目录
前言
分库分表存在的意义在于单库单表已经远远不能支撑当前互联网的大数据量和高并发场景下!
因此无敌前辈们就想出了各种优化库优化表的方案,解决系统数据库层面出现的瓶颈
分库分表在公司中的实践也是面试官往往爱问的
如果你对公司中的分库分表还一点不了解的话,赶紧去找相关文档和系统瞅两眼哈
虽然我们是CURD砖家 ?, 但也要怀揣梦想。。。
什么是分库
顾名思义,一个库变多个库 ,多重影分身之术
玩法有很多,比如一个数据库服务器新建几个数据库
或者多弄几个数据库服务器,一个服务器实例部署一个数据库
也可以搭建主从数据库,双主数据库等等
可以根据业务拆成多个数据库,垂直分库,把打到一台数据库的量打到多台!
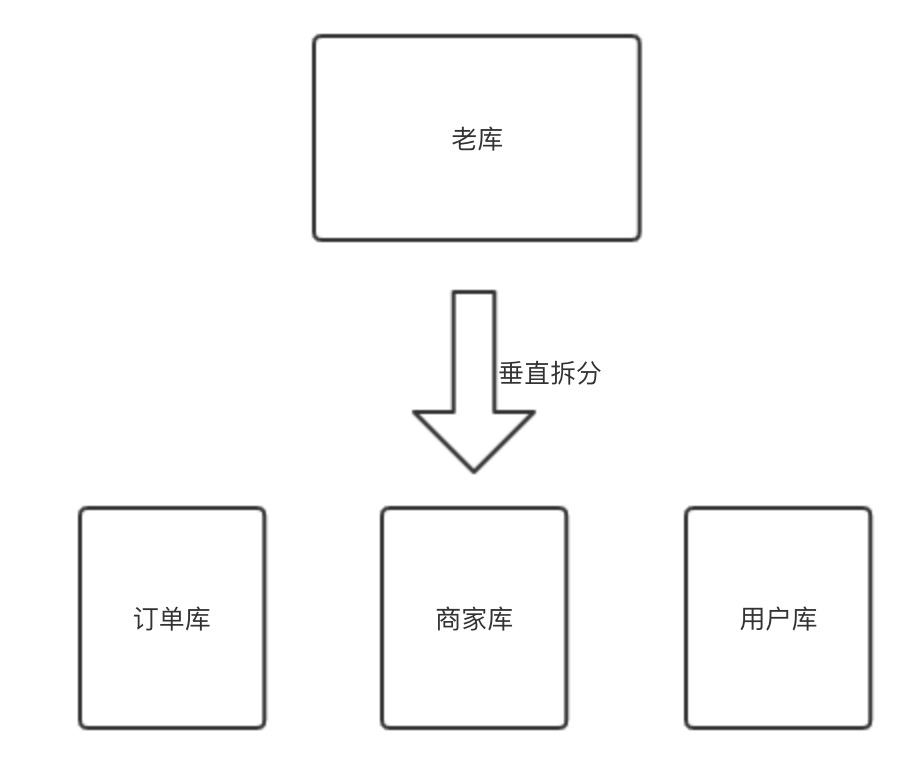
当然你的多个数据库可以是完全一样的,一样的表结构
然后比如一笔订单来了,按照某个属性做hash打到具体的数据库
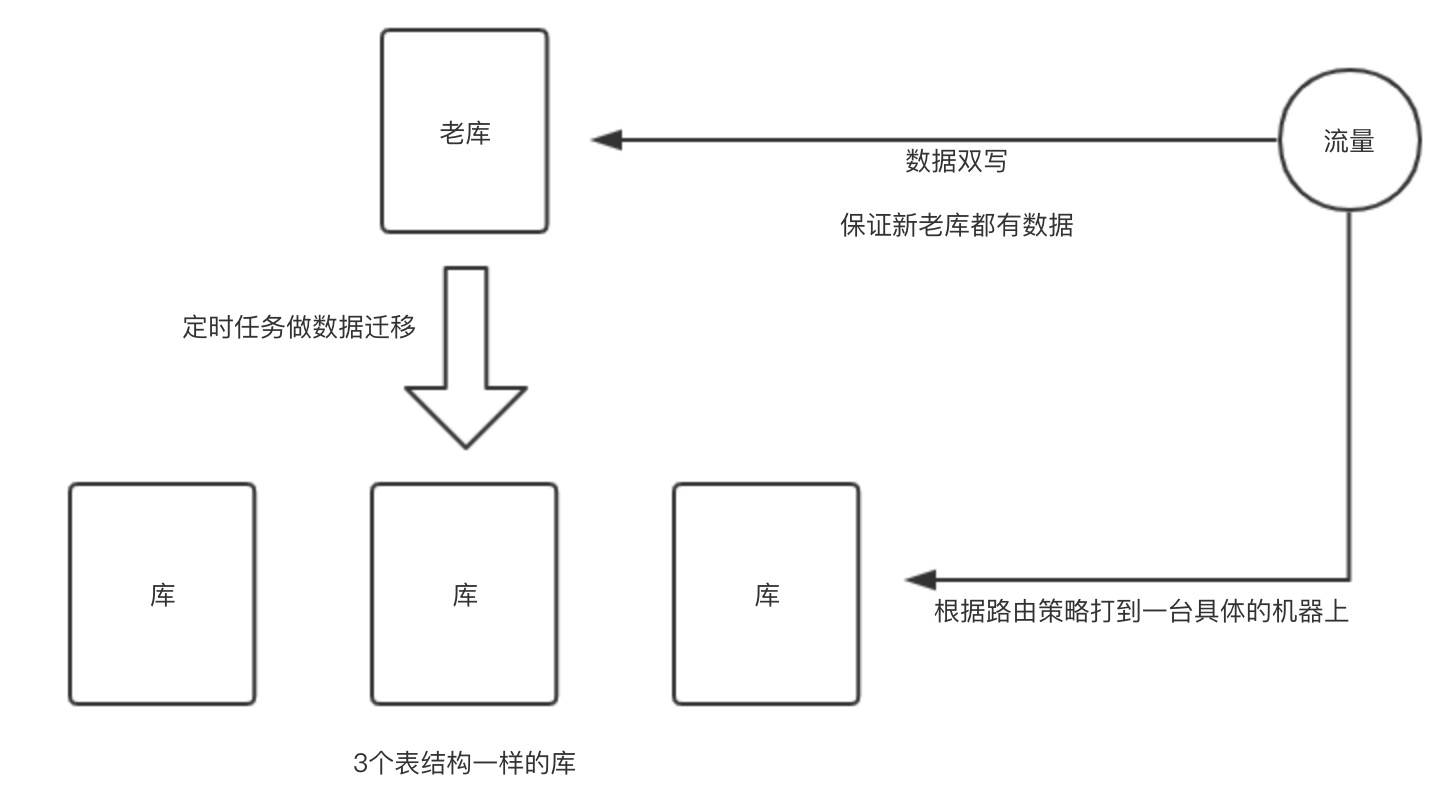
用了分库需要考虑的事情:全局唯一ID,跨库事务等等
中间劈一刀即是垂直分表
表的列太多,或者太多冗余字段
可以进行垂直分表
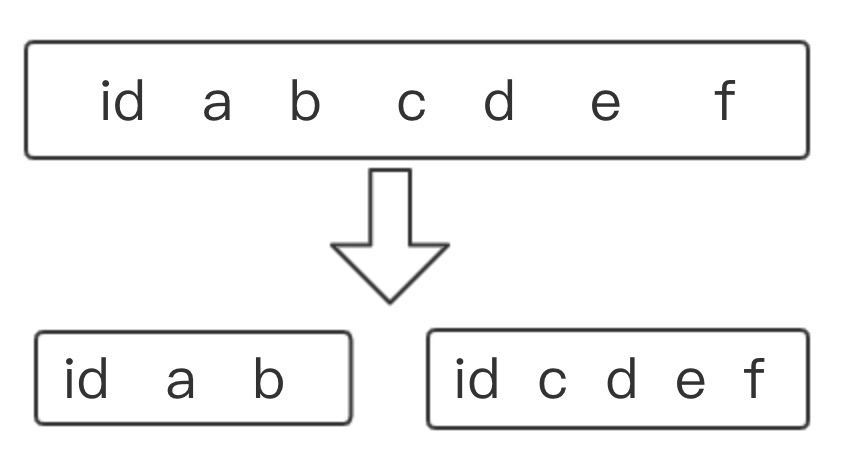
垂直分表可以解决跨页的问题。字段少的情况下,原本一行数据只需要存在一个页里面就行了,但是字段多的情况就存不下了,就需要跨页。这样就会造成额外寻址,造成性能上的开销。另外将这么长的一行数据载到内存中,往往是几个页面,结果咱们经常只访问其中的几个字段,对内存也是一个极大的开销。所以为了让内存缓存更多数据,减少磁盘I/O,垂直分表就是很好的手段。
减少和磁盘的交互次数!
表行数真的扛不住啊
表的行数超过千万行,性能已经感觉明显的下降
我们采用水平分表解决这个问题
水平分表对表的性能是一个巨大的提升
可以按hash分表,也可以按range分表
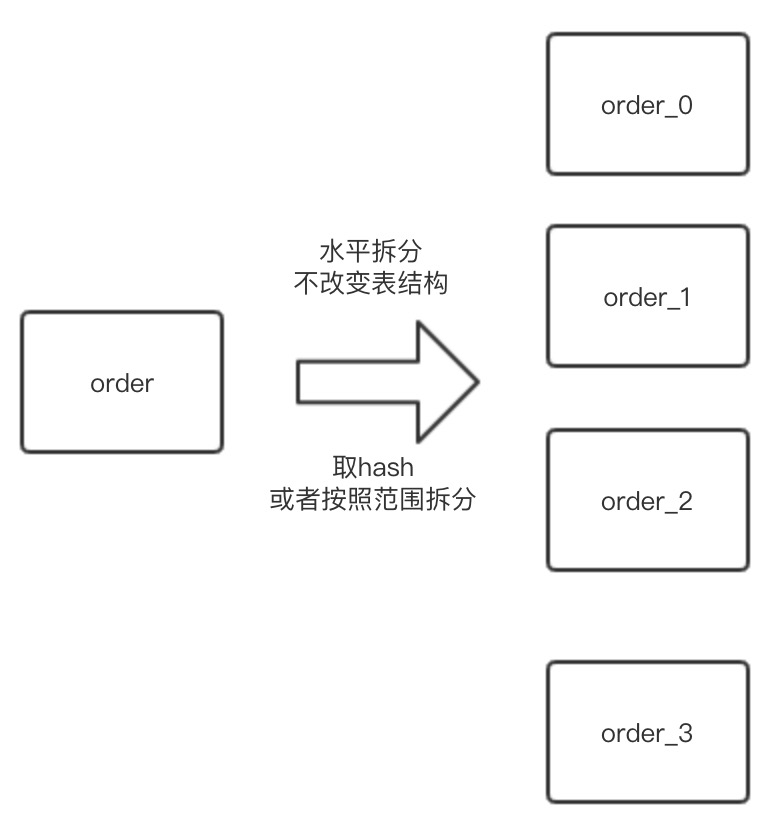
水平分表需要选择一个sharding key
按照这一维度把数据具体路由到某一张表
但又回引发一个问题,比如你的分片键是orderId
当你需要查询一个商家下的订单就会出现跨多个分片查询,影响效率!
跨分片查询的原理:通过线程池并发请求到所有符合路由规则的目标分表,然后对所有结果进行归并。
分库分表中间件
2种模式:
- Client模式 jar包的形式
- Proxy 模式 独立的部署的形式 代理服务
有mycat,tddl,sharding-JDBC等等
一般分库分表都会借助分库分表中间件来一起搞
关于数据库中间件的更多细节和实践后面再搞
饿了么分库分表实践
数据库中间件 :DAL
数据库是和其他服务的库混合部署,没有独占服务器实例
大概有32个数据库实例,分南北2个机房,也有主从集群,再细节的看不到了。。。
表分片:
分片数 512
默认是sharding表 可以自己选择分片键(以某种纬度)
我们的老表用的是商户id
重构后的新表用的是订单id
3个月会对表中的数据进行一个清除,不清除可以归档,会被数据仓库的同学把历史数据抽到大数据平台
转载请注明:汪明鑫的个人博客 » 为什么需要分库分表呢

说点什么
您将是第一位评论人!