目录
redis 分布式锁 vs zk 分布式锁
个人觉得redis 命令和运维更简单
zk还是有一定的学习成本,还要部署zk集群
redis分布式锁,其实需要自己不断去尝试获取锁,比较消耗性能
zk分布式锁,获取不到锁,注册监听器,不需要不断主动尝试获取锁,性能开销较小
redis获取锁的那个客户端bug了或者挂了,那么只能等待超时时间之后才能释放锁;
而zk的话,因为创建的是临时znode,只要客户端挂了,znode就没了,此时就自动释放锁(临时有序节点)
redis实现分布式锁的一些问题
主要命令是setnx 和 expire 没错
还需要注意几个问题
客户端去争抢锁还需要指定一个timeout,过了超时时间
获取锁在指定一个ttl,即过期时间,客户端持有锁超过一定时间需要释放锁,防止一直占用服务资源
还有一个点就是客户端主动释放锁的delete方法,讲道理每个客户端都可以调用delete,怎么保证锁不被其他客户端删掉呢?
下面我们看下实现方法,再来分析:
/**
* redis分布式锁的实现代码
*/
public class DistributedLock {
private final JedisPool jedisPool;
public DistributedLock(JedisPool jedisPool) {
this.jedisPool = jedisPool;
}
/**
* 加锁
* @param lockName 锁的key
* @param acquireTimeout 获取超时时间
* @param timeout 锁的超时时间
* @return 锁标识
*/
public String lockWithTimeout(String lockName, long acquireTimeout, long timeout) {
Jedis conn = null;
String retIdentifier = null;
try {
// 获取连接
conn = jedisPool.getResource();
// 随机生成一个value
String identifier = UUID.randomUUID().toString();
// 锁名,即key值
String lockKey = "lock:" + lockName;
// 超时时间,上锁后超过此时间则自动释放锁
int lockExpire = (int) (timeout / 1000);
// 获取锁的超时时间,超过这个时间则放弃获取锁
long end = System.currentTimeMillis() + acquireTimeout;
while (System.currentTimeMillis() < end) {
if (conn.setnx(lockKey, identifier) == 1) {
conn.expire(lockKey, lockExpire);
// 返回value值,用于释放锁时间确认
retIdentifier = identifier;
return retIdentifier;
}
// 返回-1代表key没有设置超时时间,为key设置一个超时时间
if (conn.ttl(lockKey) == -1) {
conn.expire(lockKey, lockExpire);
}
try {
Thread.sleep(10);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
} catch (JedisException e) {
e.printStackTrace();
} finally {
if (conn != null) {
conn.close();
}
}
return retIdentifier;
}
/**
* 释放锁
* @param lockName 锁的key
* @param identifier 释放锁的标识
* @return
*/
public boolean releaseLock(String lockName, String identifier) {
Jedis conn = null;
String lockKey = "lock:" + lockName;
boolean retFlag = false;
try {
conn = jedisPool.getResource();
while (true) {
// 监视lock,准备开始事务
conn.watch(lockKey);
// 通过前面返回的value值判断是不是该锁,若是该锁,则删除,释放锁
if (identifier.equals(conn.get(lockKey))) {
Transaction transaction = conn.multi();
transaction.del(lockKey);
List<Object> results = transaction.exec();
if (results == null) {
continue;
}
retFlag = true;
}
conn.unwatch();
break;
}
} catch (JedisException e) {
e.printStackTrace();
} finally {
if (conn != null) {
conn.close();
}
}
return retFlag;
}
}
先看 lockWithTimeout 方法
conn.setnx(lockKey, identifier) key为空set成功,如果已经存在则set失败
identifier 是key对应的value,是为获取锁的客户端生成的UUID,可以把他理解成你释放锁的一个凭证
conn.expire(lockKey, lockExpire) 就是给锁一个过期时间
也有方法支持set直接指定nx和ttl,redis操作能原子性还是原子性比较好
然后我们再来看一波释放锁的方法releaseLock
需要传一个字符串identifier ,这个identifier就是你释放锁的凭证,否则每个客户端都能释放锁就乱了
identifier 如果等于key对应的value,即上文中为获取锁的客户端生成的UUID,就可成功释放锁
否则释放锁失败
因此我们需要一次get操作 + 一个delete操作
试想如果get的时候ok,但是调用delete方法的时候,这把锁刚好过期了已经不属于当前客户端,而另一个客户端已经加锁成功,导致客户端删掉的其实是另一个客户端的锁。 (代码中是开启了redis是一个事务来保证操作原子性)
我们还有新的方案
lua 脚本保证释放锁的原子性(get + set 原子性)
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
【redis的问题】
单机的话解决不了单机故障问题,
主从复制会出现主从数据同步延迟问题,比如加锁到master,释放锁时读取slave没读到导致锁释放失败
还有各种问题。。。
RedLock
redis官方提供的分布锁方案
redis单机版和主从复制版都会存在一定问题
RedLock 是多主模式,多个master 同时对外提供服务
注意这里的redis 实例必须是大于2的奇数,且相互之间不进行数据同步,主要是为了避免了单点故障
1.获取当前时间(单位是毫秒)。
2.轮流用相同的key和随机值在N个节点上请求锁,在这一步里,客户端在每个master上请求锁时,会有一个和总的锁释放时间相比小的多的超时时间。比如如果锁自动释放时间是10秒钟,那每个节点锁请求的超时时间可能是5-50毫秒的范围,这个可以防止一个客户端在某个宕掉的master节点上阻塞过长时间,如果一个master节点不可用了,我们应该尽快尝试下一个master节点。
3.客户端计算第二步中获取锁所花的时间,只有当客户端在大多数master节点上成功获取了锁(N/2+1在这里是3个),而且总共消耗的时间不超过锁释放时间,这个锁就认为是获取成功了。
4.如果锁获取成功了,那现在锁自动释放时间就是最初的锁释放时间减去之前获取锁所消耗的时间。
5.如果锁获取失败了,不管是因为获取成功的锁不超过一半(N/2+1)还是因为总消耗时间超过了锁释放时间,客户端都会到每个master节点上释放锁,即便是那些他认为没有获取成功的锁。
感觉挺麻烦的。。。
关于etcd实现分布式锁
etcd 可以理解成和zk一样是一个中间价,支持集群,可存储数据,做为注册中心什么的,当然etcd也可以做分布式锁
和zk一样都是CP系统,
zk是基于zab协议(集群广播 + 崩溃恢复),
etcd是基于raft协议 (http://thesecretlivesofdata.com/raft/)
etcd也是存储类似redis给个key value ttl
还可以支持续租,意思是说redis ttl 到期了,就要释放锁
etcd 锁到期了还可以续租,延迟锁的时间,这一点还是很给力的
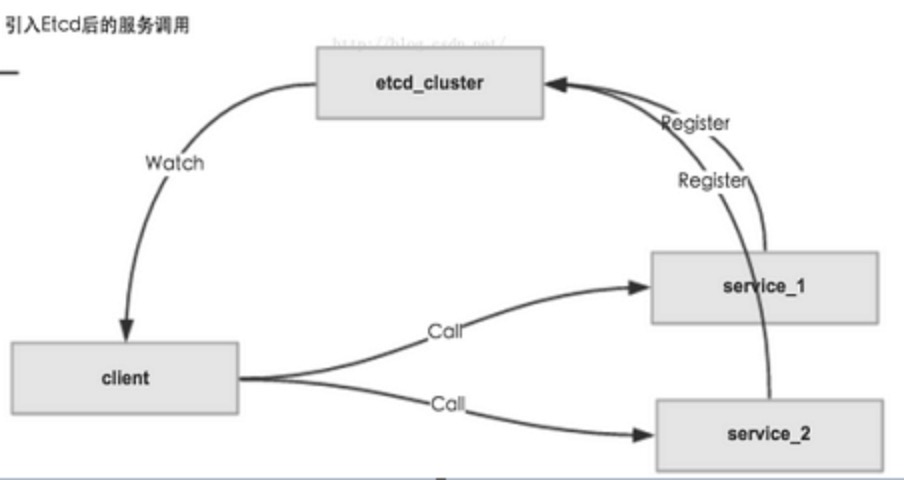
etcd 作为注册中心,也是类似zk做dubbo的注册中心
服务的注册和发现

说点什么
您将是第一位评论人!