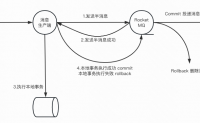
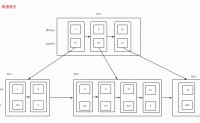
之前记住这个图,就自认为理解了事务消息,然而在生产中真的用的事务消息时,发现还是有很多地方理解不到位的,这里再好好学习,深入理解一下。
RocketMQ可以帮助我们实现最终一致性
比如我们本地执行一个事务,然后还有一个其他系统的事务,我们想保证2个模...
汪明鑫
3年前 (2023-02-06) 1058浏览 0评论
0喜欢
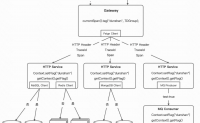
“影子”的概念在技术侧最早诞生于阿里的大促全链路压测
那我们先来聊下全链路压测
由于业务不断的架构升级,引入分布式微服务
传统的线下测试已经不能满足我们的测试需求了,因此需要全链路压测
一般需要压测平台,创建配置压测计划,对接口进行发压
这样的压测流...
汪明鑫
3年前 (2022-04-22) 1679浏览 0评论
3喜欢
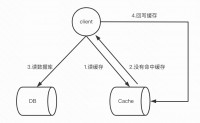
缓存使用场景和心得
内存的诞生是为了弥补CPU和磁盘速度的不一致的问题
内存的价格都比磁盘要贵的多
CPU的多级缓存也是同理,把数据暂存于缓存,加速数据读取
在业务中我们也常常使用缓存做读写分离,写操作落db
读流量打到缓存,用缓存抗读流量,用了...
汪明鑫
3年前 (2022-04-22) 1911浏览 0评论
0喜欢
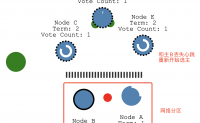
本文简单介绍分布式共识算法 Raft
Raft存在的目的是为了解决分布式集群下数据不一致的问题
Raft主要有2个流程:
1)选主
2)数据同步
Raft集群节点身份见下图 网上扒的,比较清晰,
大概就是候选人,获得多数投票成为leader, 发现更高...
汪明鑫
3年前 (2022-04-22) 887浏览 0评论
0喜欢
Map Reduce
为了整个系统的吞吐量,做到分片多实例并行处理
异步化
主要包含几个方面,一来是通过消息队列做削峰和解藕,可以把非核心逻辑异步化,避免同步接口等待耗时过长
还可以理解通过定时任务实现异步扫库表驱动
这里也可以理解起多线程异步并行处理
&n...
汪明鑫
4年前 (2022-03-28) 919浏览 0评论
1喜欢
如果可以使用被驱动表的索引,join还是有优势的,让驱动表走全表扫描,而被驱动表是走树搜索。
否则就是驱动表全表扫 + 被驱动表全表扫,那就不要用join。
使用join的时候,尽量使用小表作为驱动表。
join会借助join buffer做数据关联,join buffer不够...
汪明鑫
4年前 (2022-03-14) 1063浏览 0评论
3喜欢
查询过程中访问到的对象才会加锁,而加锁的基本单位是next-key lock(前开后闭);
等值查询上MySQL的优化:索引上的等值查询,如果是唯一索引,next-key lock会退化为行锁,如果不是唯一索引,需要访问到第一个不满足条件的值,此时next-key lock会...
汪明鑫
4年前 (2022-03-01) 1248浏览 0评论
0喜欢
每创建一个表,就会基于主键建立一个主键索引,就是一个B+树
每多创建一个索引,就会多生成一个索引树
数据和索引就在一起,因此称为聚集(簇)索引
B+的叶子节点才有数据,可以理解非叶子节点都是起到目录作用
主键索引树和普通索引树的区别就是普通索引树叶子节点是包含主键,...
汪明鑫
4年前 (2022-03-01) 1192浏览 0评论
2喜欢
redo log
innodb引擎专有的重做日志
事务持久化,这也是为啥说myisam不支持事务,innodb支持事务
redo log是先落日志再写磁盘,类似基于内存整个小本本,每次事务来了,记个账,选择合适的时机再刷到磁盘里
redo log分为两个阶段: ...
汪明鑫
4年前 (2022-03-01) 1050浏览 0评论
0喜欢
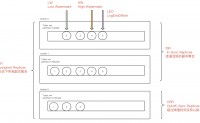
Kafka 引入逻辑 Topic, 将消息分主题管理
物理存储使用的partition, partition 目的是水平扩展,增加吞吐量,让不同的消息路由到不同的partition
partition为了高可用,又引入了副本机制,使用方可以指定副本数量partit...
汪明鑫
4年前 (2022-01-19) 1062浏览 0评论
6喜欢