目录
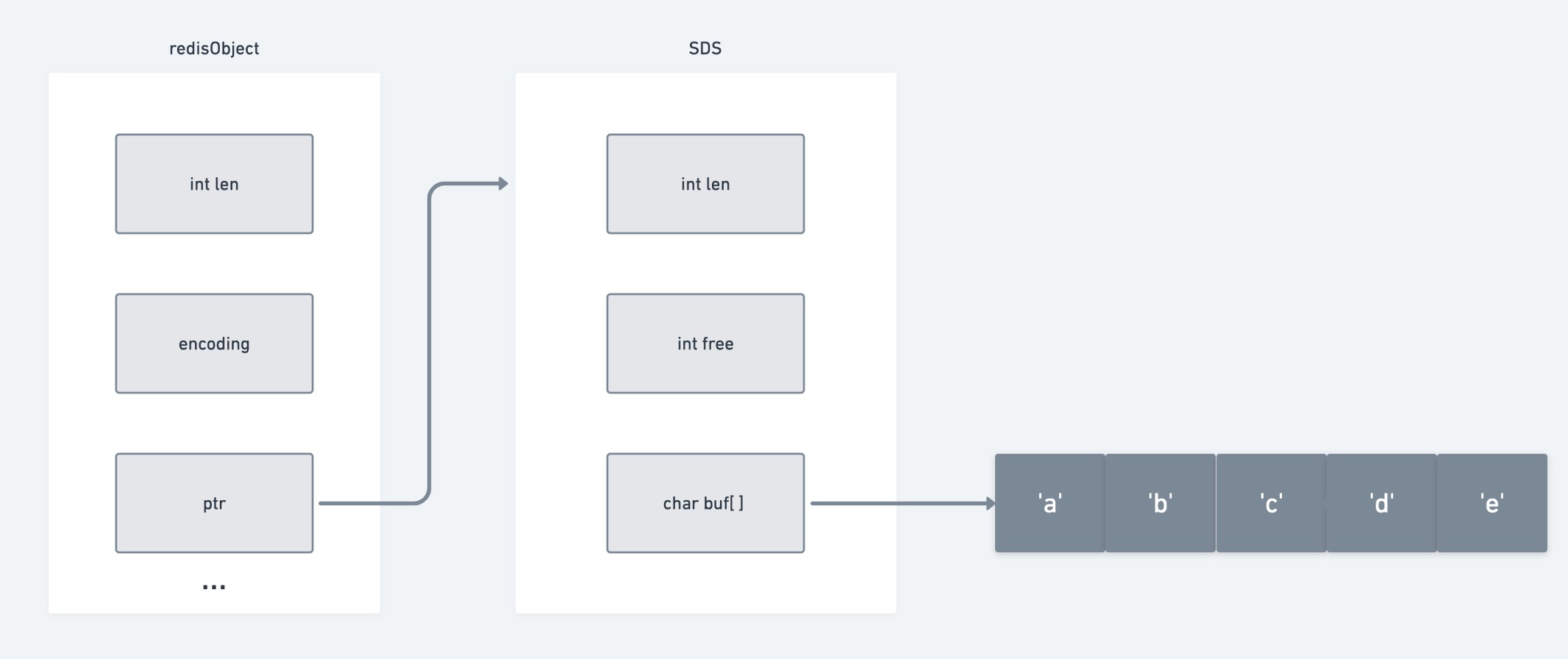
redisObject
创建一个键值对时,至少需要常见2个对象,一个对象用作键对象,一个对象用作值对象
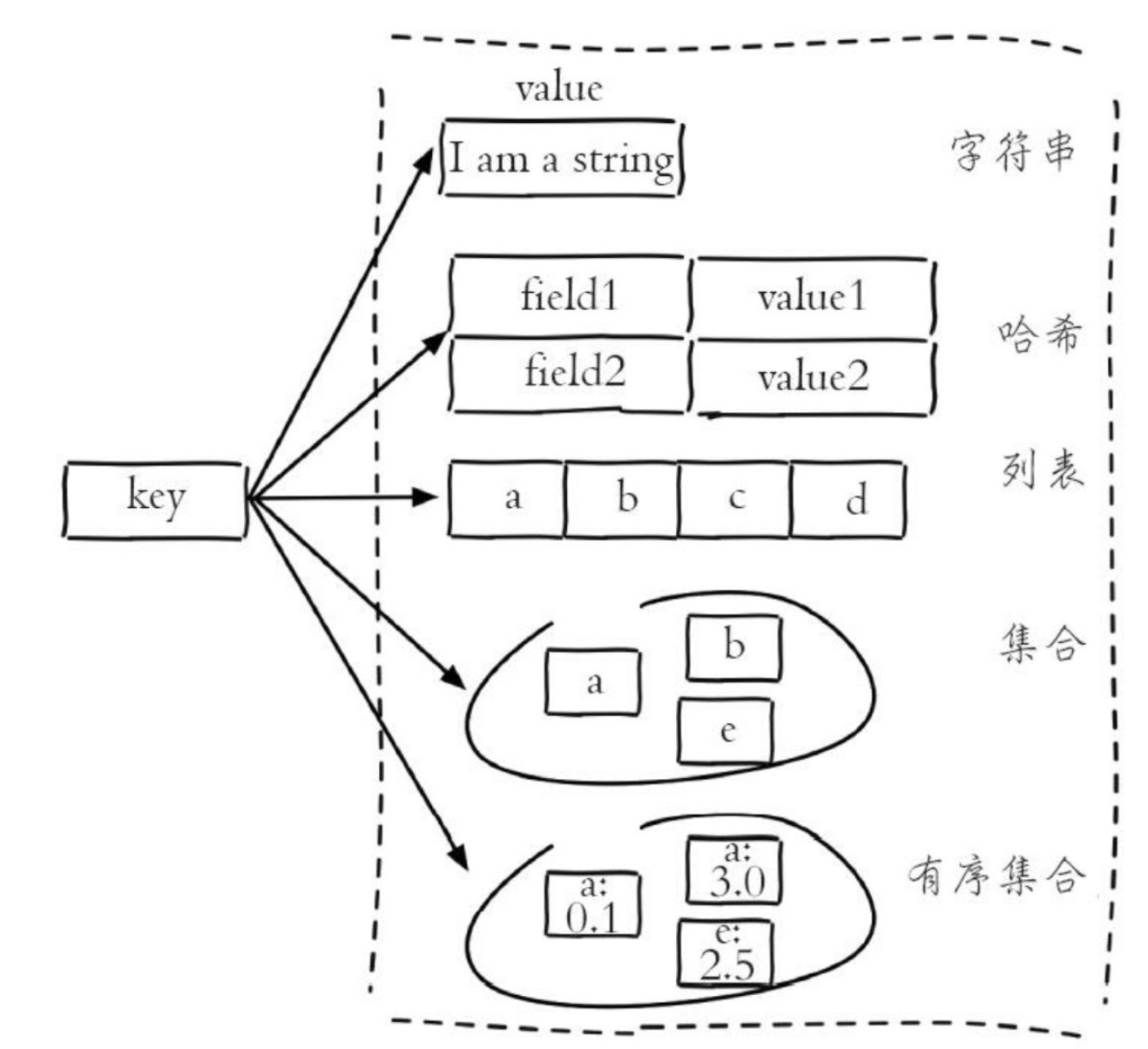
每个对象都由redisObject表示,Redis存储的数据都使用redisObject来封装
typedef struct redisObject {
// 类型
unsigned type:4;
// 编码
unsigned encoding:4;
// 对象最后一次被访问的时间
unsigned lru:REDIS_LRU_BITS; /* lru time (relative to server.lruclock) */
// 引用计数
int refcount;
// 指向实际值的指针
void *ptr;
} robj;
可以使用type key命令查看对象所属类型,type命令返回的是值对象类型,键都是string类型
type主要包含5种:string、hash、list、set、zset
127.0.0.1:6668> set msg "hello world"
OK
127.0.0.1:6668> type msg
string
127.0.0.1:6668>
127.0.0.1:6668> rpush numbers 1 3 5
(integer) 3
127.0.0.1:6668> type numbers
list
127.0.0.1:6668> hset user1 name xinye age 23
(error) ERR wrong number of arguments for 'hset' command
127.0.0.1:6668> hmset user1 name xinye age 23
OK
127.0.0.1:6668> type user1
hash
127.0.0.1:6668> sadd fruits apple banana
(integer) 2
127.0.0.1:6668> type fruits
set
127.0.0.1:6668> zadd rank 1000 faker 900 uzi
(integer) 2
127.0.0.1:6668> type rank
zset
encoding 我们在下一段主要介绍
lru记录对象最后一次被访问的时间
refcount 记录当前对象被引用的次数,用于通过引用次数回收内存,当refcount=0时,可以安全回收当前对象空间
*ptr 指向对象的底层实现数据结构
数据结构编码方式
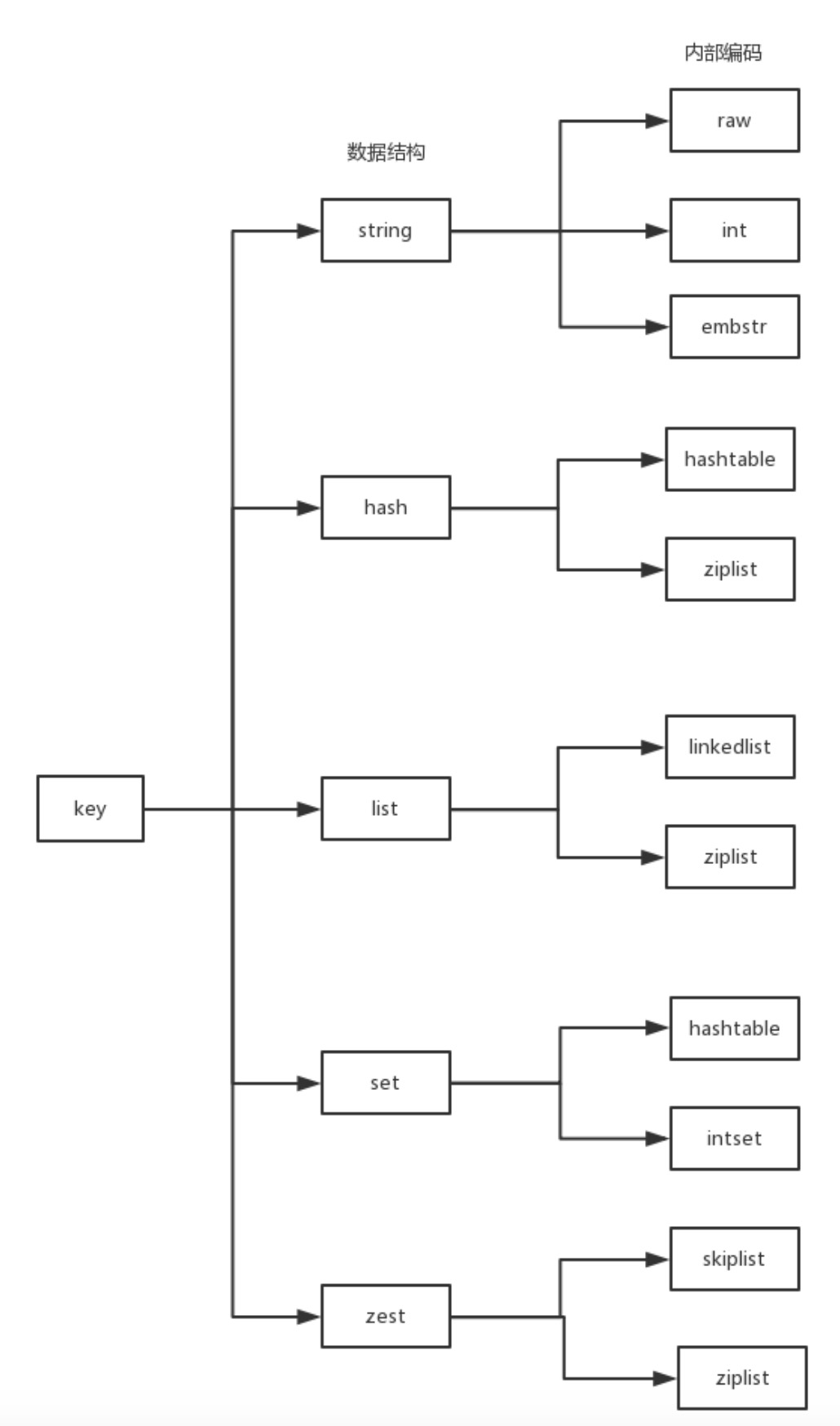
Redis对外提供了string,list,hash,set,zet等类型,但是Redis内部针对不同类型存在编码的概念,
编码就是具体使用哪种底层数据结构来实现。
同一个对象采用不同的编码实现内存占用存在明显差异。
127.0.0.1:6668> set str 1234567
OK
127.0.0.1:6668> object encoding str
"int"
127.0.0.1:6668> object encoding msg
"embstr"embstr 编码的简单动态字符串 SDS
127.0.0.1:6668> set story "long long long long long long ago ..."
OK
127.0.0.1:6668> object encoding story
"embstr"
127.0.0.1:6668> set story "long long long long long long ago ........................................."
OK
127.0.0.1:6668> object encoding story
"raw"
上图中少了一个quicklist
127.0.0.1:6668> object encoding numbers
"quicklist"
ziplist编码主要目的是为了节约内存,因此所有数据都是采用线性连续的内存结构。
ziplist编码是应用范围最广的一种,可以分别作为hash、list、zset类型的底层数据结构实现
Redis为什么需要对一种数据结构实现多种编码方式?
主要原因是Redis作者想通过不同编码实现效率和空间的平衡。比如当我们的存储只有10个元素的列表,当使用双向链表数据结构时,必然需要维护大量的内部字段如每个元素需要:前置指针,后置指针,数据指针等,造成空间浪费,如果采用连续内存结构的压缩列表(ziplist),将会节省大量内存,而由于数据长度较小,存取操作时间复杂度即使为O(n2)性能也可满足需求。
简单动态字符串
Simple Dynamic String
简称SDS
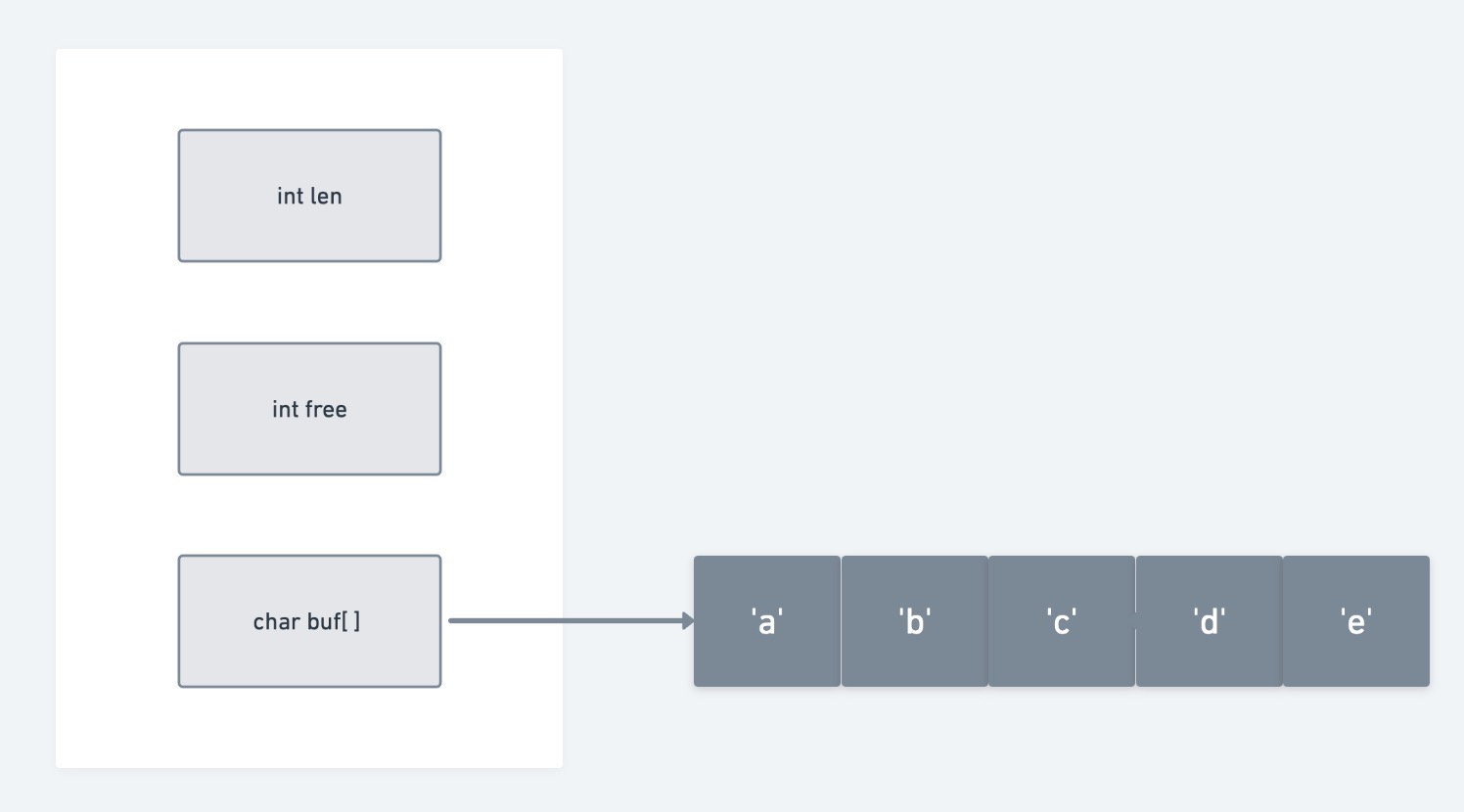
len 记录buf数组已使用字节数量(保存字符串长度)
free 记录buf数组中未使用字节数量
- O(1)时间复杂度获取:字符串长度,已用长度,未用长度。
- 可用于保存字节数组,支持安全的二进制数据存储。
- 内部实现空间预分配机制,降低内存再分配次数。
- 惰性删除机制,字符串缩减后的空间不释放,作为预分配空间保留。
【字符串对象】
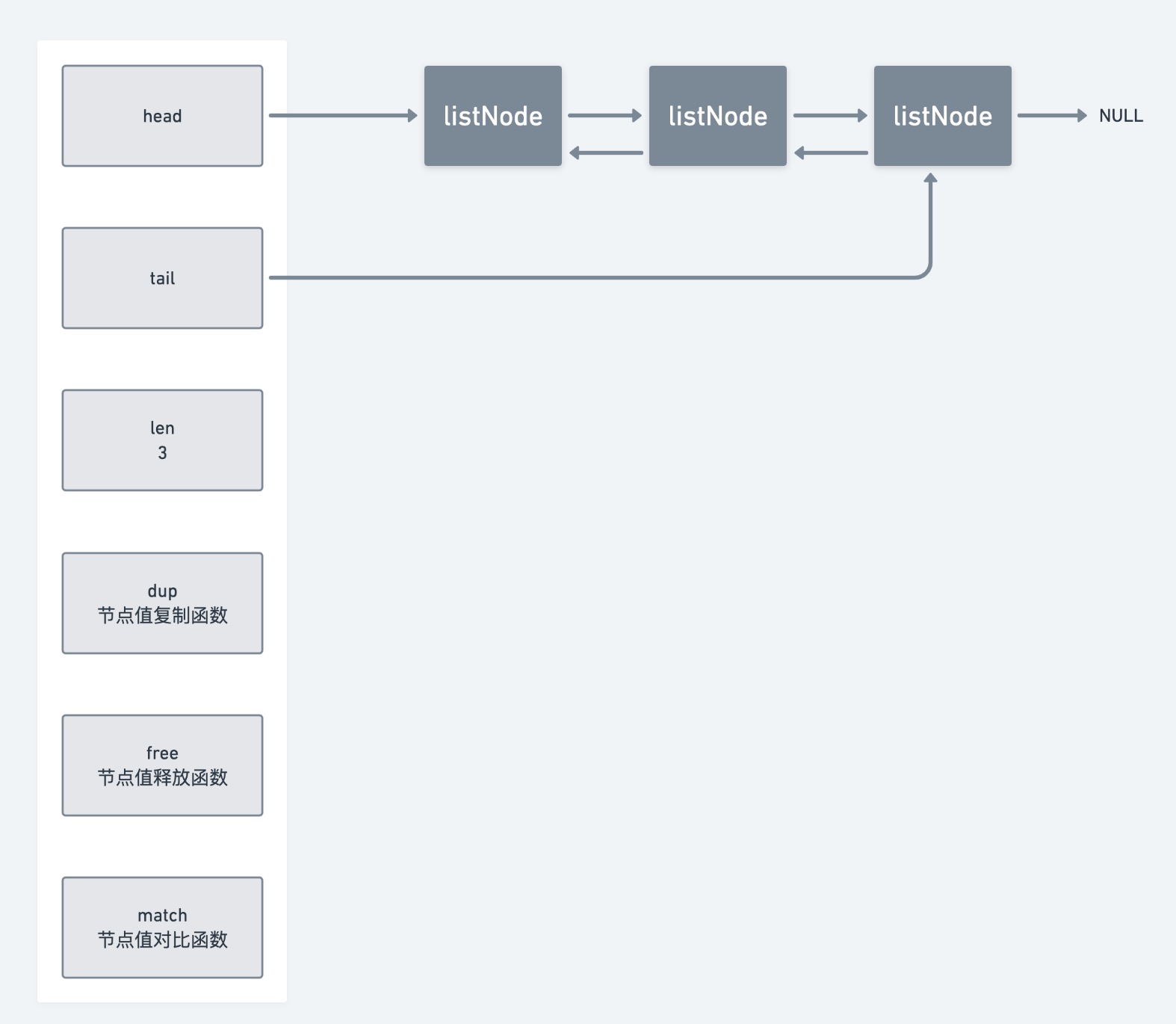
链表
redis实现的是双向链表
且持有头节点和尾节点的指针
字典
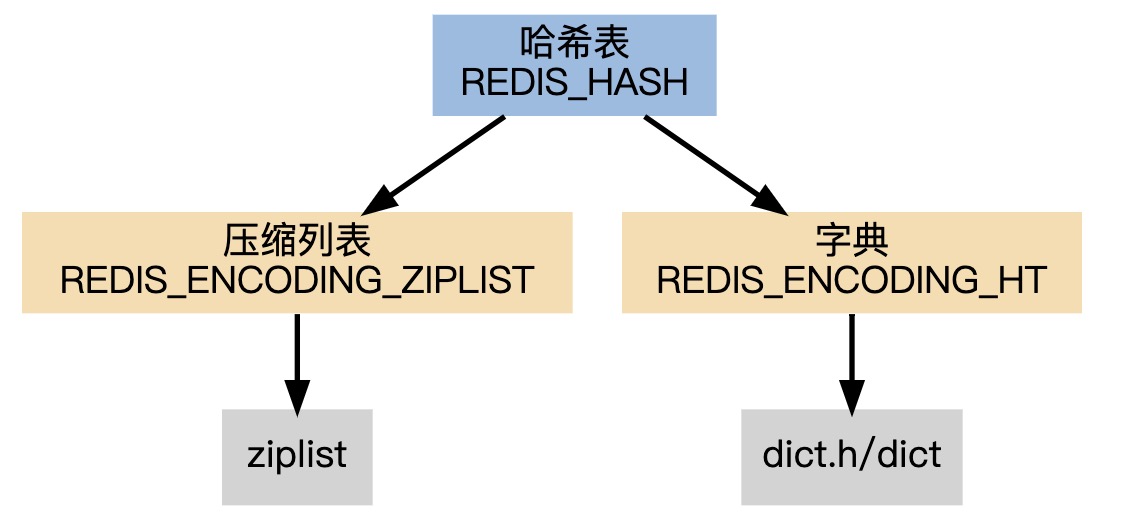
用ziplist编码时, 程序将键和值一同推入压缩列表
+---------+------+------+------+------+------+------+------+------+---------+
| ZIPLIST | | | | | | | | | ZIPLIST |
| ENTRY | key1 | val1 | key2 | val2 | ... | ... | keyN | valN | ENTRY |
| HEAD | | | | | | | | | END |
+---------+------+------+------+------+------+------+------+------+---------+
下面我们来看下字典的具体实现
/*
* 字典
*
* 每个字典使用两个哈希表,用于实现渐进式 rehash
*/
typedef struct dict {
// 特定于类型的处理函数
dictType *type;
// 类型处理函数的私有数据
void *privdata;
// 哈希表(2 个)
dictht ht[2];
// 记录 rehash 进度的标志,值为 -1 表示 rehash 未进行
int rehashidx;
// 当前正在运作的安全迭代器数量
int iterators;
} dict;
本文我们主要关心这个dictht ht[2]
为什么需要2个dictht 即哈希表,
每个字典带2个哈希表,一个平时使用,另一个仅在rehash时使用
然后我们来看一下dictht
/*
* 哈希表
*/
typedef struct dictht {
// 哈希表节点指针数组(俗称桶,bucket)
dictEntry **table;
// 指针数组的大小
unsigned long size;
// 指针数组的长度掩码,用于计算索引值
unsigned long sizemask;
// 哈希表现有的节点数量
unsigned long used;
} dictht;
table 属性是个数组, 数组的每个元素都是个指向 dictEntry 结构的指针。
然后再来看下这个 dictEntry **table
/*
* 哈希表节点
*/
typedef struct dictEntry {
// 键
void *key;
// 值
union {
void *val;
uint64_t u64;
int64_t s64;
} v;
// 链往后继节点
struct dictEntry *next;
} dictEntry;
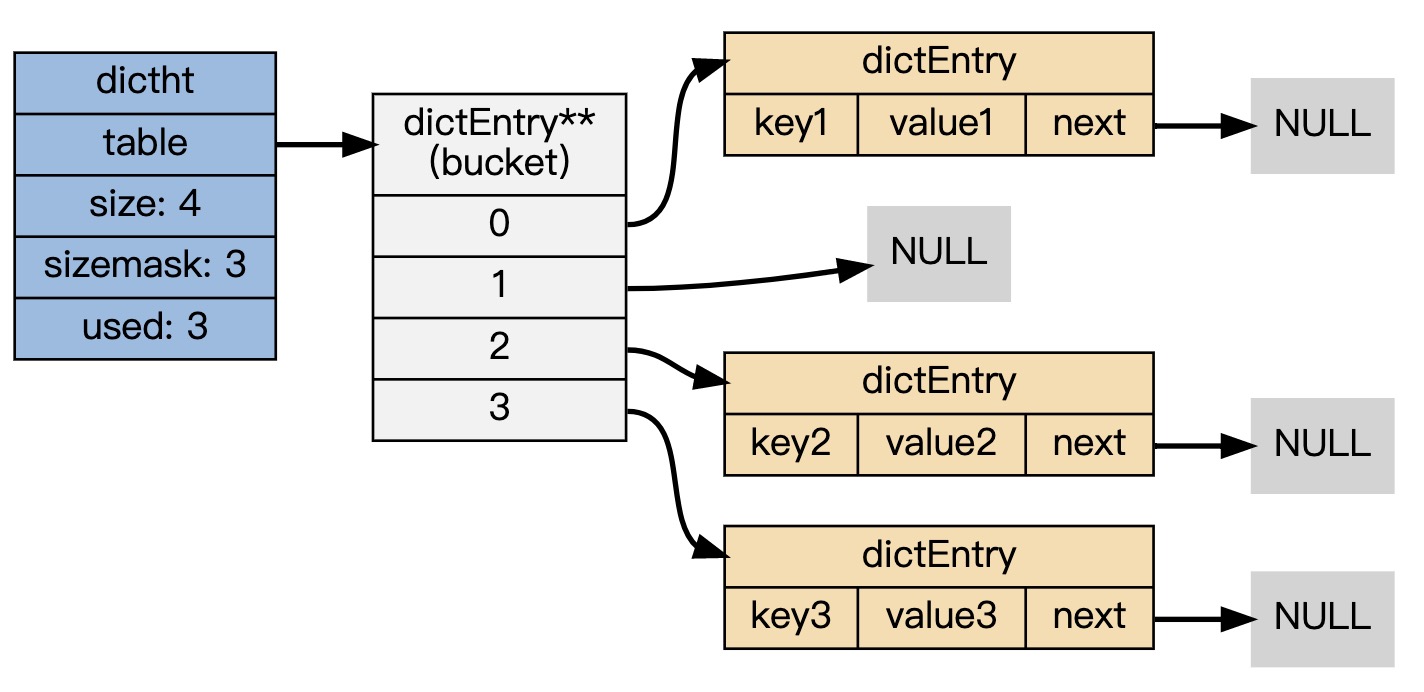
结构大概是这样
使用链地址法解决冲突
对于冲突的解决我们看下图的示例
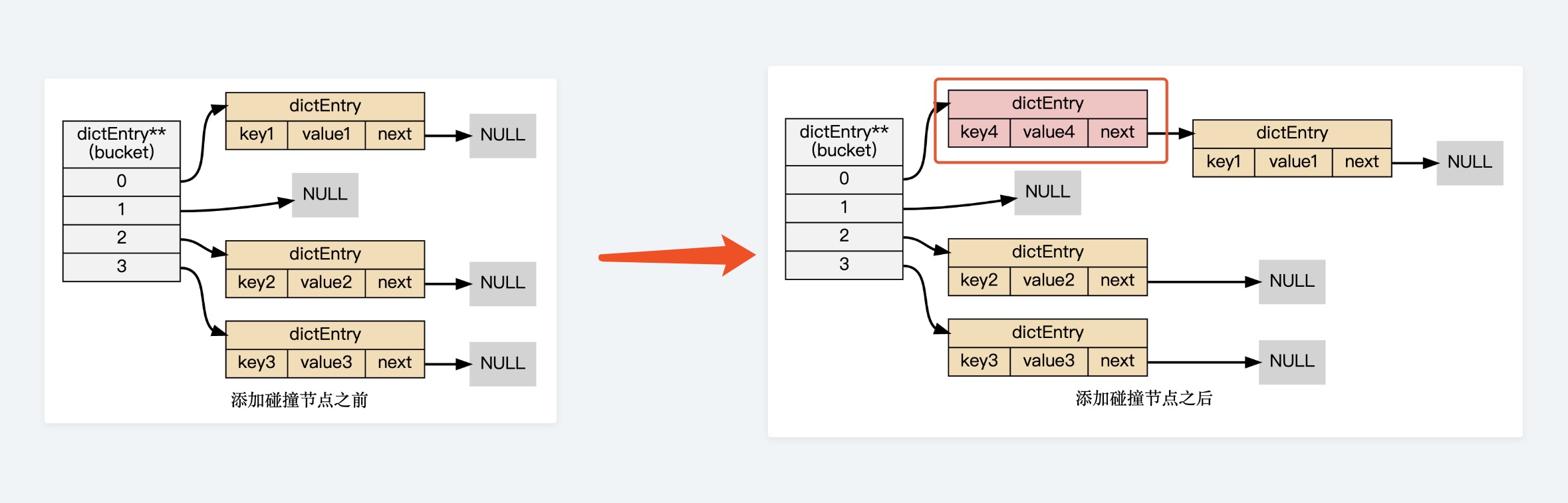
整体来看dict
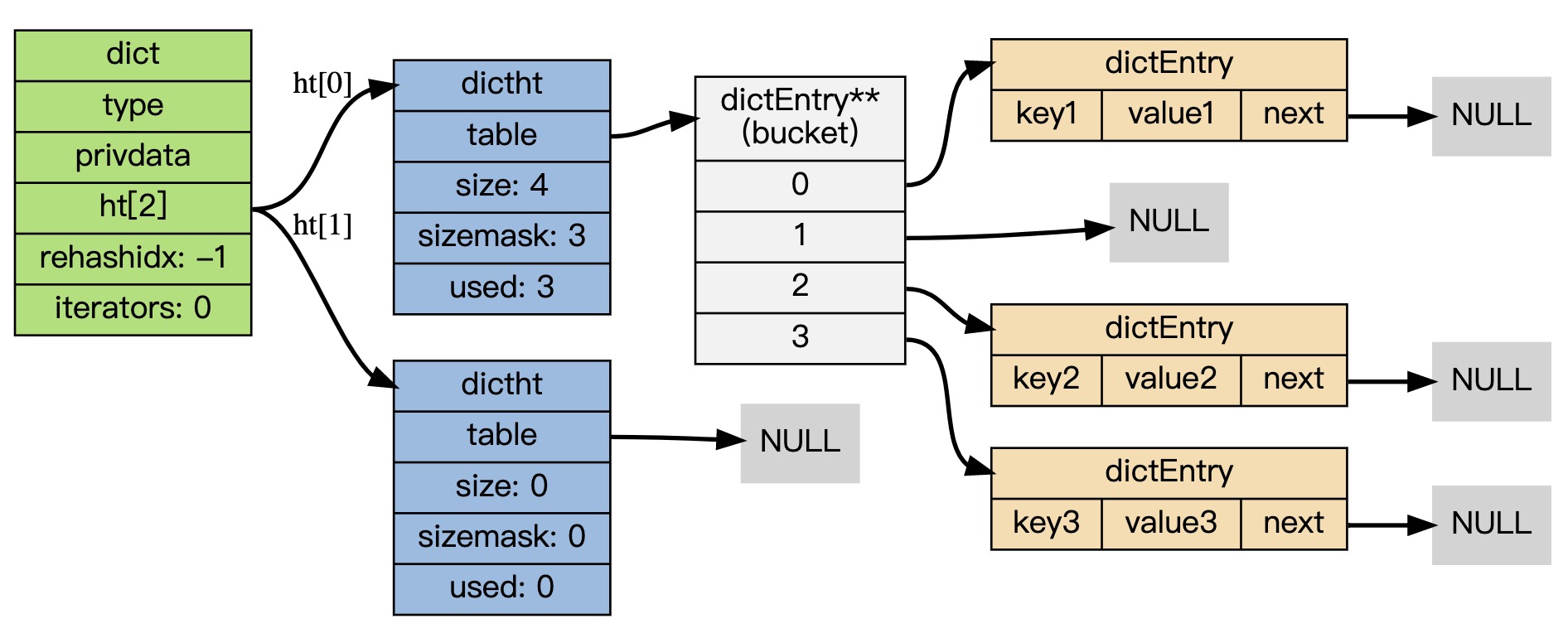
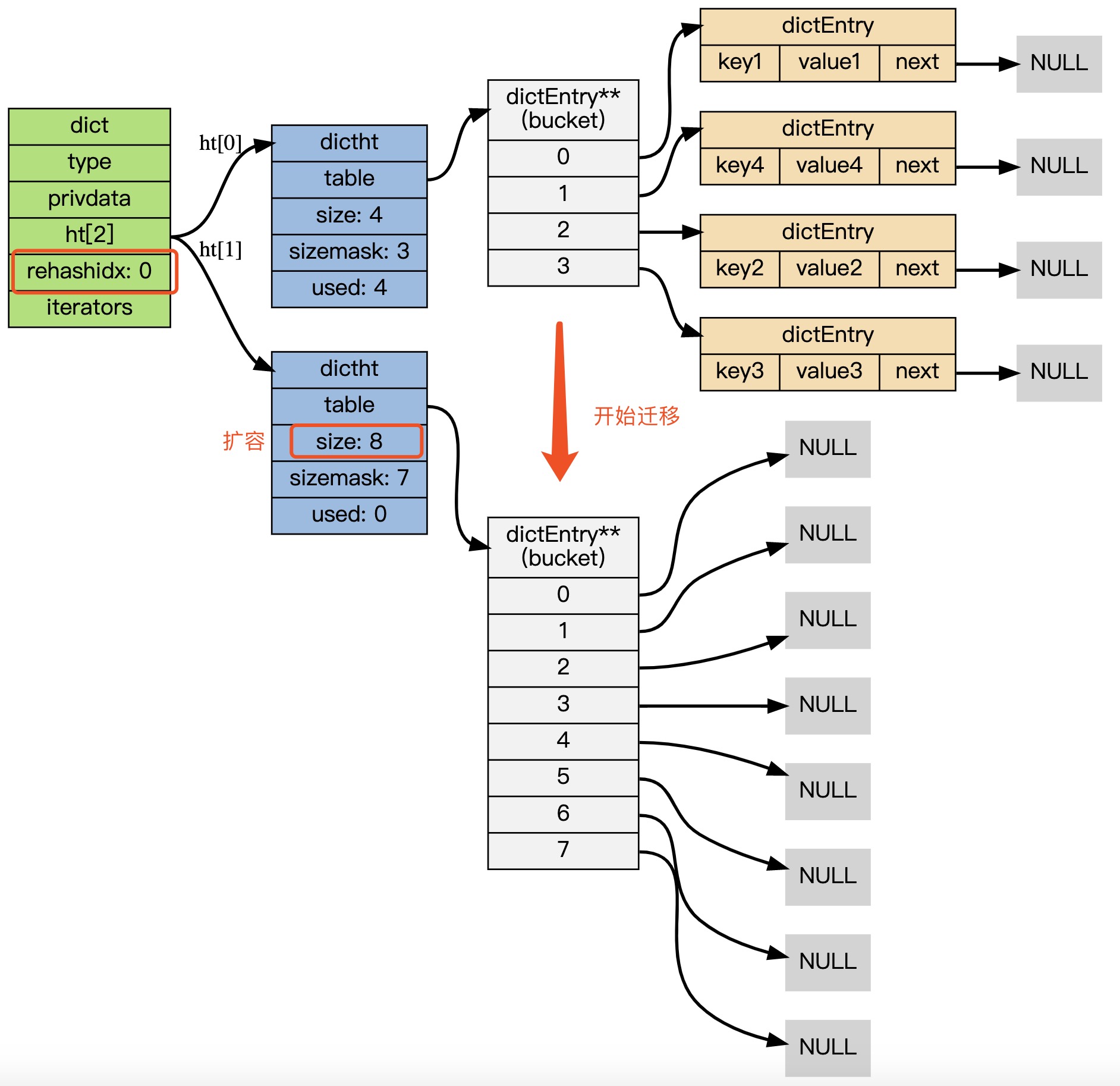
触发rehash和Java中HashMap类似,也是有负载因子的概念
rehash时会把ht[0] rehash到 扩容后的ht[1]新哈希表里,rehash的过程时渐进的
会同时使用ht[0] 、ht[1]
设置字典的 rehashidx 为 0,标识着 rehash 的开始,并从ht[0] 的索引0位置开始
ht[0]->table 的节点会被逐渐迁移到 ht[1]->table , 因为 rehash 是分多次进行的
rehashidx 变量会记录 rehash 进行到 ht[0] 的哪个索引位置上
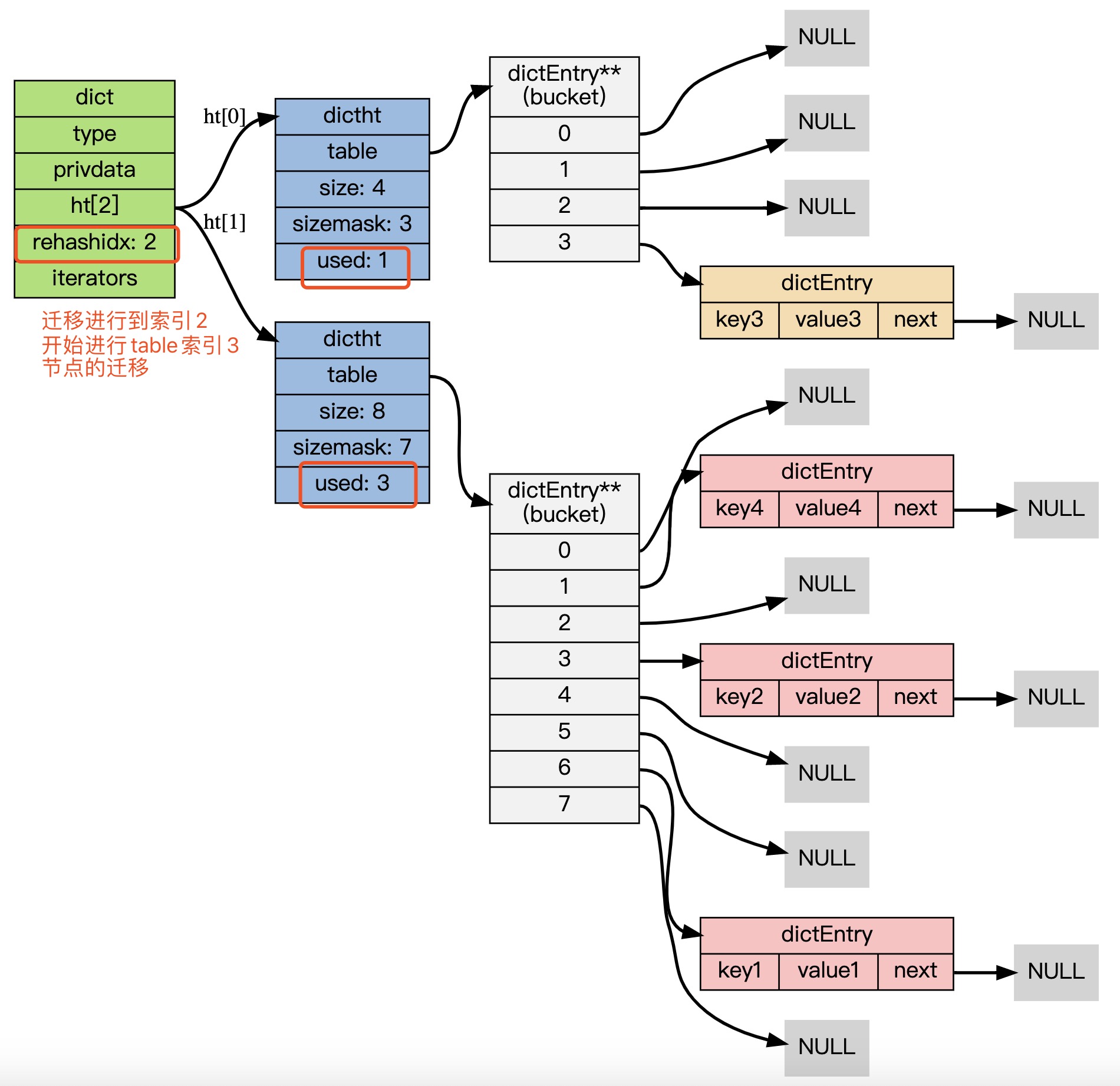
最终节点迁移完毕后:
- 释放
ht[0]的空间; - 用
ht[1]来代替ht[0],使原来的ht[1]成为新的ht[0]; - 创建一个新的空哈希表,并将它设置为
ht[1]; - 将字典的
rehashidx属性设置为-1,标识 rehash 已停止
跳跃表
当元素个数增多或有较大的元素值时,ziplist的读写效率下降
编码方式升级为skiplist,即跳跃表
跳跃表 相比于其他链表效率更高,且具有特有的排序功能
跳跃表的效率可以媲美平衡树,非常给力
面试题也经常爱问zset的底层存储和跳跃表的相关操作时间复杂度
我们先看一下redis 跳跃表结构的实现
typedef struct zskiplist {
// 头节点,尾节点
struct zskiplistNode *header, *tail;
// 节点数量
unsigned long length;
// 目前表内节点的最大层数
int level;
} zskiplist;
头节点、尾节点不用说,主要需要关注这个 level
再来看下zskiplistNode
typedef struct zskiplistNode {
// 成员对象
robj *obj;
// 分值
double score;
// 后退指针
struct zskiplistNode *backward;
// 层
struct zskiplistLevel {
// 前进指针
struct zskiplistNode *forward;
// 这个层跨越的节点数量
unsigned int span;
} level[];
} zskiplistNode;
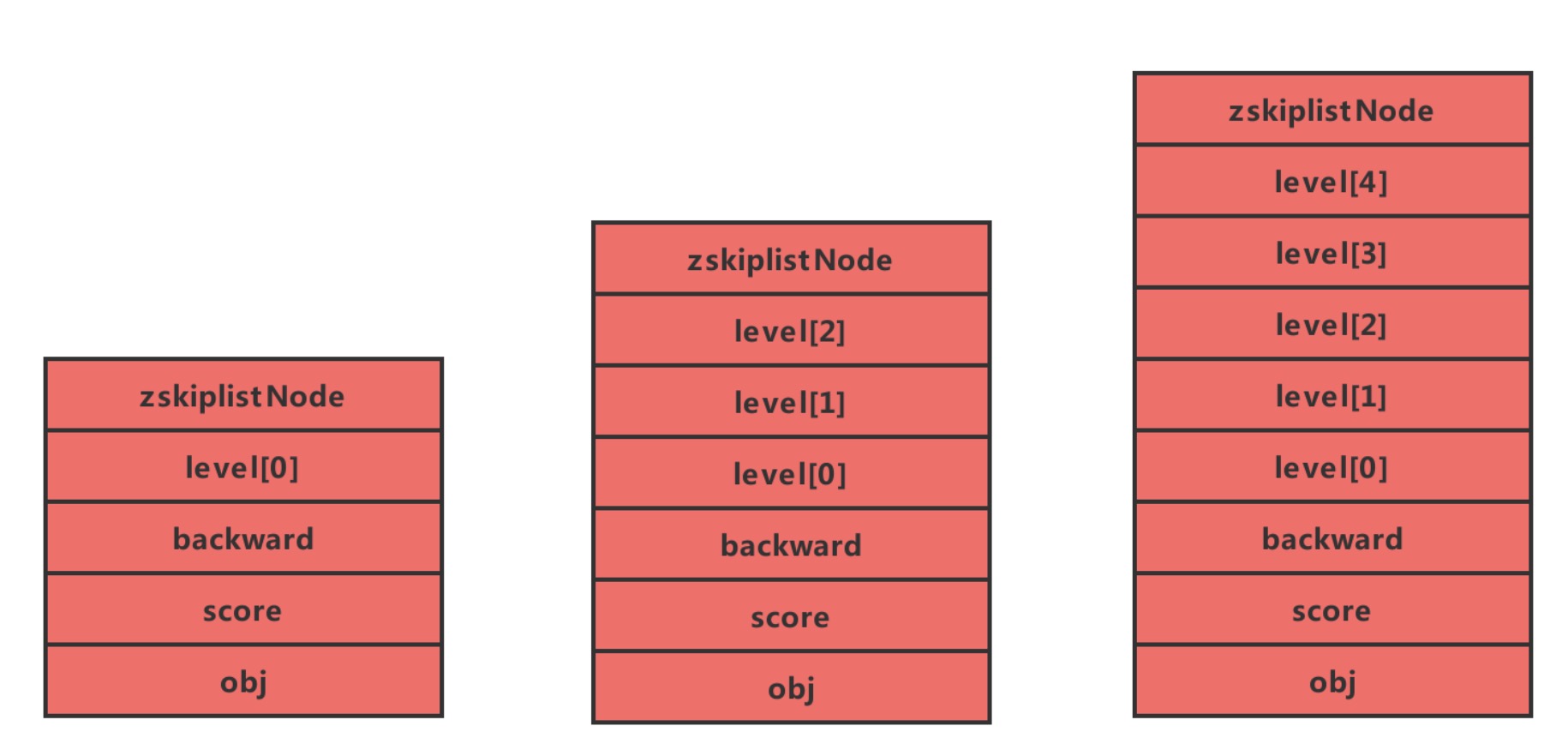
这个还是很复杂,比较恶心的
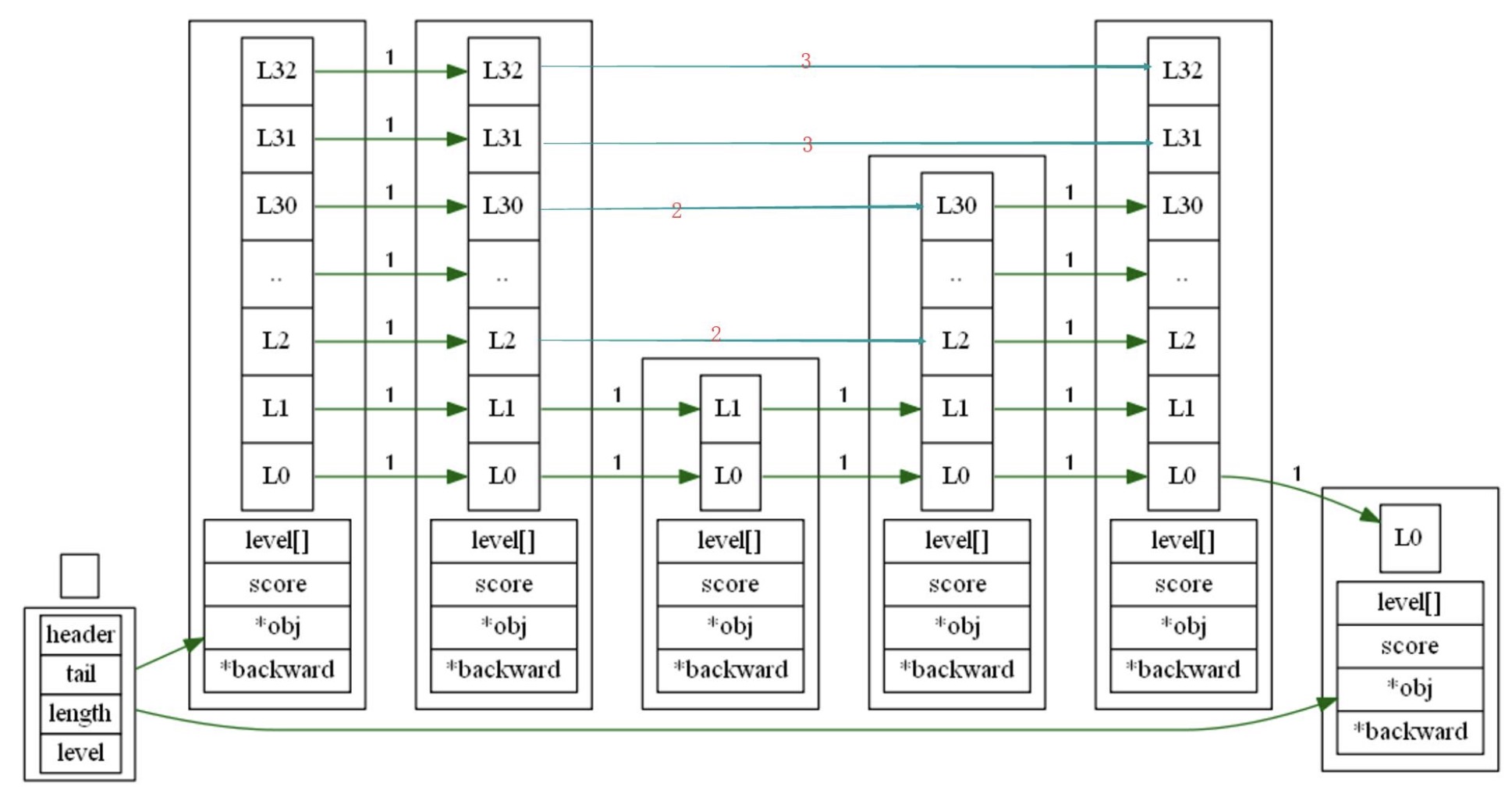
整体结构大概是这个样子
zskiplist 保存跳跃表信息
zskiplistNode 跳跃表节点
每个跳跃表节点的层高都是1~32的随机数
跳跃表中的节点按照分值大小排序,分值相同按照成员对象大小排序
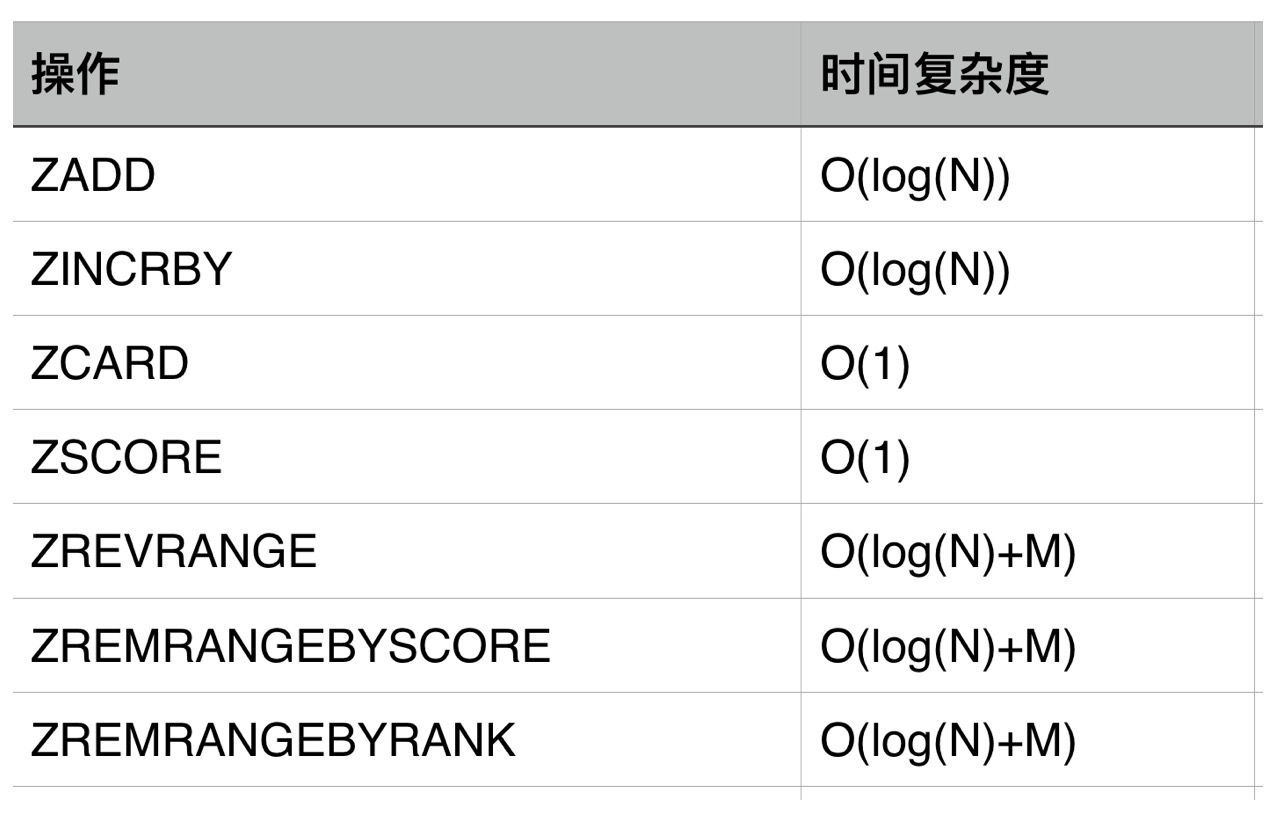
时间复杂度:

对应一些命令
最后需要提一下的是 skiplist编码的有序集合对象使用zset作为底层,同时包含一个跳跃表和一个字典
typedef struct zset {
zskiplist *zsl;
dict *dict;
} zset;
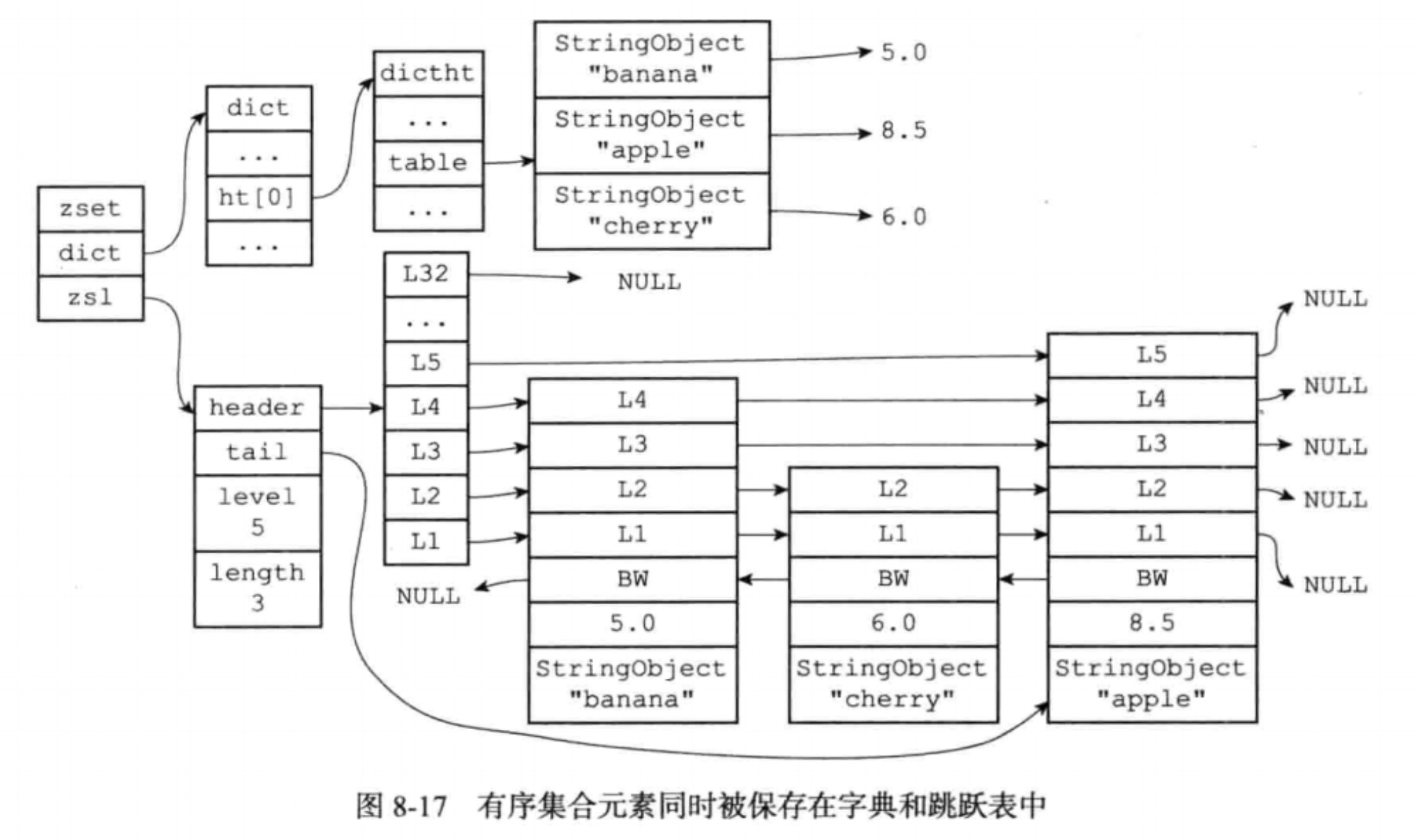
为什么有序集合需要同时使用跳跃表和字典来实现?
跳跃表利于执行范围操作(跳跃表是排好序的),而字典有利于指定成员对象分值查找操作
参考
经典书籍:
《Redis设计与实现》
学习资料:
https://www.cnblogs.com/yangmingxianshen/p/8054094.html
https://redisbook.readthedocs.io/en/latest/datatype/hash.html#hash-chapter
https://redisbook.readthedocs.io/en/latest/internal-datastruct/dict.html
跳表的思想可以看下文:
https://zhuanlan.zhihu.com/p/53975333
转载请注明:汪明鑫的个人博客 » Redis数据结构浅析


说点什么
您将是第一位评论人!