在上篇文章,我准备了ZK环境、Mysql环境,跑了Spring Boot整合Elastic Job的例子
今天从原理和源码层面更进一步学习Elastic Job, Elastic Job依赖ZK注册任务信息、任务实例,并且会把任务对应的分片也存储在ZK上,
任务的选主也是进行在ZK上,
如果任务实例有挂掉的,会触发ZK的watcher机制, 触发任务分片的重分配。
Elastic Job 底层还基于Quartz做了封装。
如果想测试分片情况,可以用上篇文章的例子idea上跑多个任务实例
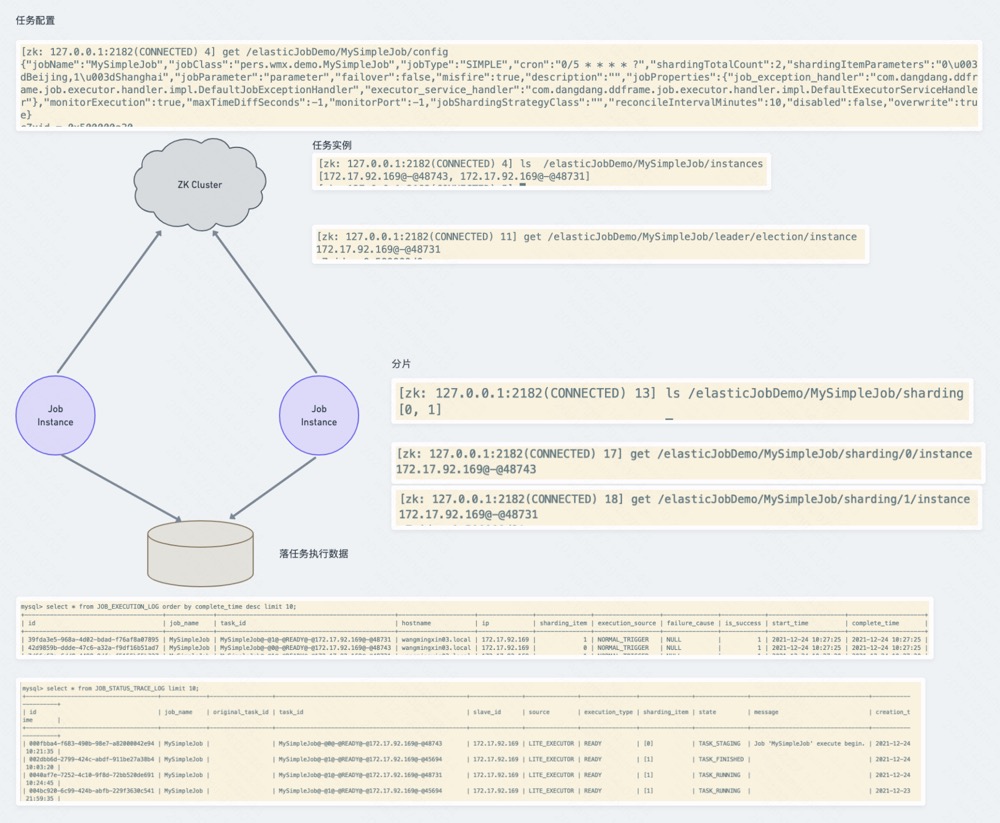
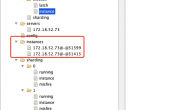
详细看看elastic job在 ZK上存储的数据
ZK中数据的存储是通过namespace隔离的
- instances 节点:
同一个 Job 下的 elastic-job 的部署实例。一台机器上可以启动多个 Job 实例,也就是 Jar 包。instances 的命名是 IP+@-@+PID。只有在运行的时候能看到。
- leader 节点:
任务实例的主节点信息,通过 zookeeper 的主节点选举,选出来的主节点信息。在elastic job 中,任务的执行可以分布在不同的实例(节点)中,但任务分片等核心控制,需要由主节点完成。因此,任务执行前,需要选举出主节点。下面有三个子节点:
- election:主节点选举
- sharding:分片
- failover:失效转移,这里没有显示是未发生失效转移
- servers 节点:
任务实例的信息,主要是 IP 地址,任务实例的 IP 地址。跟 instances 不同,如果多个任务实例在同一台机器上运行则只会出现一个 IP 子节点。可在 IP 地址节点写入DISABLED 表示该任务实例禁用。
- sharding 节点:
任务的分片信息,子节点是分片项序号,从 0 开始。分片个数是在任务配置中设置的。分片项序号的子节点存储详细信息。每个分片项下的子节点用于控制和记录分片运行状态。最主要的子节点就是 instance。
为了方便调试代码,我们再整个简单的demo
@Component
public class MySimpleJob implements SimpleJob {
@Override
public void execute(ShardingContext context) {
System.out.println(
String.format("分片项 ShardingItem: %s | 运行时间: %s | 线程ID: %s | 分片参数: %s | 任务参数: %s ",
context.getShardingItem(),
new SimpleDateFormat("HH:mm:ss").format(new Date()),
Thread.currentThread().getId(),
context.getShardingParameter(),
context.getJobParameter())
);
}
}
public class SimpleJobTest {
// 原生Java跑一个
public static void main(String[] args) {
// zk 注册中心
CoordinatorRegistryCenter registryCenter = new ZookeeperRegistryCenter(
new ZookeeperConfiguration("localhost:2181", "ejob-standalone")
);
registryCenter.init();
// 数据源 , 事件执行持久化策略
DruidDataSource dataSource =new DruidDataSource();
dataSource.setDriverClassName("com.mysql.jdbc.Driver");
dataSource.setUrl("jdbc:mysql://localhost:3306/mydb?useUnicode=true&characterEncoding=utf-8");
dataSource.setUsername("root");
dataSource.setPassword("wmx123");
JobEventConfiguration jobEventConfig = new JobEventRdbConfiguration(dataSource);
JobCoreConfiguration coreConfig = JobCoreConfiguration.newBuilder(
"simpleJob", "0/20 * * * * ?", 4)
.build();
SimpleJobConfiguration simpleJobConfiguration = new SimpleJobConfiguration(
coreConfig, MySimpleJob.class.getCanonicalName()
);
// 作业根配置
LiteJobConfiguration jobRootConfig = LiteJobConfiguration.newBuilder(simpleJobConfiguration)
.overwrite(true)
.build();
// 构建job
new JobScheduler(registryCenter, jobRootConfig, jobEventConfig).init();
}
}
梳理了下面的类图
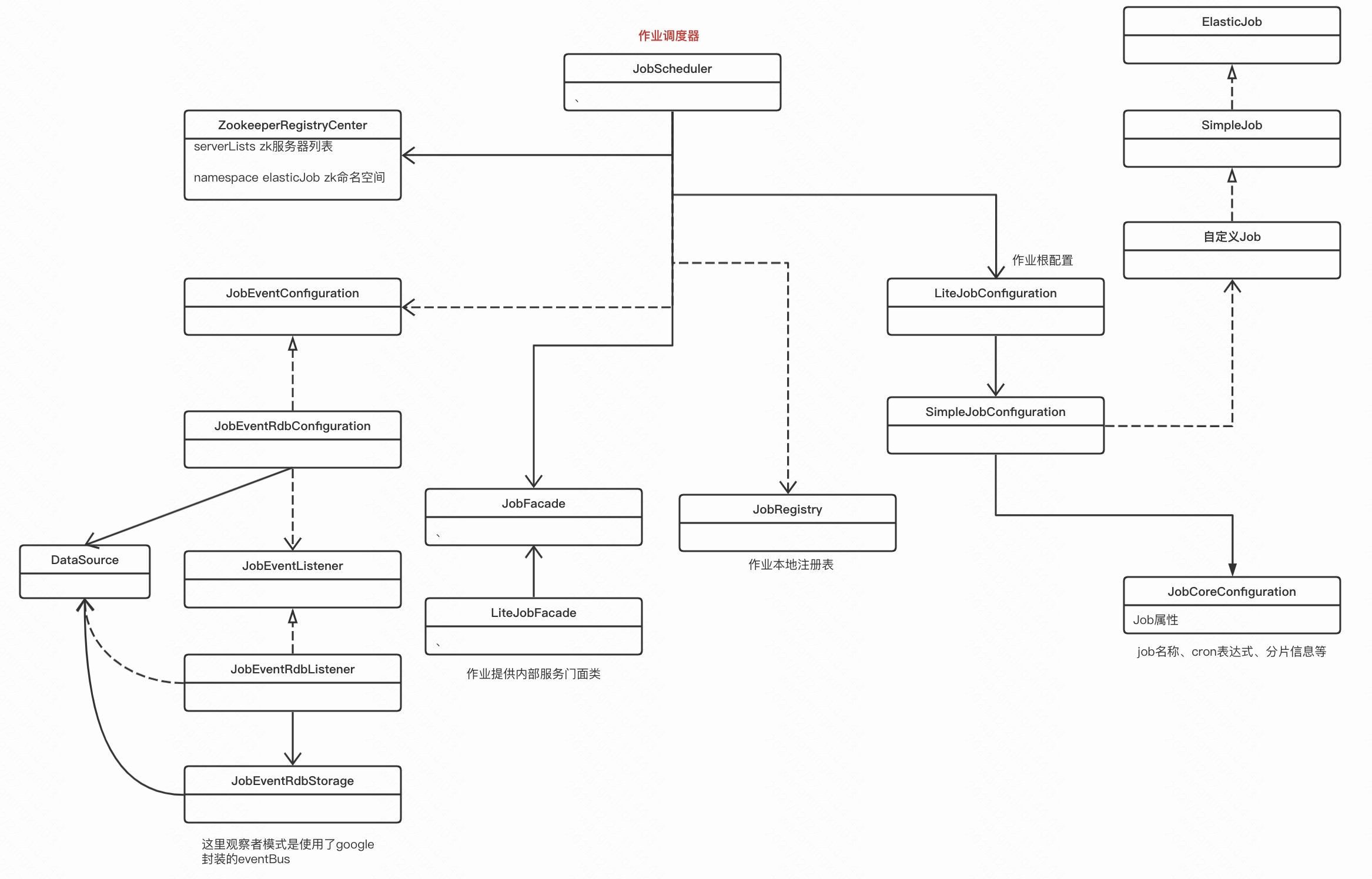
可以看到任务调度器绝对是核心角色,
关联了注册中心 ZookeeperRegistryCenter 作业核心配置 LiteJobConfiguration,还关联了 JobEventConfiguration
LiteJobConfiguration 组合了 SimpleJobConfiguration , 而 SimpleJobConfiguration 组合了任务和执行参数。
可以看到demo都是初始化的一些创建操作,包括zk、数据库资源、创建任务配置、执行周期等。
最关键就是开启调度 new JobScheduler(registryCenter, jobRootConfig, jobEventConfig).init();

/**
* 初始化作业.
*/
public void init() {
LiteJobConfiguration liteJobConfigFromRegCenter = schedulerFacade.updateJobConfiguration(liteJobConfig);
// 设置分片数
JobRegistry.getInstance().setCurrentShardingTotalCount(liteJobConfigFromRegCenter.getJobName(), liteJobConfigFromRegCenter.getTypeConfig().getCoreConfig().getShardingTotalCount());
// 构建任务,创建调度器
JobScheduleController jobScheduleController = new JobScheduleController(
createScheduler(), createJobDetail(liteJobConfigFromRegCenter.getTypeConfig().getJobClass()), liteJobConfigFromRegCenter.getJobName());
// 在 ZK 上注册任务
JobRegistry.getInstance().registerJob(liteJobConfigFromRegCenter.getJobName(), jobScheduleController, regCenter);
// 添加任务信息并进行节点选举
schedulerFacade.registerStartUpInfo(!liteJobConfigFromRegCenter.isDisabled());
// 启动调度器
jobScheduleController.scheduleJob(liteJobConfigFromRegCenter.getTypeConfig().getCoreConfig().getCron());
}
JobRegistry 是Elastic Job的本地注册表,一堆Map存储一些任务相关的
@NoArgsConstructor(access = AccessLevel.PRIVATE)
public final class JobRegistry {
private static volatile JobRegistry instance;
// 调度控制器
private Map<String, JobScheduleController> schedulerMap = new ConcurrentHashMap<>();
//注册中心
private Map<String, CoordinatorRegistryCenter> regCenterMap = new ConcurrentHashMap<>();
// 任务实例
private Map<String, JobInstance> jobInstanceMap = new ConcurrentHashMap<>();
private Map<String, Boolean> jobRunningMap = new ConcurrentHashMap<>();
private Map<String, Integer> currentShardingTotalCountMap = new ConcurrentHashMap<>();
/**
* 获取作业注册表实例.
*
* @return 作业注册表实例
*/
public static JobRegistry getInstance() {
if (null == instance) {
synchronized (JobRegistry.class) {
if (null == instance) {
instance = new JobRegistry();
}
}
}
return instance;
}获取作业注册表实例 使用了单例模式(双重校验锁)
JobScheduleController 实际上是对Quartz的封装,底层还是Quartz对作业调度
作业调度控制器
@RequiredArgsConstructor
public final class JobScheduleController {
private final Scheduler scheduler;
private final JobDetail jobDetail;
private final String triggerIdentity;
/**
* 调度作业.
*
* @param cron CRON表达式
*/
public void scheduleJob(final String cron) {
try {
if (!scheduler.checkExists(jobDetail.getKey())) {
scheduler.scheduleJob(jobDetail, createTrigger(cron));
}
scheduler.start();
} catch (final SchedulerException ex) {
throw new JobSystemException(ex);
}
}
// 。。。
}
看下 init里另一个比较核心的方法 registerStartUpInfo
/**
* 注册作业启动信息.
*
* @param enabled 作业是否启用
*/
public void registerStartUpInfo(final boolean enabled) {
// 启动所有的监听器、监听器用于监听 ZK 节点信息的变化。
listenerManager.startAllListeners();
// 节点选举
leaderService.electLeader();
// 服务信息持久化(写到 ZK)
serverService.persistOnline(enabled);
// 实例信息持久化(写到 ZK)
instanceService.persistOnline();
// 重新分片
shardingService.setReshardingFlag();
// 监控信息监听器
monitorService.listen();
// 自诊断修复,使本地节点与 ZK 数据一致
if (!reconcileService.isRunning()) {
reconcileService.startAsync();
}
}
然后我们关注下一个任务调度到底是怎么执行的,入口在哪里
private JobDetail createJobDetail(final String jobClass) {
JobDetail result = JobBuilder.newJob(LiteJob.class).withIdentity(liteJobConfig.getJobName()).build();
result.getJobDataMap().put(JOB_FACADE_DATA_MAP_KEY, jobFacade);
Optional<ElasticJob> elasticJobInstance = createElasticJobInstance();
if (elasticJobInstance.isPresent()) {
result.getJobDataMap().put(ELASTIC_JOB_DATA_MAP_KEY, elasticJobInstance.get());
} else if (!jobClass.equals(ScriptJob.class.getCanonicalName())) {
try {
result.getJobDataMap().put(ELASTIC_JOB_DATA_MAP_KEY, Class.forName(jobClass).newInstance());
} catch (final ReflectiveOperationException ex) {
throw new JobConfigurationException("Elastic-Job: Job class '%s' can not initialize.", jobClass);
}
}
return result;
}
JobDetail result = JobBuilder.newJob(LiteJob.class).withIdentity(liteJobConfig.getJobName()).build();
可以看到这里传递了LiteJob
public final class LiteJob implements Job {
@Setter
private ElasticJob elasticJob;
@Setter
private JobFacade jobFacade;
@Override
public void execute(final JobExecutionContext context) throws JobExecutionException {
JobExecutorFactory.getJobExecutor(elasticJob, jobFacade).execute();
}
}
每次任务调度都会走到Quartz的调度线程
org.quartz.core.QuartzSchedulerThread
org.quartz.core.JobRunShell#initialize
public void initialize(QuartzScheduler sched)
throws SchedulerException {
this.qs = sched;
Job job = null;
JobDetail jobDetail = firedTriggerBundle.getJobDetail();
try {
job = sched.getJobFactory().newJob(firedTriggerBundle, scheduler);
} catch (SchedulerException se) {
sched.notifySchedulerListenersError(
"An error occured instantiating job to be executed. job= '"
+ jobDetail.getKey() + "'", se);
throw se;
} catch (Throwable ncdfe) { // such as NoClassDefFoundError
SchedulerException se = new SchedulerException(
"Problem instantiating class '"
+ jobDetail.getJobClass().getName() + "' - ", ncdfe);
sched.notifySchedulerListenersError(
"An error occured instantiating job to be executed. job= '"
+ jobDetail.getKey() + "'", se);
throw se;
}
this.jec = new JobExecutionContextImpl(scheduler, firedTriggerBundle, job);
}
调用 sched.getJobFactory().newJob(firedTriggerBundle, scheduler);
public class PropertySettingJobFactory extends SimpleJobFactory {
private boolean warnIfNotFound = false;
private boolean throwIfNotFound = false;
@Override
public Job newJob(TriggerFiredBundle bundle, Scheduler scheduler) throws SchedulerException {
Job job = super.newJob(bundle, scheduler);
JobDataMap jobDataMap = new JobDataMap();
jobDataMap.putAll(scheduler.getContext());
jobDataMap.putAll(bundle.getJobDetail().getJobDataMap());
jobDataMap.putAll(bundle.getTrigger().getJobDataMap());
setBeanProps(job, jobDataMap);
return job;
}
public Job newJob(TriggerFiredBundle bundle, Scheduler Scheduler) throws SchedulerException {
JobDetail jobDetail = bundle.getJobDetail();
Class<? extends Job> jobClass = jobDetail.getJobClass();
try {
if(log.isDebugEnabled()) {
log.debug(
"Producing instance of Job '" + jobDetail.getKey() +
"', class=" + jobClass.getName());
}
return jobClass.newInstance();
} catch (Exception e) {
SchedulerException se = new SchedulerException(
"Problem instantiating class '"
+ jobDetail.getJobClass().getName() + "'", e);
throw se;
}
}这里会基于 jobClass 创建Job实例, 就是LiteJob实例
真正调度是起work线程执行 org.quartz.core.JobRunShell#run
在 org.quartz.core.JobRunShell#run 中会调用 job.execute(jec)
然后调用 com.dangdang.ddframe.job.lite.internal.schedule.LiteJob#execute,好了,我们核心关注点就可以放在这里了
public final class LiteJob implements Job {
@Setter
private ElasticJob elasticJob;
@Setter
private JobFacade jobFacade;
@Override
public void execute(final JobExecutionContext context) throws JobExecutionException {
JobExecutorFactory.getJobExecutor(elasticJob, jobFacade).execute();
}
}
@NoArgsConstructor(access = AccessLevel.PRIVATE)
public final class JobExecutorFactory {
/**
* 获取作业执行器.
*
* @param elasticJob 分布式弹性作业
* @param jobFacade 作业内部服务门面服务
* @return 作业执行器
*/
@SuppressWarnings("unchecked")
public static AbstractElasticJobExecutor getJobExecutor(final ElasticJob elasticJob, final JobFacade jobFacade) {
if (null == elasticJob) {
return new ScriptJobExecutor(jobFacade);
}
if (elasticJob instanceof SimpleJob) {
return new SimpleJobExecutor((SimpleJob) elasticJob, jobFacade);
}
if (elasticJob instanceof DataflowJob) {
return new DataflowJobExecutor((DataflowJob) elasticJob, jobFacade);
}
throw new JobConfigurationException("Cannot support job type '%s'", elasticJob.getClass().getCanonicalName());
}
}
这里使用了工厂模式
我们写的 Job是 SimpleJob
会走到 SimpleJobExecutor
public final class SimpleJobExecutor extends AbstractElasticJobExecutor {
private final SimpleJob simpleJob;
public SimpleJobExecutor(final SimpleJob simpleJob, final JobFacade jobFacade) {
super(jobFacade);
this.simpleJob = simpleJob;
}
@Override
protected void process(final ShardingContext shardingContext) {
simpleJob.execute(shardingContext);
}
}
看下 com.dangdang.ddframe.job.executor.AbstractElasticJobExecutor#execute()
然后调用本类另一个私有方法 com.dangdang.ddframe.job.executor.AbstractElasticJobExecutor#execute(com.dangdang.ddframe.job.executor.ShardingContexts, com.dangdang.ddframe.job.event.type.JobExecutionEvent.ExecutionSource)
com.dangdang.ddframe.job.executor.AbstractElasticJobExecutor#process(com.dangdang.ddframe.job.executor.ShardingContexts, com.dangdang.ddframe.job.event.type.JobExecutionEvent.ExecutionSource)
分片参数ShardingContexts 会一路传递,最后会调用到
private void process(final ShardingContexts shardingContexts, final int item, final JobExecutionEvent startEvent) {
if (shardingContexts.isAllowSendJobEvent()) {
jobFacade.postJobExecutionEvent(startEvent);
}
log.trace("Job '{}' executing, item is: '{}'.", jobName, item);
JobExecutionEvent completeEvent;
try {
process(new ShardingContext(shardingContexts, item));
completeEvent = startEvent.executionSuccess();
log.trace("Job '{}' executed, item is: '{}'.", jobName, item);
if (shardingContexts.isAllowSendJobEvent()) {
jobFacade.postJobExecutionEvent(completeEvent);
}
// CHECKSTYLE:OFF
} catch (final Throwable cause) {
// CHECKSTYLE:ON
completeEvent = startEvent.executionFailure(cause);
jobFacade.postJobExecutionEvent(completeEvent);
itemErrorMessages.put(item, ExceptionUtil.transform(cause));
jobExceptionHandler.handleException(jobName, cause);
}
}
然后会调用
protected abstract void process(ShardingContext shardingContext);
这里用了模版方法模式,具体的process 方法子类实现
看到子类 SimpleJobExecutor 的 process 实际就是执行了业务Job的 execute方法
public final class SimpleJobExecutor extends AbstractElasticJobExecutor {
private final SimpleJob simpleJob;
public SimpleJobExecutor(final SimpleJob simpleJob, final JobFacade jobFacade) {
super(jobFacade);
this.simpleJob = simpleJob;
}
@Override
protected void process(final ShardingContext shardingContext) {
simpleJob.execute(shardingContext);
}
}
@Component
public class MySimpleJob implements SimpleJob {
@Override
public void execute(ShardingContext context) {
System.out.println(
String.format("分片项 ShardingItem: %s | 运行时间: %s | 线程ID: %s | 分片参数: %s | 任务参数: %s ",
context.getShardingItem(),
new SimpleDateFormat("HH:mm:ss").format(new Date()),
Thread.currentThread().getId(),
context.getShardingParameter(),
context.getJobParameter())
);
}
}
Job执行的流程就串完了,看下分片参数怎么分配的呢?
看下 com.dangdang.ddframe.job.executor.AbstractElasticJobExecutor#execute() 里对分片参数的获取
ShardingContexts shardingContexts = jobFacade.getShardingContexts();
@Override
public ShardingContexts getShardingContexts() {
boolean isFailover = configService.load(true).isFailover();
if (isFailover) {
List<Integer> failoverShardingItems = failoverService.getLocalFailoverItems();
if (!failoverShardingItems.isEmpty()) {
return executionContextService.getJobShardingContext(failoverShardingItems);
}
}
shardingService.shardingIfNecessary();
List<Integer> shardingItems = shardingService.getLocalShardingItems();
if (isFailover) {
shardingItems.removeAll(failoverService.getLocalTakeOffItems());
}
shardingItems.removeAll(executionService.getDisabledItems(shardingItems));
return executionContextService.getJobShardingContext(shardingItems);
}
看下 shardingIfNecessary
/**
* 如果需要分片且当前节点为主节点, 则作业分片.
*
* <p>
* 如果当前无可用节点则不分片.
* </p>
*/
public void shardingIfNecessary() {
// 获取有效的任务实例
List<JobInstance> availableJobInstances = instanceService.getAvailableJobInstances();
if (!isNeedSharding() || availableJobInstances.isEmpty()) {
return;
}
if (!leaderService.isLeaderUntilBlock()) {
// 等待分片分配完成
blockUntilShardingCompleted();
return;
}
waitingOtherJobCompleted();
LiteJobConfiguration liteJobConfig = configService.load(false);
int shardingTotalCount = liteJobConfig.getTypeConfig().getCoreConfig().getShardingTotalCount();
log.debug("Job '{}' sharding begin.", jobName);
jobNodeStorage.fillEphemeralJobNode(ShardingNode.PROCESSING, "");
resetShardingInfo(shardingTotalCount);
// 获取分片分配策略
JobShardingStrategy jobShardingStrategy = JobShardingStrategyFactory.getStrategy(liteJobConfig.getJobShardingStrategyClass());
// 存储分片分配结果
jobNodeStorage.executeInTransaction(new PersistShardingInfoTransactionExecutionCallback(jobShardingStrategy.sharding(availableJobInstances, jobName, shardingTotalCount)));
log.debug("Job '{}' sharding complete.", jobName);
}
计算sharding分配 这里使用了策略工厂模式
JobShardingStrategyFactory.getStrategy(liteJobConfig.getJobShardingStrategyClass())
/**
* 获取作业分片策略实例.
*
* @param jobShardingStrategyClassName 作业分片策略类名
* @return 作业分片策略实例
*/
public static JobShardingStrategy getStrategy(final String jobShardingStrategyClassName) {
if (Strings.isNullOrEmpty(jobShardingStrategyClassName)) {
return new AverageAllocationJobShardingStrategy();
}
try {
Class<?> jobShardingStrategyClass = Class.forName(jobShardingStrategyClassName);
if (!JobShardingStrategy.class.isAssignableFrom(jobShardingStrategyClass)) {
throw new JobConfigurationException("Class '%s' is not job strategy class", jobShardingStrategyClassName);
}
return (JobShardingStrategy) jobShardingStrategyClass.newInstance();
} catch (final ClassNotFoundException | InstantiationException | IllegalAccessException ex) {
throw new JobConfigurationException("Sharding strategy class '%s' config error, message details are '%s'", jobShardingStrategyClassName, ex.getMessage());
}
}
jobShardingStrategy.sharding(availableJobInstances, jobName, shardingTotalCount)
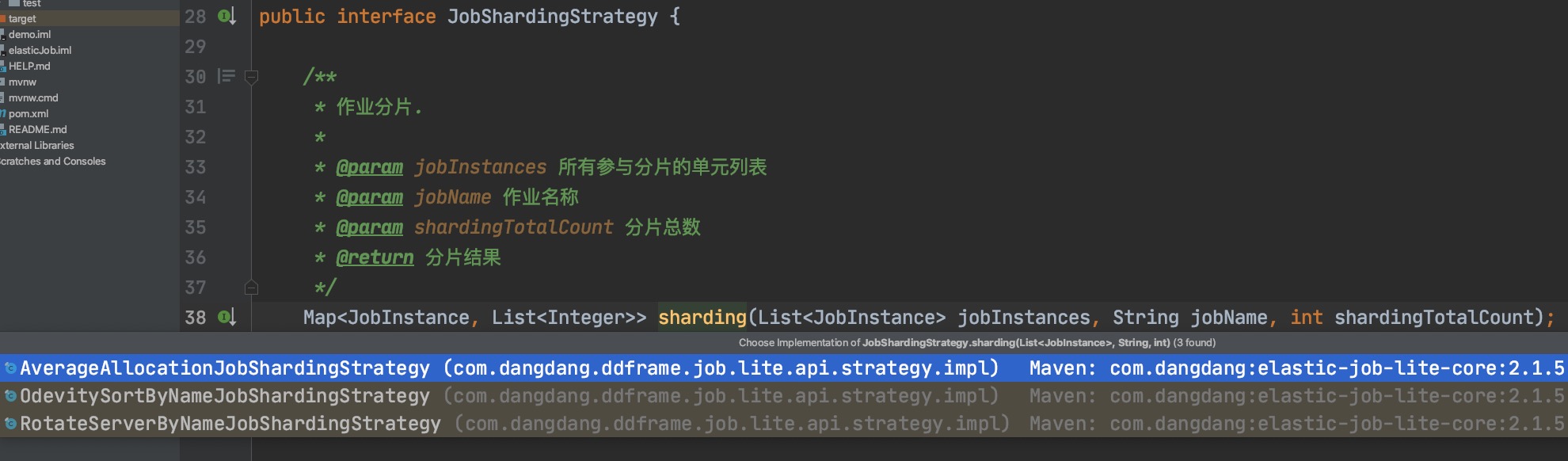
分片参数提供了3种
/**
* 基于平均分配算法的分片策略.
*
* <p>
* 如果分片不能整除, 则不能整除的多余分片将依次追加到序号小的服务器.
* 如:
* 1. 如果有3台服务器, 分成9片, 则每台服务器分到的分片是: 1=[0,1,2], 2=[3,4,5], 3=[6,7,8].
* 2. 如果有3台服务器, 分成8片, 则每台服务器分到的分片是: 1=[0,1,6], 2=[2,3,7], 3=[4,5].
* 3. 如果有3台服务器, 分成10片, 则每台服务器分到的分片是: 1=[0,1,2,9], 2=[3,4,5], 3=[6,7,8].
* </p>
*
* @author zhangliang
*/
public final class AverageAllocationJobShardingStrategy implements JobShardingStrategy {/**
* 根据作业名的哈希值奇偶数决定IP升降序算法的分片策略.
*
* <p>
* 作业名的哈希值为奇数则IP升序.
* 作业名的哈希值为偶数则IP降序.
* 用于不同的作业平均分配负载至不同的服务器.
* 如:
* 1. 如果有3台服务器, 分成2片, 作业名称的哈希值为奇数, 则每台服务器分到的分片是: 1=[0], 2=[1], 3=[].
* 2. 如果有3台服务器, 分成2片, 作业名称的哈希值为偶数, 则每台服务器分到的分片是: 3=[0], 2=[1], 1=[].
* </p>
*
* @author zhangliang
*/
public final class OdevitySortByNameJobShardingStrategy implements JobShardingStrategy {/**
* 根据作业名的哈希值对服务器列表进行轮转的分片策略.
*
* @author weishubin
*/
public final class RotateServerByNameJobShardingStrategy implements JobShardingStrategy {
会告诉当前的分片参数,每个实例分配的具体参数,这样就就可以达到任务多实例并行处理自己分片的逻辑啦~
分片的分配也会存储到ZK。
Elastic Job中还大量使用了观察者模式
像任务Event的发布和订阅,使用Google封装的EventBus
比如在任务运行时,会发布任务状态的事件
if (shardingContexts.isAllowSendJobEvent()) {
jobFacade.postJobStatusTraceEvent(taskId, State.TASK_RUNNING, "");
}/**
* 运行痕迹事件总线.
*
* @author zhangliang
* @author caohao
*/
@Slf4j
public final class JobEventBus {
private final JobEventConfiguration jobEventConfig;
private final ExecutorServiceObject executorServiceObject;
private final EventBus eventBus;
private boolean isRegistered;
public JobEventBus() {
jobEventConfig = null;
executorServiceObject = null;
eventBus = null;
}
public JobEventBus(final JobEventConfiguration jobEventConfig) {
this.jobEventConfig = jobEventConfig;
executorServiceObject = new ExecutorServiceObject("job-event", Runtime.getRuntime().availableProcessors() * 2);
eventBus = new AsyncEventBus(executorServiceObject.createExecutorService());
register();
}
private void register() {
try {
eventBus.register(jobEventConfig.createJobEventListener());
isRegistered = true;
} catch (final JobEventListenerConfigurationException ex) {
log.error("Elastic job: create JobEventListener failure, error is: ", ex);
}
}
/**
* 发布事件.
*
* @param event 作业事件
*/
public void post(final JobEvent event) {
if (isRegistered && !executorServiceObject.isShutdown()) {
eventBus.post(event);
}
}
}
public interface JobEventListener extends JobEventIdentity {
/**
* 作业执行事件监听执行.
*
* @param jobExecutionEvent 作业执行事件
*/
@Subscribe
@AllowConcurrentEvents
void listen(JobExecutionEvent jobExecutionEvent);
/**
* 作业状态痕迹事件监听执行.
*
* @param jobStatusTraceEvent 作业状态痕迹事件
*/
@Subscribe
@AllowConcurrentEvents
void listen(JobStatusTraceEvent jobStatusTraceEvent);
}
@Subscribe 注解对应的方法参数,就是要监听的事件
还有在任务启动过程中,会利用ZK的watcher机制,往ZK注册很多监听器
/**
* 开启所有监听器.
*/
public void startAllListeners() {
electionListenerManager.start();
shardingListenerManager.start();
failoverListenerManager.start();
monitorExecutionListenerManager.start();
shutdownListenerManager.start();
triggerListenerManager.start();
rescheduleListenerManager.start();
guaranteeListenerManager.start();
jobNodeStorage.addConnectionStateListener(regCenterConnectionStateListener);
}我们主要看下 failoverListenerManager
看看elastic job 如何处理失效转移的
实现失效转移功能,在某台服务器执行完毕后主动抓取未分配的分片,并且在某台服务器下线后主动寻找可用的服务器执行任务。
基于ZK curator 添加了2监听器
JobCrashedJobListener 监听是不是有节点挂掉
class JobCrashedJobListener extends AbstractJobListener {
@Override
protected void dataChanged(final String path, final Type eventType, final String data) {
if (isFailoverEnabled() && Type.NODE_REMOVED == eventType && instanceNode.isInstancePath(path)) {
// 获取挂掉的任务实例ID
String jobInstanceId = path.substring(instanceNode.getInstanceFullPath().length() + 1);
if (jobInstanceId.equals(JobRegistry.getInstance().getJobInstance(jobName).getJobInstanceId())) {
return;
}
// 获取挂掉节点的 failover item
List<Integer> failoverItems = failoverService.getFailoverItems(jobInstanceId);
if (!failoverItems.isEmpty()) {
for (int each : failoverItems) {
failoverService.setCrashedFailoverFlag(each);
failoverService.failoverIfNecessary();
}
} else {
// 最开始 failover item是空的,获取任务实例之前分配的item
for (int each : shardingService.getShardingItems(jobInstanceId)) {
failoverService.setCrashedFailoverFlag(each);
failoverService.failoverIfNecessary();
}
}
}
}
}
setCrashedFailoverFlag
往zk 写入失效的分片item {jobName}/leader/failover/items/{item} , 标明item需要其他的任务实例给分走 =-=
failoverIfNecessary
开始执行失效转移
/**
* 如果需要失效转移, 则执行作业失效转移.
*/
public void failoverIfNecessary() {
if (needFailover()) {
jobNodeStorage.executeInLeader(FailoverNode.LATCH, new FailoverLeaderExecutionCallback());
}
}
private boolean needFailover() {
return jobNodeStorage.isJobNodeExisted(FailoverNode.ITEMS_ROOT) && !jobNodeStorage.getJobNodeChildrenKeys(FailoverNode.ITEMS_ROOT).isEmpty()
&& !JobRegistry.getInstance().isJobRunning(jobName);
}
class FailoverLeaderExecutionCallback implements LeaderExecutionCallback {
@Override
public void execute() {
if (JobRegistry.getInstance().isShutdown(jobName) || !needFailover()) {
return;
}
// 获得 ${JOB_NAME}/leader/failover/items/${ITEM_ID} 作业分片项
int crashedItem = Integer.parseInt(jobNodeStorage.getJobNodeChildrenKeys(FailoverNode.ITEMS_ROOT).get(0));
log.debug("Failover job '{}' begin, crashed item '{}'", jobName, crashedItem);
// 设置 ${JOB_NAME}/sharding/${ITEM_ID}/failover 作业分片项为 当前拉取实效的作业节点(把失效的作业拉过来自己做 因为有分布式锁,所以只有一个实例拉取成功)
jobNodeStorage.fillEphemeralJobNode(FailoverNode.getExecutionFailoverNode(crashedItem), JobRegistry.getInstance().getJobInstance(jobName).getJobInstanceId());
// 移除 ${JOB_NAME}/leader/failover/items/${ITEM_ID} 作业分片项
jobNodeStorage.removeJobNodeIfExisted(FailoverNode.getItemsNode(crashedItem));
// TODO 不应使用triggerJob, 而是使用executor统一调度
JobScheduleController jobScheduleController = JobRegistry.getInstance().getJobScheduleController(jobName);
if (null != jobScheduleController) {
jobScheduleController.triggerJob();
}
}
}
ojbk,这里其他任务实例存储了需要实效转移的item,正常的分配开始执行item, 依然是在执行任务获取分片信息时
在作业执行流程中获取分片信息的时候,如果开启了故障转移,本次作业的执行,会去优先执行故障转移到当前节点的分片任务。
失效转移这块代码是真的恶心。。。
转载请注明:汪明鑫的个人博客 » Elastic Job 原理

说点什么
您将是第一位评论人!