目录
持久化
redis是基于内存存储的高性能k-v中间件
目前已经是业界主流
基于内存存储也需要持久化,因为基于内存存储的数据具有断电易失性
因此需要数据从内存以某种形式保存在磁盘上
两种策略
- RDB (Redis DB)
- AOF (AppendOnlyFile)
RDB
快照形式保存数据
RDB是经过压缩的二进制文件,可以通过定时备份rdb文件来实现redis数据的备份
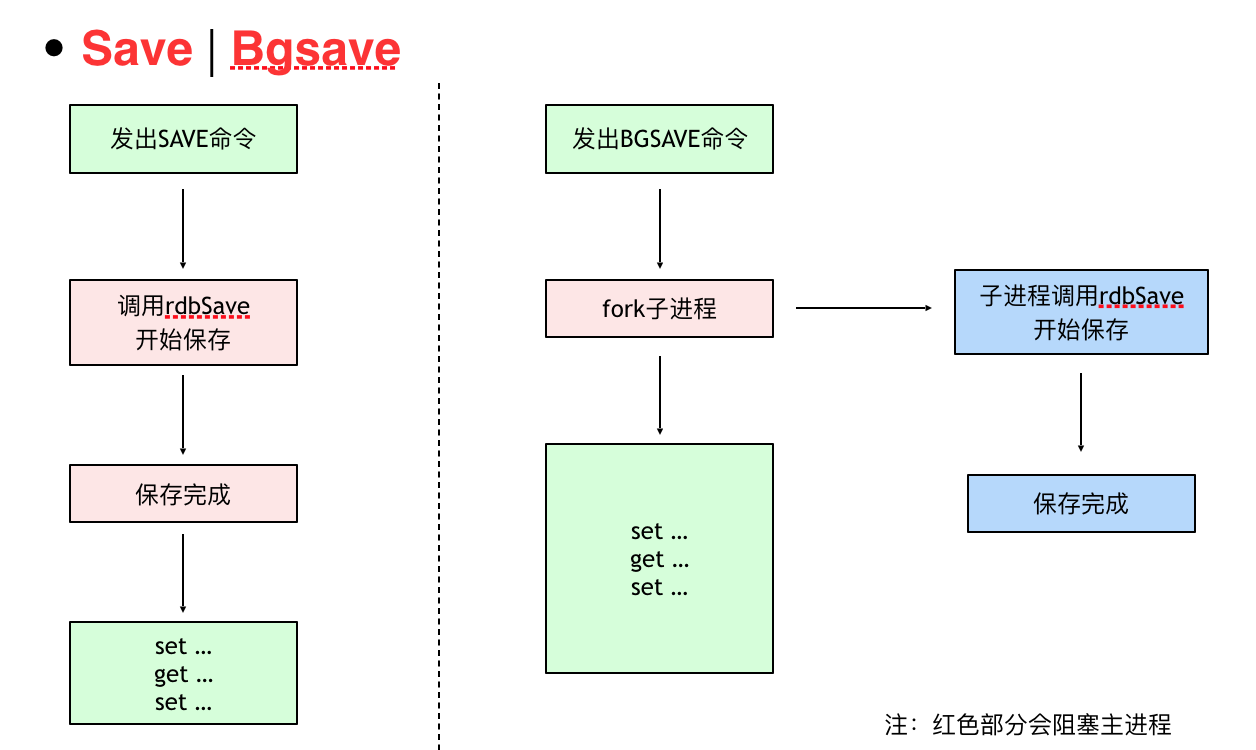
- save: 执行内存的数据同步到磁盘的操作,这个操作会阻塞客户端的请求
- bgsave: 在后台异步执行快照操作,这个操作不会阻塞客户端的请求 fork一个子进程
- 自动:按照配置文件中的条件满足就执行BGSAVE (自己配置快照规则,也有默认的配置)
如 save 60 1000,Redis要满足在60秒内至少有1000个键被改动,会自动保存一次
- 手动:客户端手动自行发起SAVE、BGSAVE命令
SAVE不用创建新的进程,速度略快BGSAVE需要创建子进程,消耗额外的内存SAVE适合停机维护,服务低谷时段BGSAVE适合线上执行
RDB可以最大化Redis的性能:父进程在保存RDB文件时唯一要做的就是fork出一个子进程,然后这个子进程就会处理接下来的所有保存工作,父进程无序执行任何磁盘I/O操作。同时这个也是一个缺点,如果数据集比较大的时候,fork可以能比较耗时,造成服务器在一段时间内停止处理客户端的请求
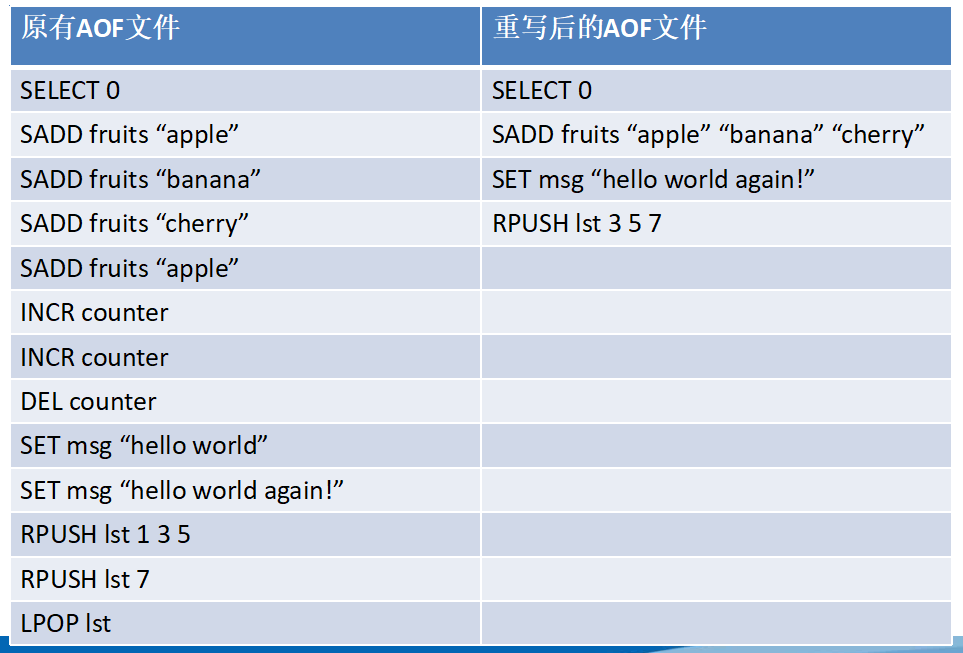
AOF

redis-check-aof工具修复 (redis自带的,没亲测过=-=)
什么时候记录命令到aof文件中?
是实时的,来一条命令追加一次吗
这个也可以自己来配置
appendfsync always 每次执行写入都会进行同步 , 这个是最安全但是效率低,影响redis性能appendfsync everysec 每一秒执行appendfsync no 不主动进行同步操作,由操作系统去执行,这个是最快但是最不安全的方式
AOF 把操作命令以简单易懂的格式一条接一条的保存在文件里,很容易导出来用于恢复数据。例如我们不小心用 FLUSHALL 命令把所有数据刷掉了,只要文件没有被重写,我们可以把服务停掉,把最后那条命令删掉,然后重启服务,这样就能把被刷掉的数据恢复回来。
RDB vs AOF
RDB是全量的快照,AOF是增量的追加
RDB性能稍好,但数据可能会丢失,
fork 子进程进行数据的持久化,如果数据大的话可能就会花费较多时间,影响redis性能;
使用rdb做冷备恢复速度更快,且易于传输
AOF比RDB可靠,制定不同的同步策略,甚至可以甚至成来一条命令就记录
在相同的数据集下,AOF 文件的大小一般会比 RDB 文件大。
一般推荐使用RDB和AOF混合方式,结合双发的优点
具体的使用细节,带我以后调研实操下再说吧,实践出真知
现阶段主要经理用在理论的学习和知识的梳理
Redis 4.0 开始支持 RDB 和 AOF 的混合持久化(默认关闭,可以通过配置项 aof-use-rdb-preamble 开启)。如果把混合持久化打开,AOF 重写的时候就直接把 RDB 的内容写到 AOF 文件开头。这样做的好处是可以结合 RDB 和 AOF 的优点, 快速加载同时避免丢失过多的数据。当然缺点也是有的, AOF 里面的 RDB 部分就是压缩格式不再是 AOF 格式,可读性较差。
Fork time in different systems
不同系统fork的时间
However the good news is that new types of EC2 HVM based instances are much better with fork times, almost on par with physical servers, so for example using m3.medium (or better) instances will provide good results.
- Linux beefy VM on VMware 6.0GB RSS forked in 77 milliseconds (12.8 milliseconds per GB).
- Linux running on physical machine (Unknown HW) 6.1GB RSS forked in 80 milliseconds (13.1 milliseconds per GB)
- Linux running on physical machine (Xeon @ 2.27Ghz) 6.9GB RSS forked into 62 milliseconds (9 milliseconds per GB).
- Linux VM on 6sync (KVM) 360 MB RSS forked in 8.2 milliseconds (23.3 milliseconds per GB).
- Linux VM on EC2, old instance types (Xen) 6.1GB RSS forked in 1460 milliseconds (239.3 milliseconds per GB).
- Linux VM on EC2, new instance types (Xen) 1GB RSS forked in 10 milliseconds (10 milliseconds per GB).
- Linux VM on Linode (Xen) 0.9GBRSS forked into 382 milliseconds (424 milliseconds per GB).
转载请注明:汪明鑫的个人博客 » Redis 持久化策略

说点什么
您将是第一位评论人!