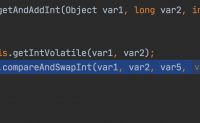
都说乐观锁好,使用简单,性能好,那有什么局限性呢?
请求越多,更改的并发量越大,势必使很多请求持有的值都是旧值
要么丢失变更直接放弃,如果是业务层面写操作,直接影响业务
或者循环重试,这样又会有更多的失败,带来更久的自旋,浪费CPU资源
重则拖垮整个系统
拿 jav...
3年前 (2022-06-09) 860浏览 0评论
0喜欢
首先 ConcurrentHashMap 是可以解决并发安全问题的容器
HashMap在并法操作下会出现各种各样的问题
HashTable也解决了兵法问题,但一锁就是整张表
代码也比较清楚
通过key得到hash,定位table中的位置
再去遍历当前Entry下的...
3年前 (2022-06-09) 846浏览 0评论
0喜欢
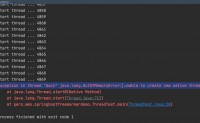
Exception in thread “main” java.lang.OutOfMemoryError: unable to create new native thread
无意间遇到过这样的异常
意思是没法创建新的线程,线程肯定需要空间存储,但是线...
3年前 (2022-06-07) 989浏览 0评论
0喜欢
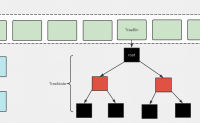
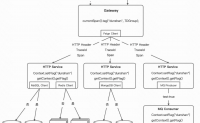
整个研发流程的研发效能很重要,好的研发性能能很大程度提升研发同学的幸福感,更能有助于减少需求线上的问题。
整个研发流程:
那么我们的效能问题会出现在哪些环节呢?
大的划分我们可以看到几个大的环节:
一、开发前
二、开发中
三、测试
四、上线
&nbs...
3年前 (2022-05-31) 860浏览 0评论
0喜欢
一个事情团队内部闭环来做,一般推动起来比较容易,也很少遇到阻塞点。
但一旦涉及到需要多个团队支持,就可能会处处受限制,甚至处处碰壁。
其实换位思考也合理,因为想想如果有其他团队人员直接找你做技术支持,如果是简单的答疑还好,如果是需要协助排查线上问题或者做一些开发事情还是比较占用时...
3年前 (2022-05-31) 851浏览 0评论
0喜欢
蛋疼,北京这疫情真的恶心,在家呆长毛了,已经在家呆快一个月啦~
辣鸡疫情滚啊
夏天来啦,开始热起来啦
最近2月看了不少剧,感觉还不错。。。
我叫赵甲弟
欢迎光临
新居之约
梦华录
说英雄谁是英雄
猎罪图鉴
青谷子
热血青春
重生之门
干饭的时候找点剧看...
3年前 (2022-05-23) 970浏览 0评论
2喜欢
“影子”的概念在技术侧最早诞生于阿里的大促全链路压测
那我们先来聊下全链路压测
由于业务不断的架构升级,引入分布式微服务
传统的线下测试已经不能满足我们的测试需求了,因此需要全链路压测
一般需要压测平台,创建配置压测计划,对接口进行发压
这样的压测流...
4年前 (2022-04-22) 1723浏览 0评论
3喜欢
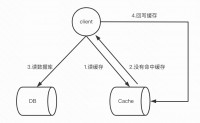
缓存使用场景和心得
内存的诞生是为了弥补CPU和磁盘速度的不一致的问题
内存的价格都比磁盘要贵的多
CPU的多级缓存也是同理,把数据暂存于缓存,加速数据读取
在业务中我们也常常使用缓存做读写分离,写操作落db
读流量打到缓存,用缓存抗读流量,用了...
4年前 (2022-04-22) 1965浏览 0评论
0喜欢
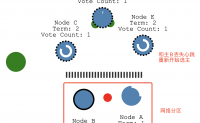
本文简单介绍分布式共识算法 Raft
Raft存在的目的是为了解决分布式集群下数据不一致的问题
Raft主要有2个流程:
1)选主
2)数据同步
Raft集群节点身份见下图 网上扒的,比较清晰,
大概就是候选人,获得多数投票成为leader, 发现更高...
4年前 (2022-04-22) 939浏览 0评论
0喜欢
Map Reduce
为了整个系统的吞吐量,做到分片多实例并行处理
异步化
主要包含几个方面,一来是通过消息队列做削峰和解藕,可以把非核心逻辑异步化,避免同步接口等待耗时过长
还可以理解通过定时任务实现异步扫库表驱动
这里也可以理解起多线程异步并行处理
&n...
4年前 (2022-03-28) 965浏览 0评论
1喜欢