再由DBA帮你创建索引
但是索引不得不说又很重要
好的索引能够避免慢查询
好的索引可以显著增加查找效率
一般可以使用explain查看select语句索引命中情况
创建索引的语句,索引的作用,聚集索引、非聚集索引,
索引的命中情况等等都是面试经常爱问的问题
关于索引我也是个半吊子,还需要加深学习和理解
本文主要是以mysql为准介绍索引,
由于本人水平有限,如有瑕疵纰漏,敬请指正
什么是数据库索引
数据库索引就是一种加快大量数据查询的关键技术。
索引的设计思想
新华字典大家都不陌生
小学的时候第一本新华字典入手,写作业再也不用拼音~
但是新华字典最牛逼的还是他的检索功能——索引
(拼音检索、偏旁检索、笔画检索)
数据库索引大概率是模仿而来的
索引的SQL语句
在指定列创建索引
CREATE INDEX index_name ON table_name (column_list)
删除索引
DROP INDEX index_name ON talbe_name
查看索引
show index from tblname;
联合索引
ALTER TABLE table_name ADD INDEX index_name(column1, column2, column3)
索引的分类
主键索引 PRIMARY KEY
唯一索引 UNIQUE
普通索引 INDEX
组合索引 INDEX
在这里就不一一介绍了=-=
mysql架构
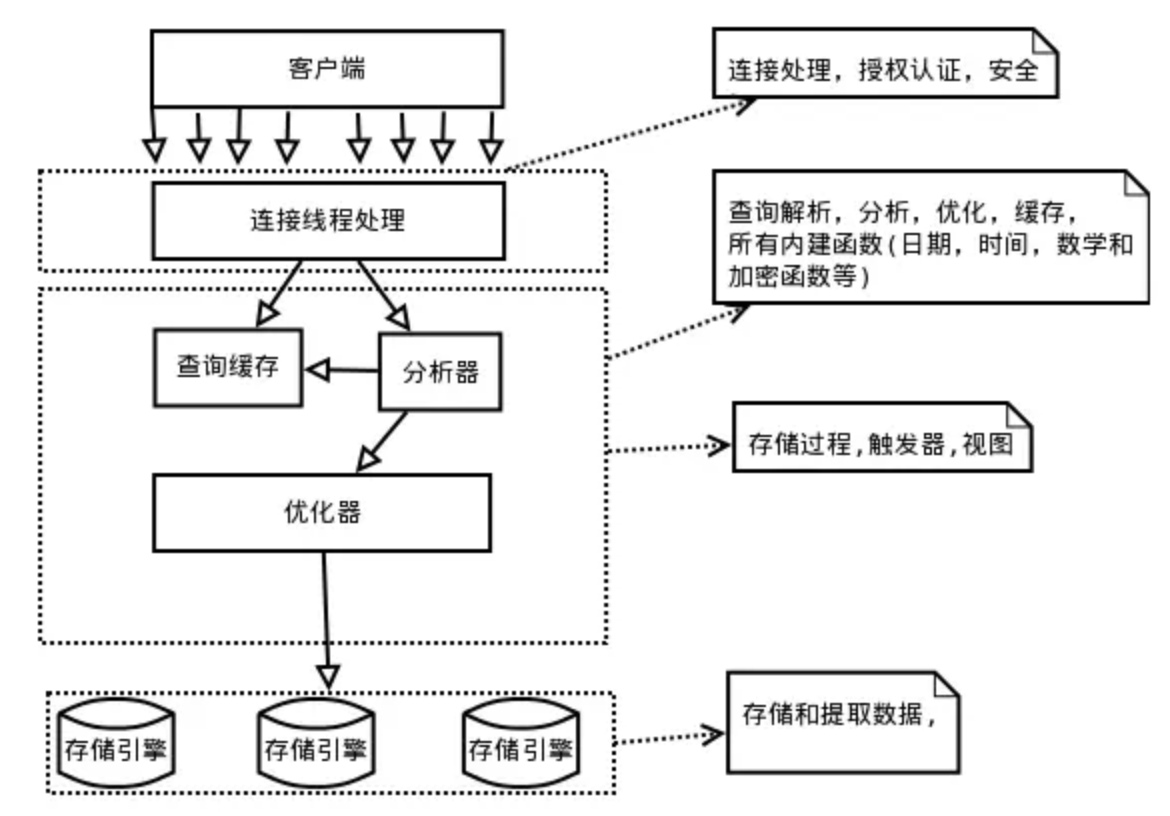
简单来画就是这样:
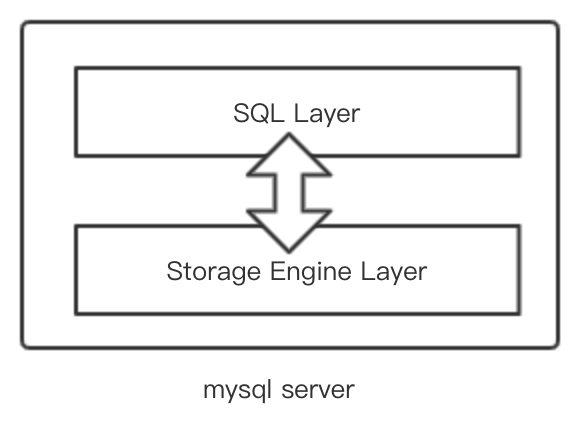
第一层通常叫做SQL Layer,在mysql数据库系统处理底层数据之前的所有工作都在这一层完成的,包括权限判断,sql解析,执行计划优化,
query cache的处理等等。第二层是存储引擎层,通常叫做Storage Engine Layer,是底层数据存取操作实现部分,由多种存储引擎共同组成。
既然我们在说索引,关注的自然是存储层
存储引擎主要关注下Myisam 和 Innodb
查看当前mysql默认引擎: show variables like '%engine%';

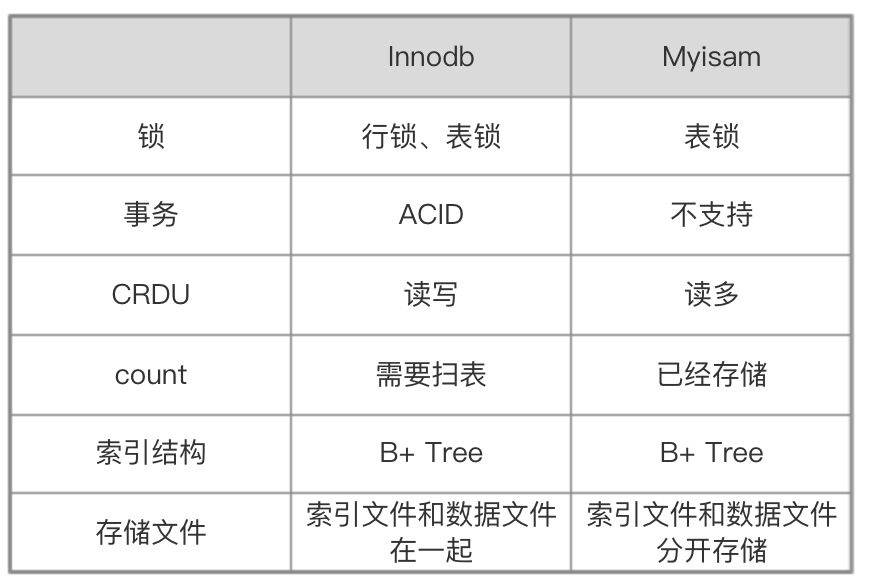
Myisam VS Innodb
区别:
1. InnoDB支持事务,MyISAM不支持,对于InnoDB每一条SQL语言都默认封装成事务,自动提交,这样会影响速度,所以最好把多条SQL语言放在begin和commit之间,组成一个事务;
2. InnoDB支持外键,而MyISAM不支持。对一个包含外键的InnoDB表转为MYISAM会失败;
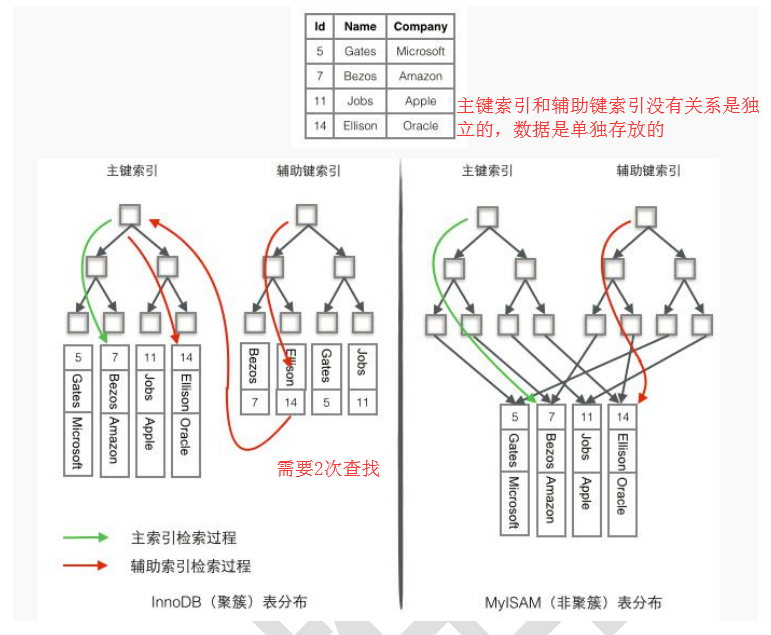
3. InnoDB是聚集索引,数据文件是和索引绑在一起的,必须要有主键,通过主键索引效率很高。但是辅助索引需要两次查询,先查询到主键,然后再通过主键查询到数据。因此,主键不应该过大,因为主键太大,其他索引也都会很大。而MyISAM是非聚集索引,数据文件是分离的,索引保存的是数据文件的指针。主键索引和辅助索引是独立的。
4. InnoDB不保存表的具体行数,执行select count(*) from table时需要全表扫描。而MyISAM用一个变量保存了整个表的行数,执行上述语句时只需要读出该变量即可,速度很快;
5. Innodb不支持全文索引,而MyISAM支持全文索引,查询效率上MyISAM要高;
如何选择:
1. 是否要支持事务,如果要请选择innodb,如果不需要可以考虑MyISAM;
2. 如果表中绝大多数都只是读查询,可以考虑MyISAM,如果既有读写也挺频繁,请使用InnoDB。
3. 系统奔溃后,MyISAM恢复起来更困难,能否接受;
4. MySQL5.5版本开始Innodb已经成为Mysql的默认引擎(之前是MyISAM),说明其优势是有目共睹的,如果你不知道用什么,那就用InnoDB,至少不会差。
关于B+ Tree
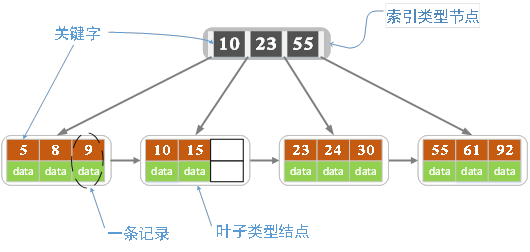
之前面试记得被问到索引为什么不用平衡二叉树、红黑树?
那样查询速度会变慢
B+ Tree 是一个又矮又胖的树形结构
所有的数据都放在了叶子节点
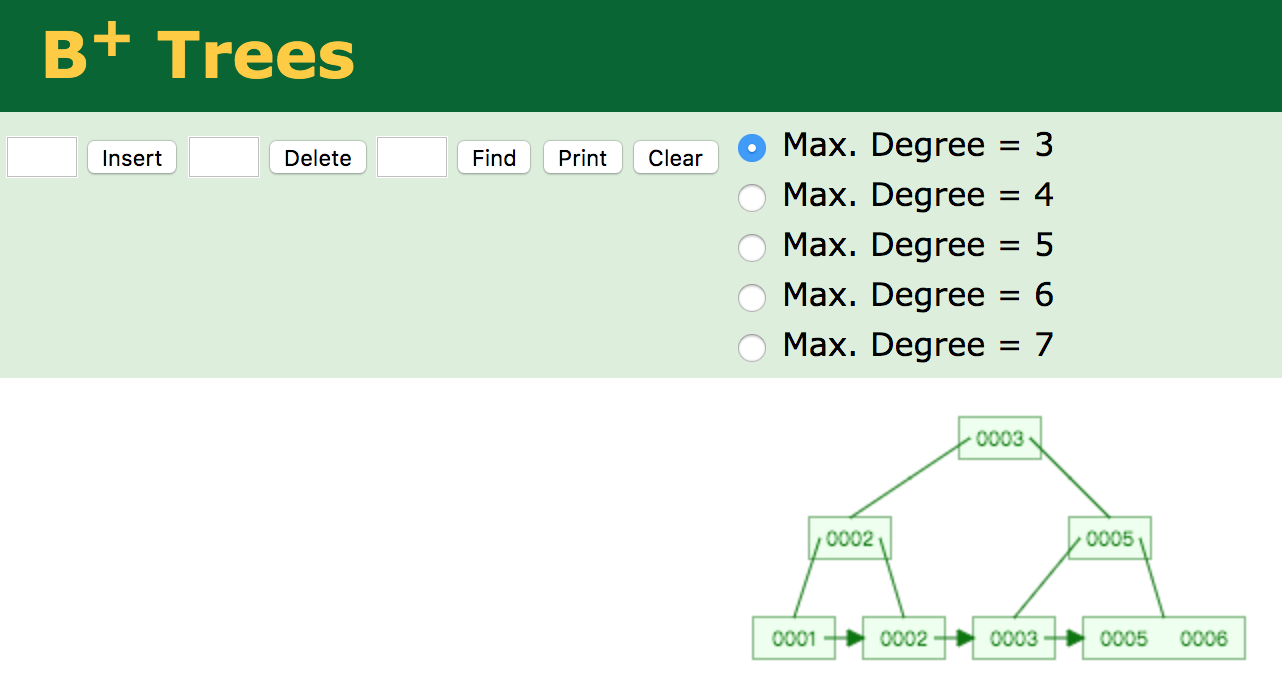
可以直观上感受下B+ 树的插入分裂过程
各种树的对比:
https://zhuanlan.zhihu.com/p/27700617
一种数据结构的出现无非是为了应对不同场景和需求的存储、查询、增删
感觉之后需要针对树的知识做一个深入的调研和学习,并整理笔记和博客
而且数据结构也该捡起来了,发现到了底层都是数据结构的身影
比如redis数据结构的源码好多就很复杂,瞅过2眼
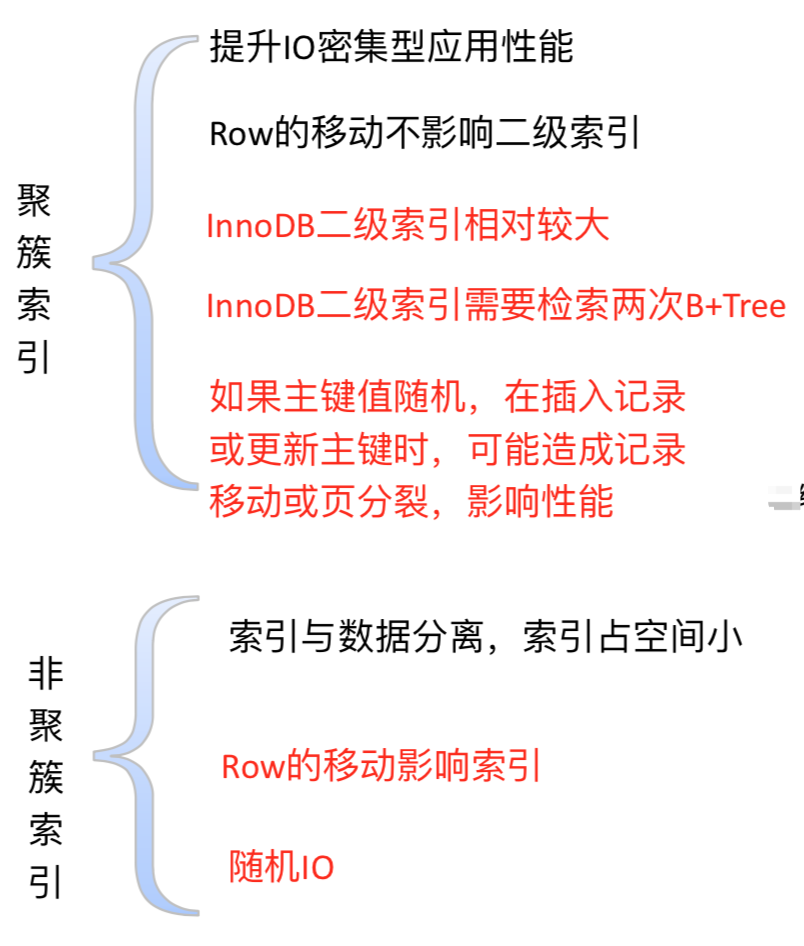
聚集索引 VS 非聚集索引
‣ 聚集(簇)索引:记录的物理存储顺序与索引顺序一致,且索引的叶子节点就是数据节点
‣ 非聚集(簇)索引:记录的物理理存储顺序与索引顺序无关,叶子节点包含索引键值以及指向对应数据块的指针(即指向真正数据的地址)
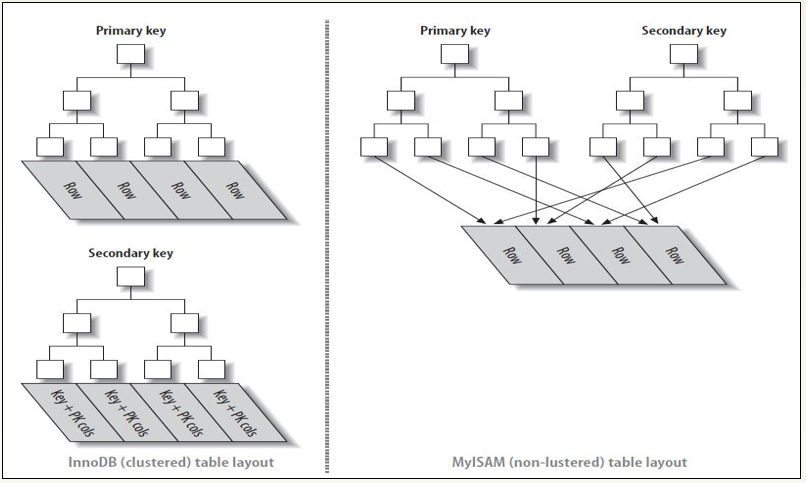
这张图只要是介绍索引的文章都能看到,也画的很直观,充分体现出了innodb和myisam索引的不同以及聚集索引和非聚集索引的不同
如图:左边的是innodb的聚集索引,索引文件和数据文件存储在一起,叶子节点便是整行的数据,如果是辅助索引(图中的secondary key),则需要2次遍历,一次在辅助索引由secondary key找到primary key,再去主键索引找到对应的完整数据。
右边的是myisam的非聚集索引,索引文件和数据文件分开存储,叶子节点存放的是真正数据的地址(而非真正数据)
再贴一个图,帮助我们更好的理解
索引最左前缀匹配
创建了索引,那么索引的命中情况是怎么样的?
explain算是个神器,可以分析SQL的执行计划
对于索引,explain需要关注的几个:
本篇只简单介绍下最左前缀匹配
索引的坑很多,还需要深入的学习
如果在A,B,C三个字段建立联合索引 (A,B,C)
那么A, AB, AC,ABC会命中索引
B,C,BC不会命中索引
再举个例子:
这里有个学生表
CREATE TABLE `student` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`cid` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `name_cid_INX` (`name`,`cid`),
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8
id是主键,(name,cid)是一个联合索引
SELECT * FROM student WHERE cid=1;没有命中索引,违背最左匹配原则
SELECT * FROM student WHERE name='xinye' and cid = 666;显然命中联合索引
SELECT * FROM student WHERE cid = 666 and name='xinye' ;那这样呢?
索引是name,cid顺序,查询条件是cid,name的顺序
能否命中呢?答案是命中索引
mysql查询优化器会判断调整这条sql语句该以什么样的顺序执行效率最高,最后才生成真正的执行计划。
索引设计
- 让尽可能多的查询使用到索引
- 不要在区分度不大的字段建立索引 比如性别
区分度=count(distinct col)/count(*),至少要大于0.1
- 索引数据要小
索引数据太大会导致B+树高度过高,影响性能
- 索引够用即可,不要随意乱建索引
转载请注明:汪明鑫的个人博客 » mysql索引 入门篇



说点什么
您将是第一位评论人!