学习Kafka之前,我们先了解一下消息队列的一些概念
描述一个场景,有一个电商系统,有两部分是订单系统和配送系统,部署在一台服务器上
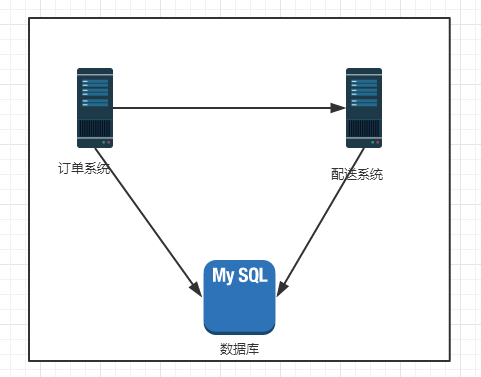
后来用户量大了,系统跑不动了,于是“拆分”
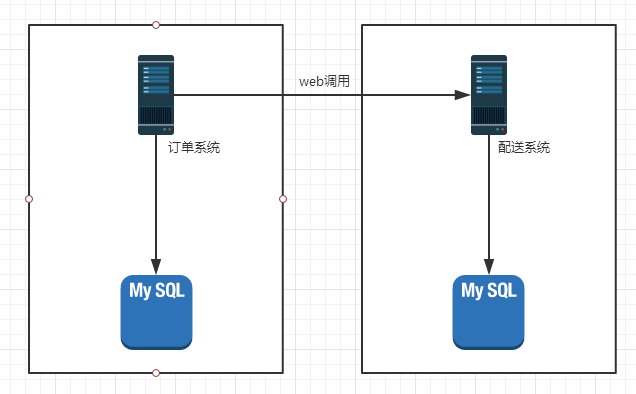
订单系统这边调用远程web服务,迟迟得不到配送系统的响应,我这边就得一直等待结果的返回,典型的同步操作 ——– > 改成异步操作
于是有了消息队列的概念,订单系统只往消息队列里写入订单消息,不管配送系统的返回结果,也不管配送系统什么时候读取
在大型的分布式系统中,做到异步通信
消息队列中的订单消息也不能断电丢失 —–>持久化,存到硬盘上
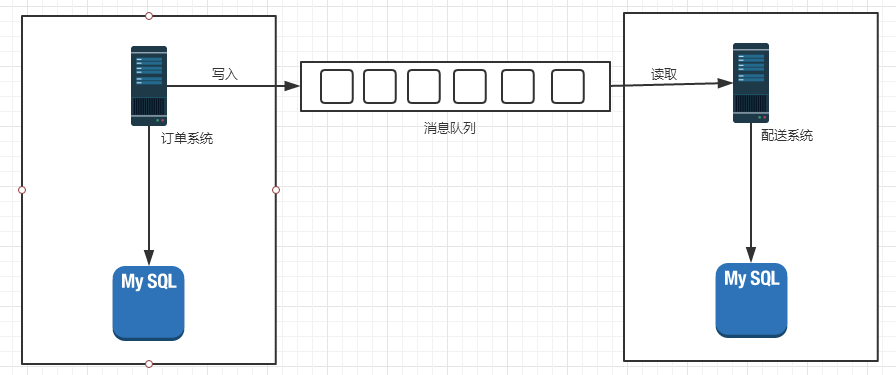
抽象出生产者消费者模型

“消息队列”(Message queue)就是在消息的传输过程中保存消息的容器。“消息” 是在两台计算机间传送的数据单位。消息可以非常简单,例如只包含文本字符串;也可以更复杂,可能包含嵌入对象。
于是乎有了JMS (Java Message Service)
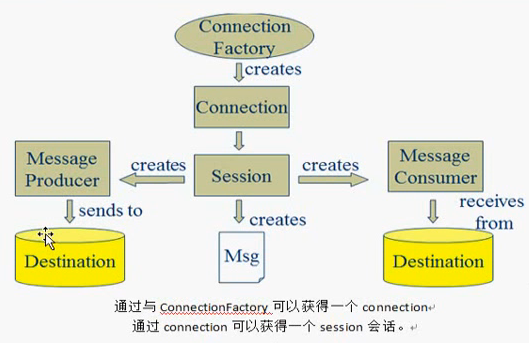
JMS即Java消息服务(Java Message Service)应用程序接口是一个Java平台中关于面向消息中间件(MOM)的API,用于在两个应用程序之间,或分布式系统中发送消息,进行异步通信。Java消息服务是一个与具体平台无关的API,绝大多数MOM提供商都对JMS提供支持。
JMS消费模型:
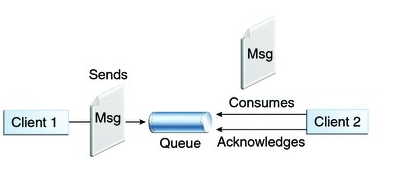
1)点对点模型(一对一,消费者主动拉取数据,消息收到后,消息清除)
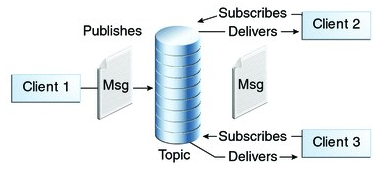
2)发布/订阅模式(一对多,数据生产后,推送给所有订阅者)
使用消息队列的好处:
通过异步处理提高系统性能
常用的消息队列:
- activemq 速度较慢、压力大时容易崩溃
- rabbitmq 较快、耗内存、主从模式、较完善的权限控制
- kafka 分布式设计、高可用、高性能

简而言之,Kafka要比其他的MQ好很多
进入正题 Kafka
Kafka是什么
1)Apache Kafka是一个开源消息系统,由Scala写成。是由Apache软件基金会开发的一个开源消息系统项目。
2)Kafka最初是由LinkedIn公司开发,并于 2011年初开源。2012年10月从Apache Incubator毕业。该项目的目标是为处理实时数据提供一个统一、高通量、低等待的平台。
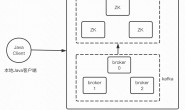
3)Kafka是一个分布式消息队列。Kafka对消息保存时根据Topic进行归类,发送消息者称为Producer,消息接受者称为Consumer,此外kafka集群有多个kafka实例组成,每个实例(server)成为broker。
4)无论是kafka集群,还是producer和consumer都依赖于zookeeper集群保存一些meta信息,来保证系统可用性。
首先附上官方文档 Kafka官方文档
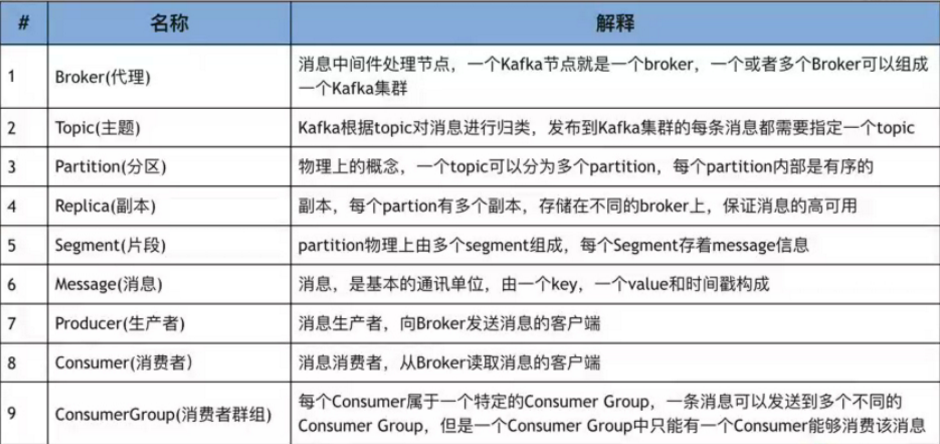
Kafka相关名词解释
举一个例子更好的认识Kafka
生产者生产鸡蛋,消费者消费鸡蛋,生产者生产一个鸡蛋,消费者就消费一个鸡蛋,假设消费者消费鸡蛋的时候噎住了(系统宕机了),生产者还在生产鸡蛋,那新生产的鸡蛋就丢失了。再比如生产者很强劲(大交易量的情况),生产者1秒钟生产100个鸡蛋,消费者1秒钟只能吃50个鸡蛋,那要不了一会,消费者就吃不消了(消息堵塞,最终导致系统超时),消费者拒绝再吃了,”鸡蛋“又丢失了,这个时候我们放个篮子在它们中间,生产出来的鸡蛋都放到篮子里,消费者去篮子里拿鸡蛋,这样鸡蛋就不会丢失了,都在篮子里,而这个篮子就是”kafka“。
鸡蛋其实就是“数据流”,系统之间的交互都是通过“数据流”来传输的(就是tcp、http什么的),也称为报文,也叫“消息”。
消息队列满了,其实就是篮子满了,”鸡蛋“ 放不下了,那赶紧多放几个篮子,其实就是kafka的扩容。
各位现在知道kafka是干什么的了吧,它就是那个”篮子”。
- producer:生产者,就是它来生产“鸡蛋”的。
- consumer:消费者,生出的“鸡蛋”它来消费。
- topic:你把它理解为标签,生产者每生产出来一个鸡蛋就贴上一个标签(topic),消费者可不是谁生产的“鸡蛋”都吃的,这样不同的生产者生产出来的“鸡蛋”,消费者就可以选择性的“吃”了。
- broker:就是篮子了。
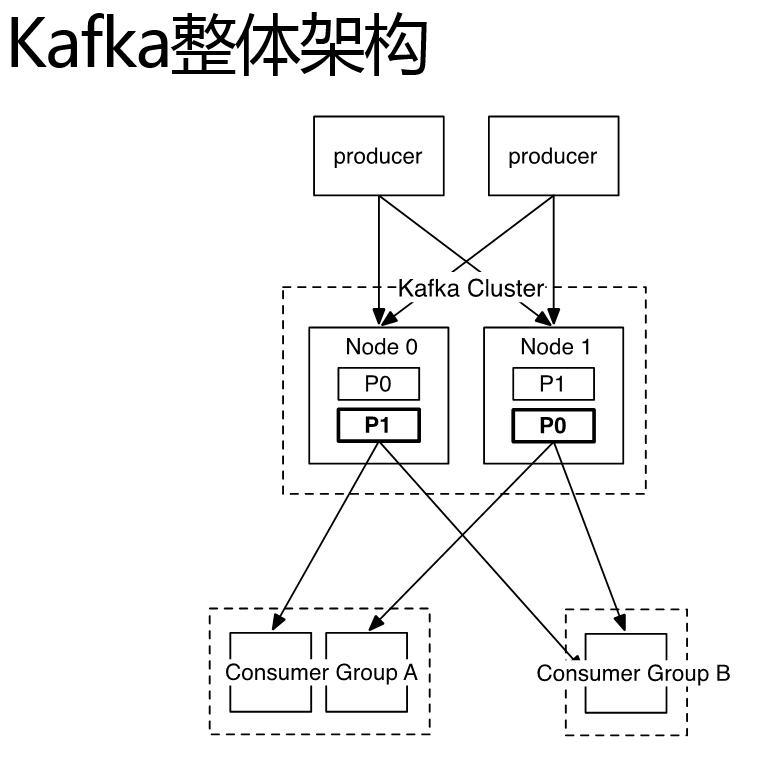
上图中:producer表示生产者,Consumer Group表示消费者的组
Kafka Cluster表示Kafka集群,Node1,Node2表示Kafka不同的节点
P0表示partition0,P1表示partition1
再看一个Kafka的架构图
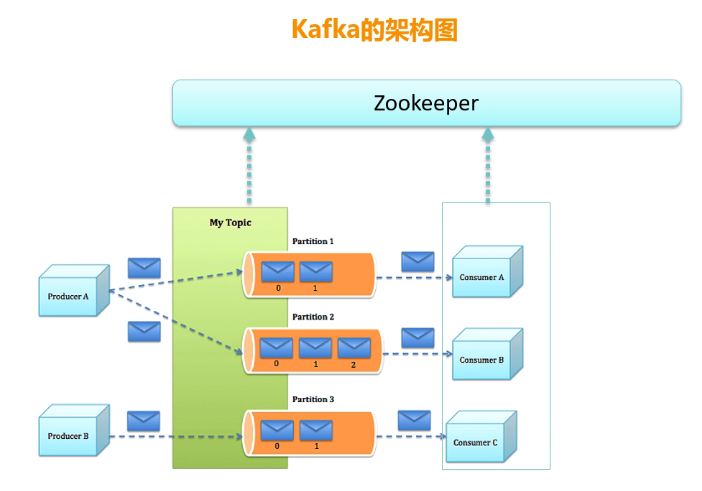
消息有key、value两部分组成,key和value都是byte数组。
key可以不写,不指定key为null
key根据不同的策略做消息路由 (同一个key到不同的分区)
Topic是用于存储消息的逻辑概念,可以看作一个消息集合。每个topic可以有多个生产者向其推送消息,也可以有任意多个消费者消费其中的消息。
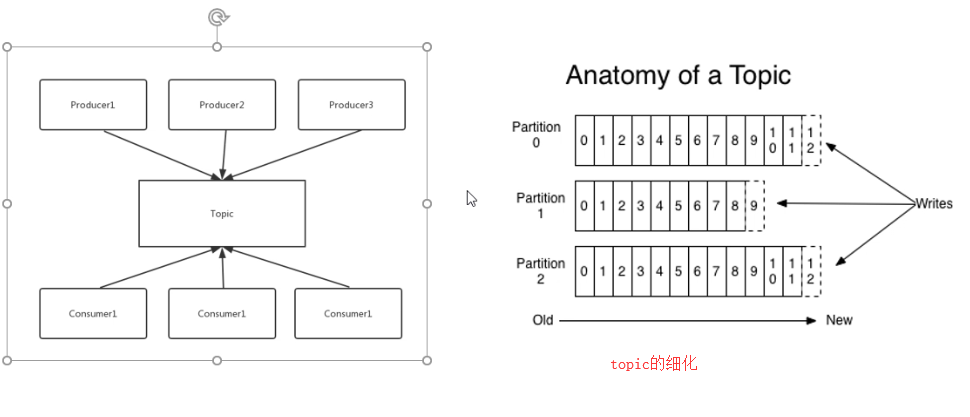
1)分区的原因
(1)方便在集群中扩展,每个Partition可以通过调整以适应它所在的机器,而一个topic又可以有多个Partition组成,因此整个集群就可以适应任意大小的数据了;
(2)可以提高并发,因为可以以Partition为单位读写.
2)分区的原则
(1)指定了patition,则直接使用;
(2)未指定patition但指定key,通过对key的value进行hash出一个patition
(3)patition和key都未指定,使用轮询选出一个patition。
每个topic可以划分多个分区(每个Topic至少有一个分区),同一topic下的不同分区包含的消息是不同的。每个消息在被添加到分区时,都会被分配一个offset(称之为偏移量),它是消息在此分区中的唯一编号,kafka通过offset保证消息在分区内的顺序,offset的顺序不跨分区,即kafka只保证在同一个分区内的消息是有序的;
offset就是 partition当中的0,1,2,3 …
如果offset=3,读完消息后 offset会递增
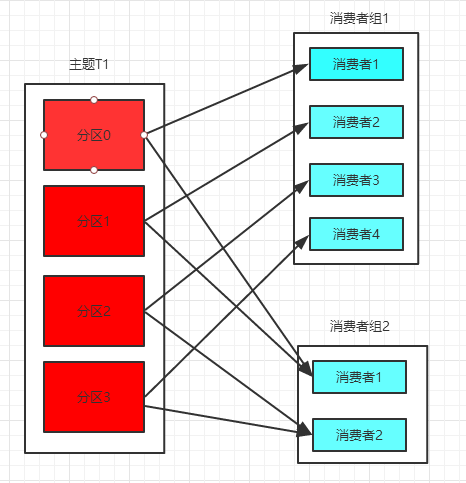
注意:
一个主题可以被多个组消费
一个主题的一个分区只能被一个组的一个消费者消费
一个主题可以被一个组反复消费,只要消息没有被删除
小结:
一个Kafka服务器对应一个Broker,一个Broker可以有很多topic,一个topic又有很多partition,partition在其他的broker上又有备份
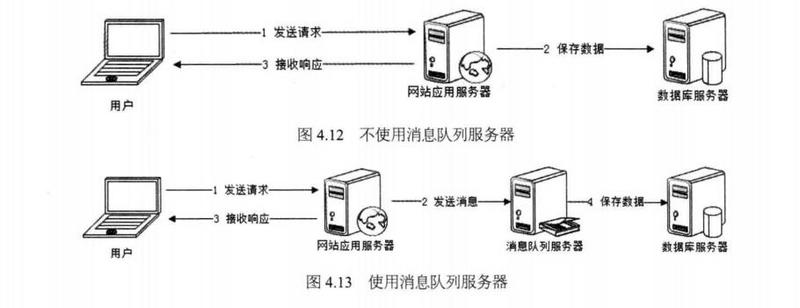
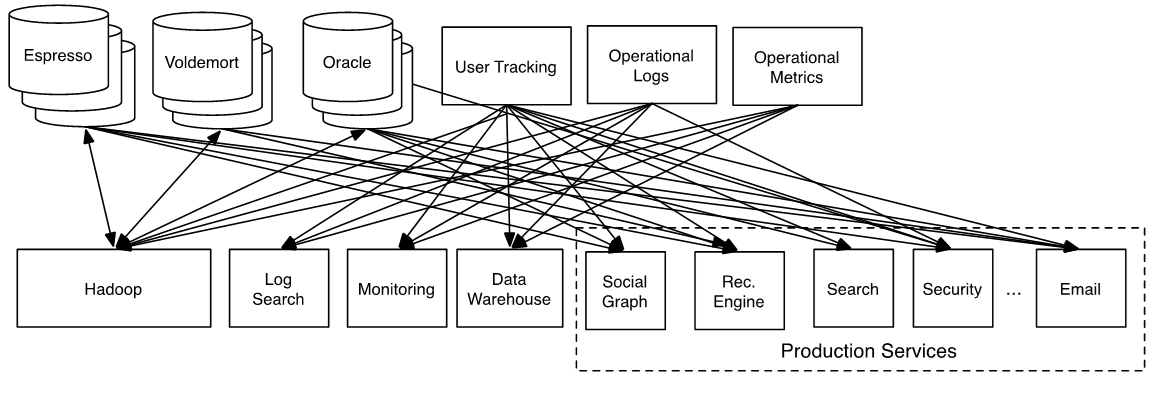
不好的系统架构:
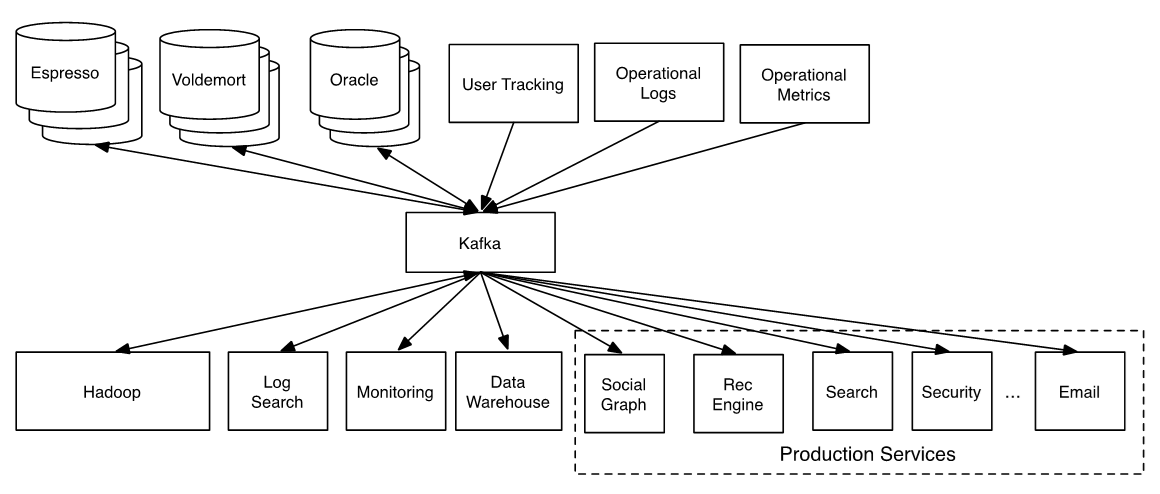
好的系统架构(用了Kafka):

Kafka可以顺序读写 每秒600M
Kafka的集群可以动态增减节点,伸缩性
可以轻松处理巨大的消息流,具有很好的性能和吞吐量
需要关注的问题:
分组策略
partition数量和broker数量关系
每个partition的数据如何存到硬盘
消费者负载均衡策略
如何保证消费者消费的数据是有序的
如何保证数据的完全生产(落在磁盘上)
消费者如何标记消费状态
Kafka有什么独特的特点
转载请注明:汪明鑫的个人博客 » 消息队列之初探Kafka

说点什么
您将是第一位评论人!