目录
为何需要分布式链路追踪
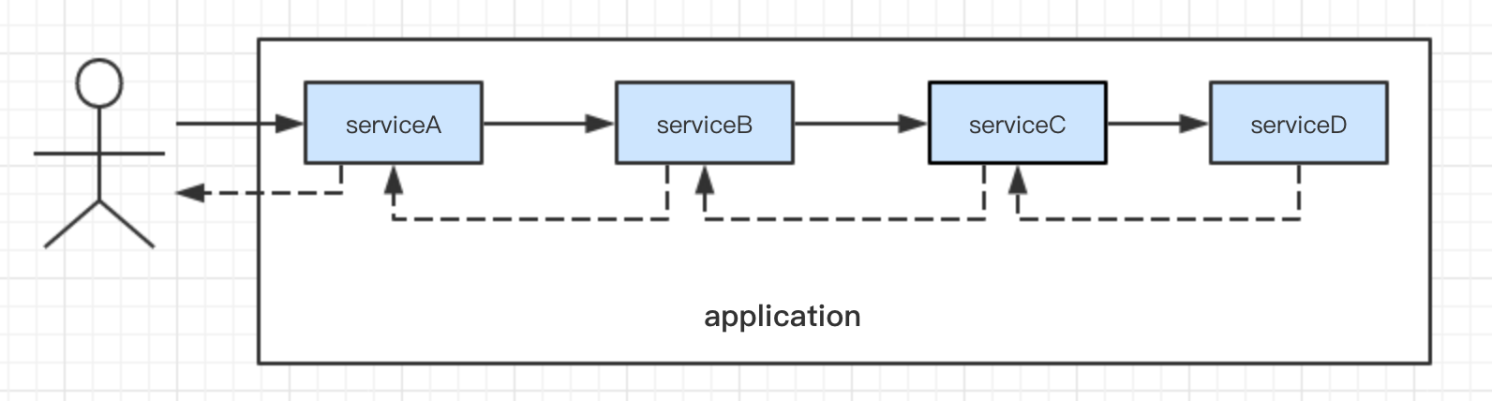
单机场景下定位常规调用问题往往不是很困难
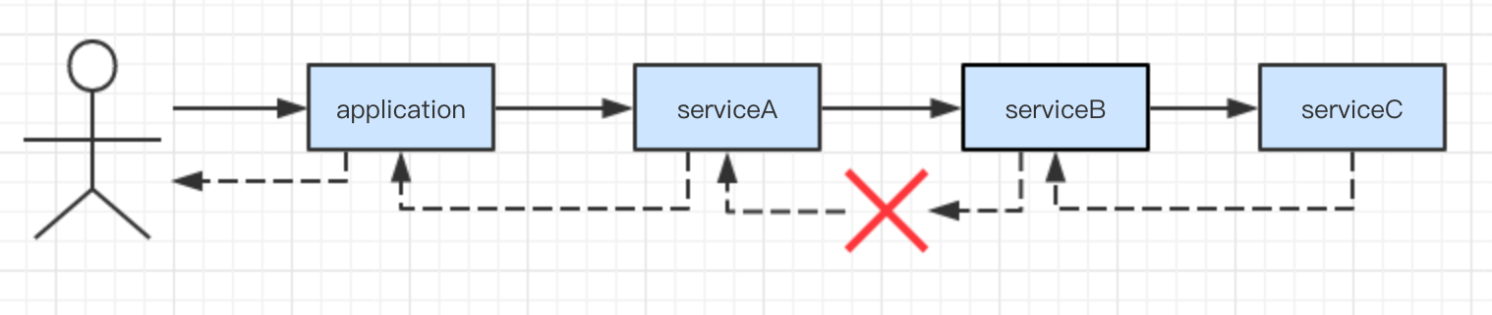
分布式场景下,链路复杂,定位问题较为困难
需要一个统一的分析调用信息的平台
微服务并不理想化,调用关系复杂,维护成本极高

故障定位难,链路梳理难,容量预估难,资源浪费多
分布式链路追踪系统迫在眉睫!
分布式链路追踪定义
现有的分布式Trace基本都是采用了google 的Dapper标准
http://bigbully.github.io/Dapper-translation/
Dapper的思想就是在每一次调用栈中,使用同一个TraceId将不同的server联系起来
在微服务架构体系下,记录一个请求先后(时序)访问了哪些组件或者服务,以及请求方法、耗时、被访问的节点信息等信息。
用于帮助性能分析、问题排查。
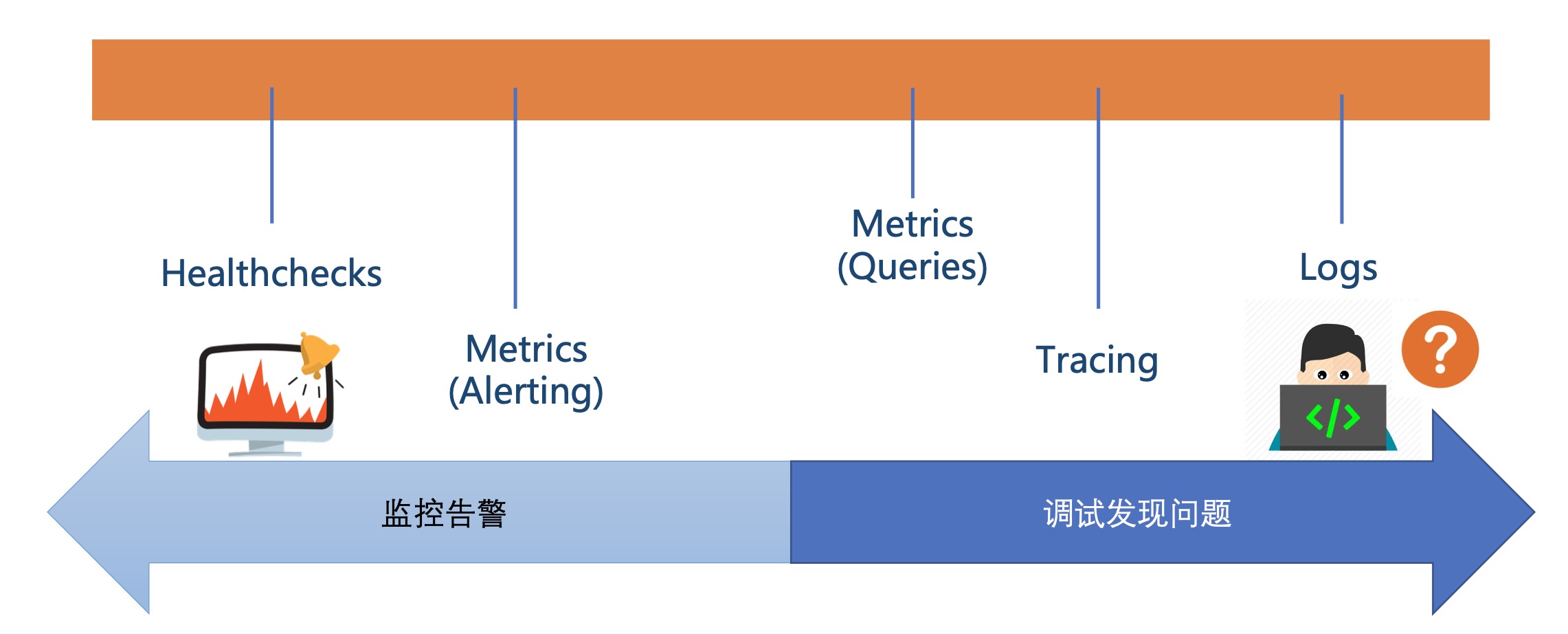
分布式链路追踪系统基本能力
- 埋点数据收集,负责在服务端进行埋点,来收集服务调用的上下文数据。
- 实时数据处理,负责对收集到的链路信息,按照traceId和spanId进行串联和存储。
- 数据链路展示,把处理后的服务调用数据,按照调用链的形式展示出来
基础功能:
跟踪每个请求的完整调用链
收集调用链每个服务的执行耗时,整合孤立日志
目标:
低侵入性
时效性
可配置
可视化
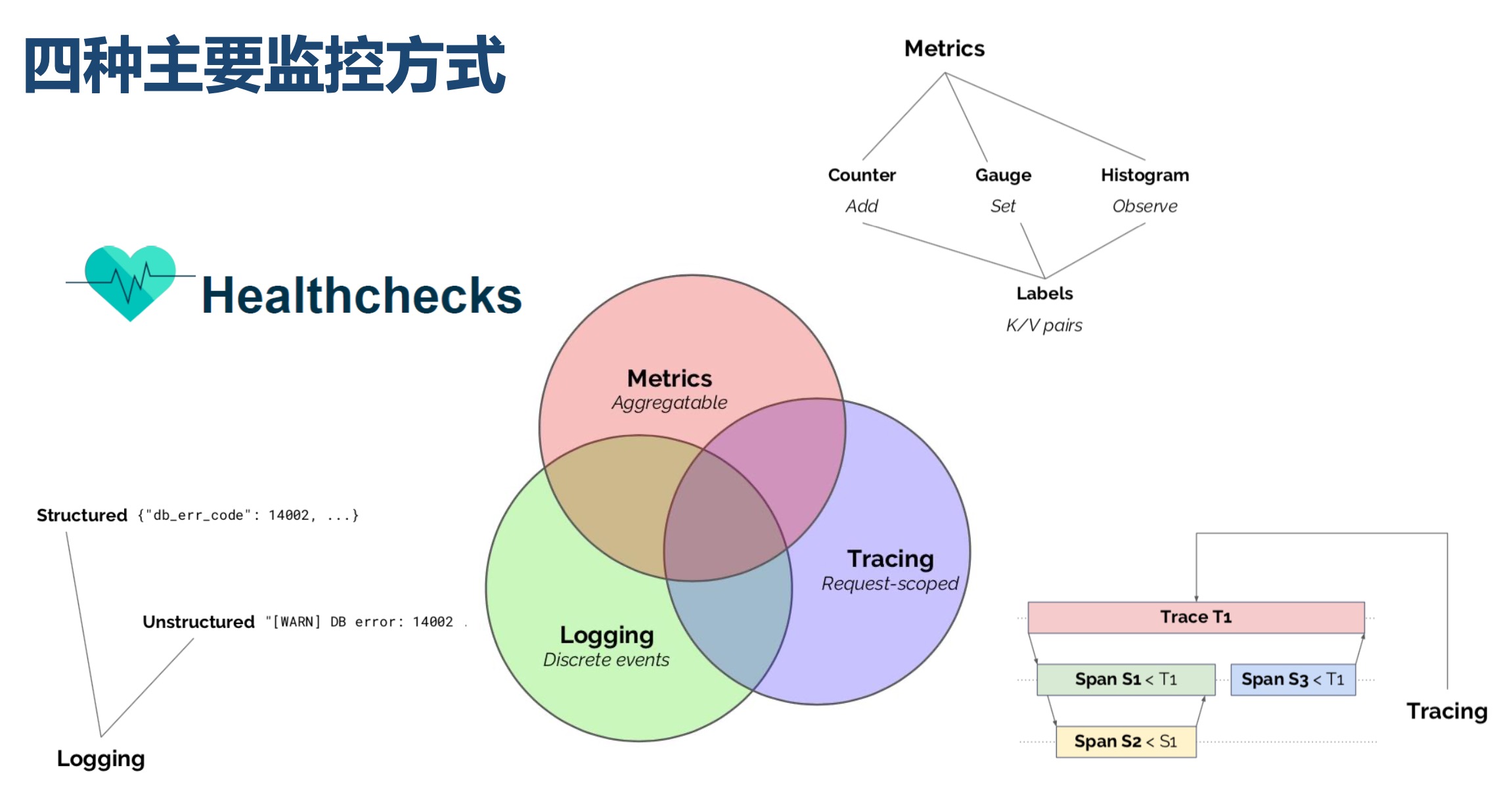
OpenTracing
首先来解释下 OpenTracing 是什么OpenTracing 致力于为分布式跟踪创建更标准化的API和工具,它由完整的API规范、实现该规范的框架、库以及项目文档组成。
OpenTracing 提供了一套平台无关、厂商无关的 API,这样不同的组织或者开发人员就能够更加方便的添加或更换追踪系统的实现。
OpenTracing API 中的一些概念和术语,在不同的语言环境下都是共享的。
【Child】
在 methodA 中调用了 method B :
methodA(){ // spanA start methodB(); } // spanA finish methodB(){ // spanB start } // spanB finish
产生的 span 在时间维度上展现的视角如下:

表示为 SpanB ChildOf SpanA
【Follow】
method 方法中,methodA 执行之后 methodB 执行 :
method(){ methodA(); methodB(); }
产生的 span 在时间维度上展现的视角如下:

这种关系一般会 表示为 SpanB FollowFrom SpanA
Tracing的概念
核心概念:
- Span:请求中的一个具体工作单元。如一次rpc服务调用、一次mysql访问
- Trace:表示一次请求的完整链路,由多个Span组成的调用树
TraceId 串起一次完整的请求,形成一个Trace
SpanId 标记每一个Span过程,代表服务的调用顺序,
ParentSpanId明确Trace中服务的依赖关系。
SpanId会随着每一次服务调用递增
一般采集的数据信息包括TraceID、SpanID和ParentSpanID、RpcContext中包含的数据信息、服务执行异常时的堆栈信息、
以及Trace中各个Span过程的开始和结束时间,这些数据信息都是需要在Trace的上下文信息中进行传递的。
Trace的含义比较直观,就是链路,指一个请求经过后端所有服务的路径,可以用下图表示
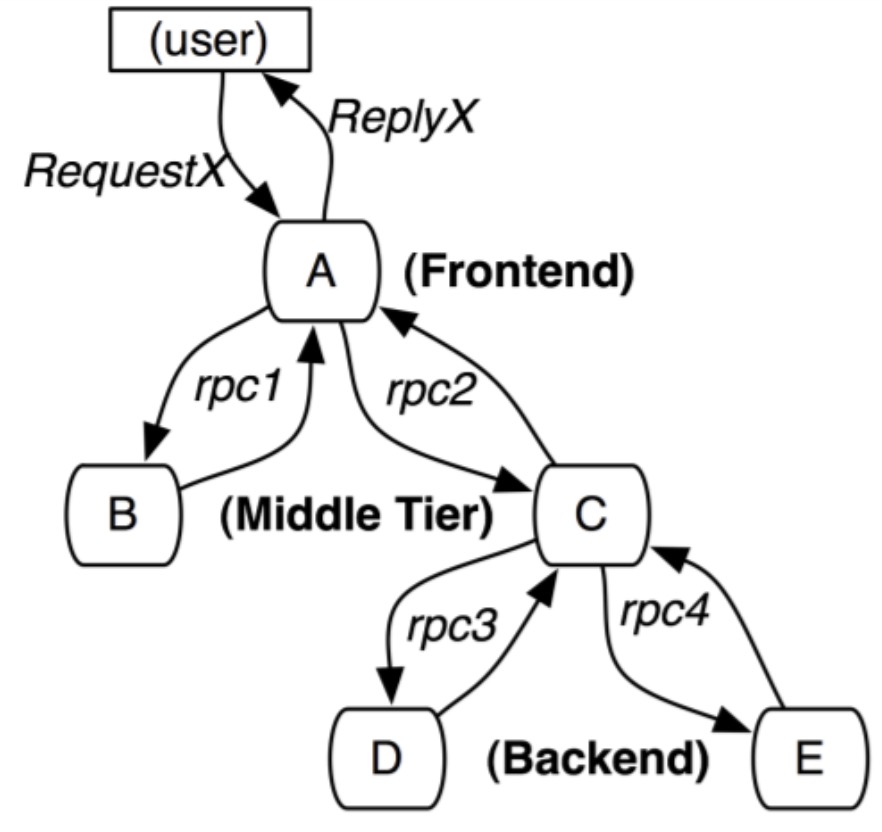
pan之间存在着父子关系,上游的span是下游的父span
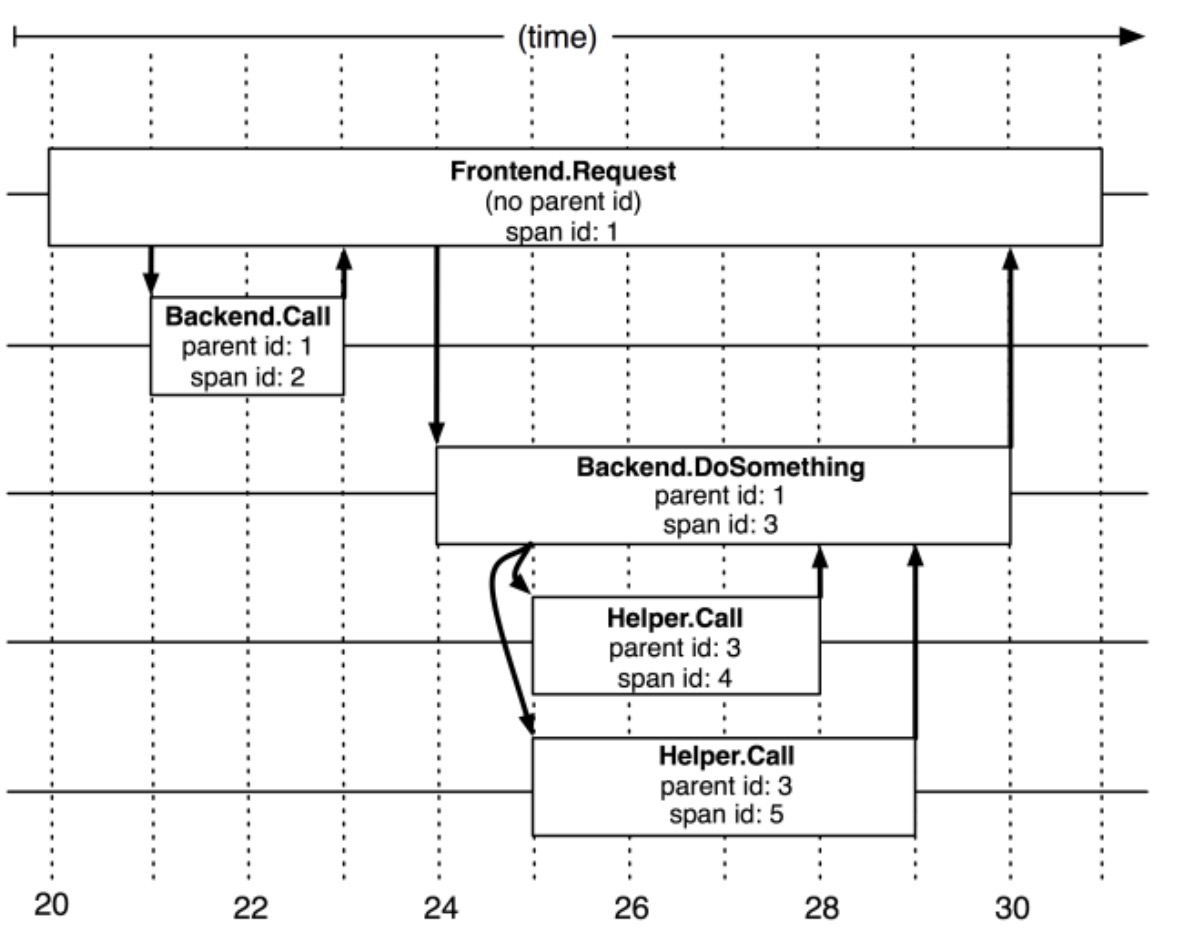
spanId 图示
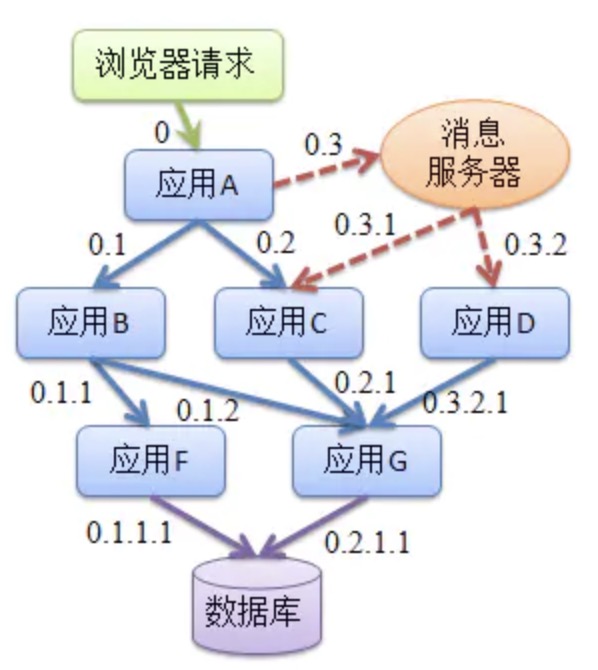
链路信息传递
链路的构建一般是 client-server-client-server 这种模式的,
就是会在 client 端进行注入,然后再 server 端进行提取,反复进行,然后一直传递下去
大体流程:
- 从请求中提取trace上下文
- 构建 Span,并将当前 Span 存入当前 trace上下文中
- 设置一些信息到 Span 中
- 返回响应
- Span 结束&上报
业界产品
Twitter的 Zipin
SkyWalking [http://skywalking.apache.org/]
阿里 鹰眼
蚂蚁金服 sofa-tracer [https://github.com/sofastack/sofa-tracer]
大众点评 Cat [https://github.com/dianping/cat]

说点什么
您将是第一位评论人!