每创建一个表,就会基于主键建立一个主键索引,就是一个B+树
每多创建一个索引,就会多生成一个索引树
数据和索引就在一起,因此称为聚集(簇)索引
B+的叶子节点才有数据,可以理解非叶子节点都是起到目录作用
主键索引树和普通索引树的区别就是普通索引树叶子节点是包含主键,主键索引的叶子节点包含所有数据
因此利用普通索引查询数据除非查询结果覆盖索引,否则还需要额外的代价回表
随着表数据的新增,主键索引和普通索引逐渐庞大,索引越多,维护的成本就会越大
如果索引设计不合理,对于生产更是灾难性打击
索引的组织是以页为单位,页中会有多行记录,页中的记录是以链表形式组织,当然页与页之间也是链表的形式组织的
数据的新增会导致页的记录存不下了,就会页分裂,申请创建新的空间和页,每个页又有页号的概念
页号并不一定是连续的。
有了数据,自然是需要多级目录,由目录索引 + 叶子结点数据 就是整个庞大的B+树啦
多级目录也是以页位单位的,也会为每个页分配一个页号,不过页中存储的数据是索引项,会存储索引定位到的key,以及向下层能定位到的页号
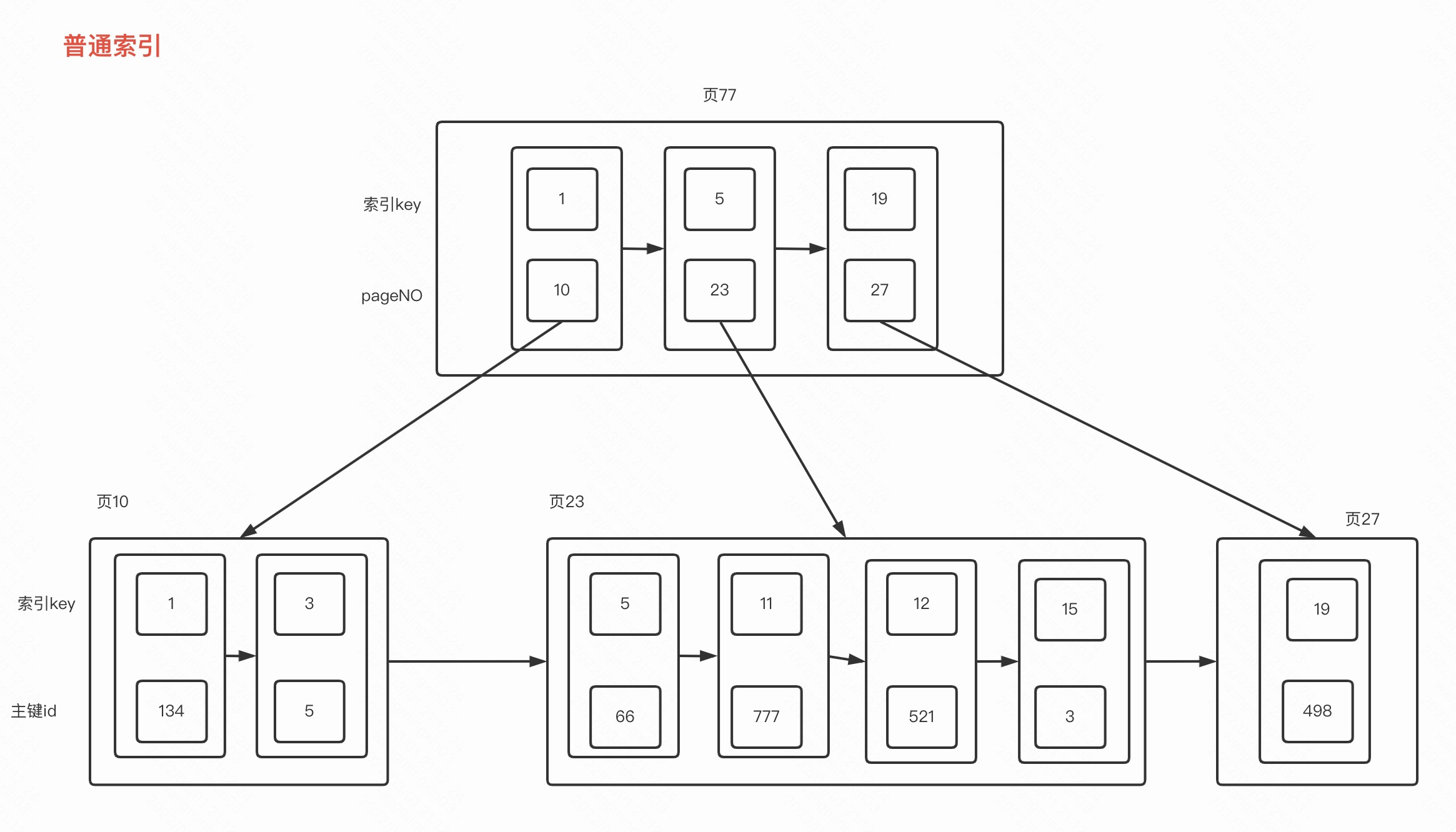
随着数据增多,页分裂更多,目录也会更多,在目录通过基于索引key的二分查找,定位需要向下沉找的页号
然后直到定位到叶子结点所在的页,在页内遍历检索即可。
到这里,Mysql B+树索引大家应该不是很陌生了,说他是索引也行,说他是数据也可
为什么Mysql选择B+树,为什么不用平衡二叉树?
首先mysql是持久化的关系型存储系统,数据是存储在磁盘文件
既然在磁盘文件,我们索引的定位和数据的遍历肯定是需要磁盘io
那我们的优化目标就是减少IO,B+树是个m叉树,相比于平衡二叉树,B+树更矮更胖,层数低,
也意味着只需要有限较少的磁盘IO,就可以定位数据,而且叶子结点的数据都是有序的以链表组织,更方便我们做范围查找。
对于一个 B+ 树来说,m叉树的m 值是根据页的大小事先计算好的,也就是说,每个节点最多只能有 m 个子节点。
在往数据库中写入数据的过程中,这样就有可能使索引中某些节点的子节点个数超过 m,这个节点的大小超过了一个页的大小,就会导致页分裂。
父节点也分裂成两个节点。这种级联反应会从下往上,一直影响到根节点。
转载请注明:汪明鑫的个人博客 » 正确理解Mysql索引




说点什么
您将是第一位评论人!