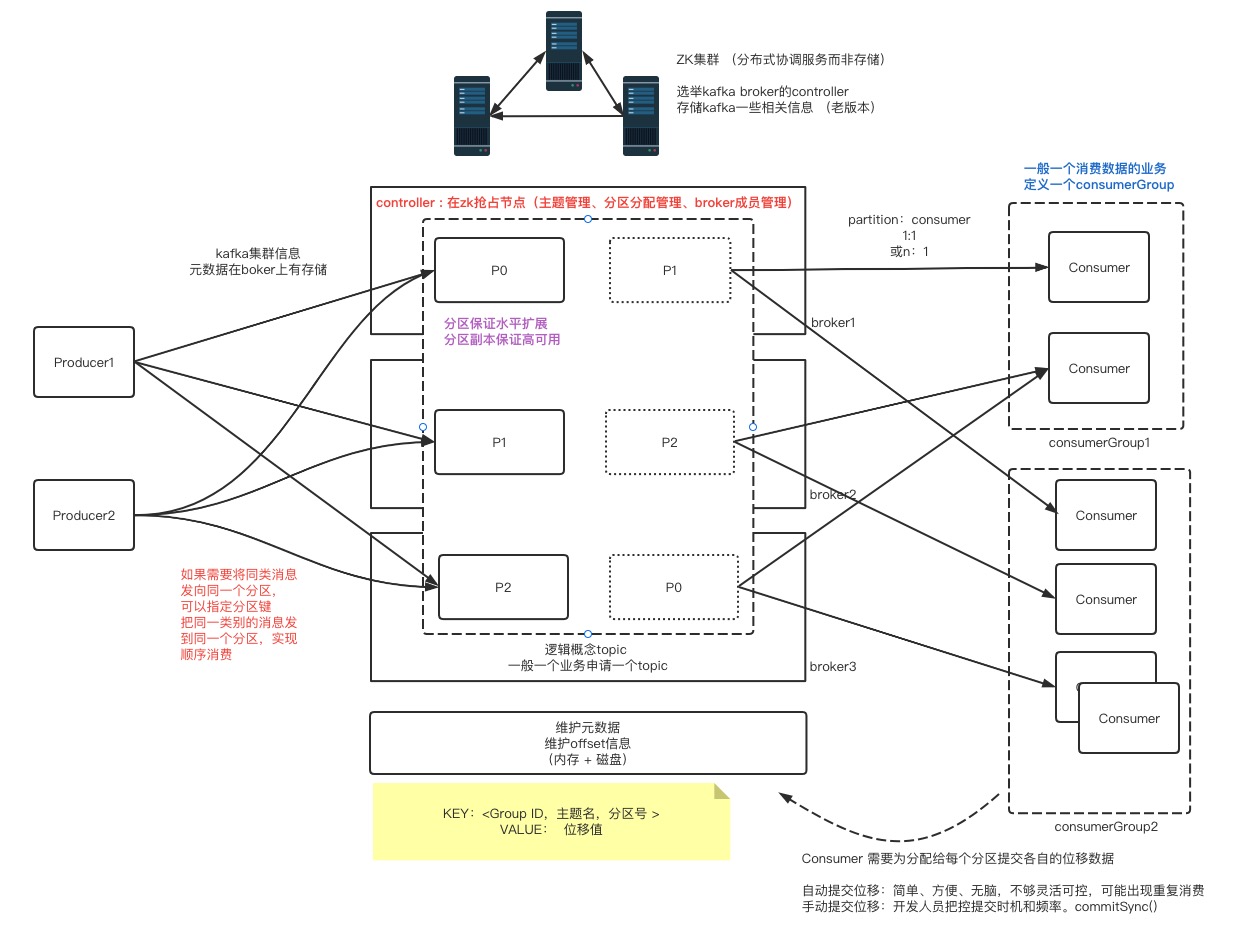
先贴上我精心制作的kafka架构图
然后开始用大白话去聊聊我眼里的Kafka
首先介绍的是kafka 外部依赖的 分布式协调服务Zookeeper,大家一般简称ZK
协调服务顾名思义做调解员的,那么kafka需要协调什么呢?
当然是协调broker成员,kafka集群是由多个broker组成,怎么协调,去从众多broker中选一个老大,而老大我们一般称Controller
争抢老大的过程就是抢占ZK中指定path节点的创建,谁抢先一步创建成功谁就是老大
Controller负责主题的管理,分区重分配、成员管理等,存储了所有broker、broker所有分区、分区副本信息等。
之前老版本Kafka集群的一些信息很多都存储ZK上,对ZK负担过重,新版本大多都存储在broker本身。
Topic是broker上的逻辑概念,目的是为了给所有存储在Kafka上的消息打上一个标,消费者需要什么数据,就消费指定的Topic。
Partition就是Topic下的物理概念,消息是真是存储在Partition下的,partition的意义就是水平扩展,可以根据业务场景评估需要多少个partition,
那么partition目的是扩展,partition的副本的目的就是可用性。
分布式系统都是这个尿性,扩展去抗高并发、达到系统高吞吐,备份、冗杂达到高可用。
其实,简单理解Kafka就是一个存储系统。
那么下面我们来聊下消息生产者Producer,
首先Producer需要从broker拉集群的信息,把产生的消息投递到partition中存储,消息按照offset排序存储。
如果需要把同一类型的消息(如同一订单产生的消息)投递到同一分区,需要在生产处指定消息的分区键即可,
保证同一类型的消息投递到一个分区,然后实现顺序消费,美滋滋。
有了消息的生产方Producer和消息的存储方Broker,最后聊下消息消费者Consumer,看看消费者又有什么骚操作。
首先消费者需要指定要消费消息的标识,即主题Topic。
部一个消费者可以不,完全ojbk, 但为了提升消息的消费速度,我们一般部署多个消费者,
然后大家思考一个问题,多个消费者是怎么去消费多个partition的?
如果一对一是不是比较完美,一个partition由一个consumer消费,
如果是多对一呢,刚才我们说了多个partion由一个consumer消费也完全可以,只不过consumer比较累而已,消费速度可能跟不上。
那么上杀招,一个partition能否有多个consumer消费,如果kafka允许这样搞的话,是不是就存在竞争资源的行为,
消息是offset存储的,consumer1和consumer2 如果同时消费到 offset 10,那么谁去消费offset 10呢,如果都去消费是不是就重复消费了?
如果仅允许一个consumer消费,是不是还要额外做一些锁的逻辑甚至需要牵连其他更复杂的处理。
因此Kafka是不允许consumer个数多于partition个数的,多了的话,多余的consumer产生冷备,就是不用他了,
所以这里大家要避免进入误区,不要认为消费者就要部署的越多越好。
实际上,一般partition个数 : consumer个数 = m:n (m略大于n),consumer个数略小于partition个数,
目的是让一些consumer多消费partition,充分压榨机器的性能。
再引入一个消费组的概念,意思是消息可能被多个系统所消费,每来一个系统消费消息,就新定义一个消费组ConsumerGroup,
不同消费者组之间消费消息消息和消费进度是隔离开的,互不影响。
需要记录消费者是如何分配分区的,
需要记录每个消费者组在每partition上的消费进度offset, key 就是 <groupId, topic, partition>,
可能有朋友这里犯嘀咕,为啥消费进度只有groupId,没有带上具体哪个消费者呢?
当然不需要,我们只需要记录这个group的消费进度,具体哪个consumer来消费不用care,
我知道这个group消费了就行,下次该从哪里消费,具体由哪个consumer来消费,再分区分配时已经确定了
退一万步来讲,如果我们offset的key时这样记录的<groupId, consumerId, topic, partition>, consumer发生了分区重分配,
之前的这个consumer已经不负责这个分区的消费了,是不是就炸裂了。。。
最后稍微一笔带过消费者提交位移的概念吧,
既然在broker记录了消费者组维度的消费进度信息,来具体消费到哪里,是不是得有消费者确认,即提交位移。
提交位移的方式有两种,
一种是自动提交,kafka帮我们自动提交,消费完一批数据直接自动提交当前消费进度,自动提交比较方便也无脑,爽是爽但存在重复消费的可能,
另一种是手动提交还支持批量的,消费完一些数据成功了,代码手动去提交位移。
消息系统本身肯定会存在丢失消息和重复消费的可能,因此也不要完全信赖消息系统,做好幂等,做好面向失败的系统设计,
而且就算消息系统已经是削峰和异步,但是也要评估系统流量,如果需要还得对下游资源做好保护和限流。
纯手码,有任何问题,敬请大佬们指正。
转载请注明:汪明鑫的个人博客 » 白话图解Kafka架构

说点什么
您将是第一位评论人!