本文简单介绍分布式共识算法 Raft
Raft存在的目的是为了解决分布式集群下数据不一致的问题
Raft主要有2个流程:
1)选主
2)数据同步
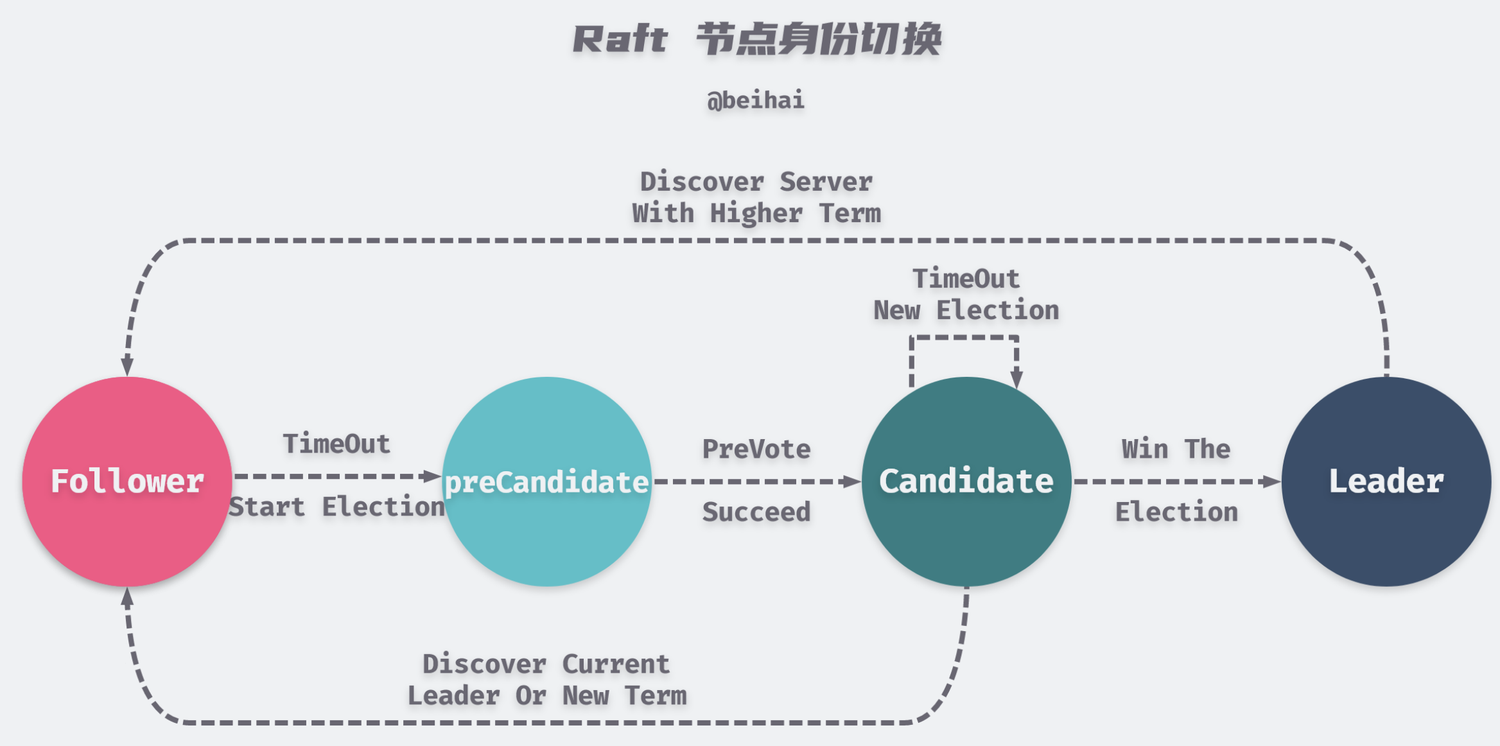
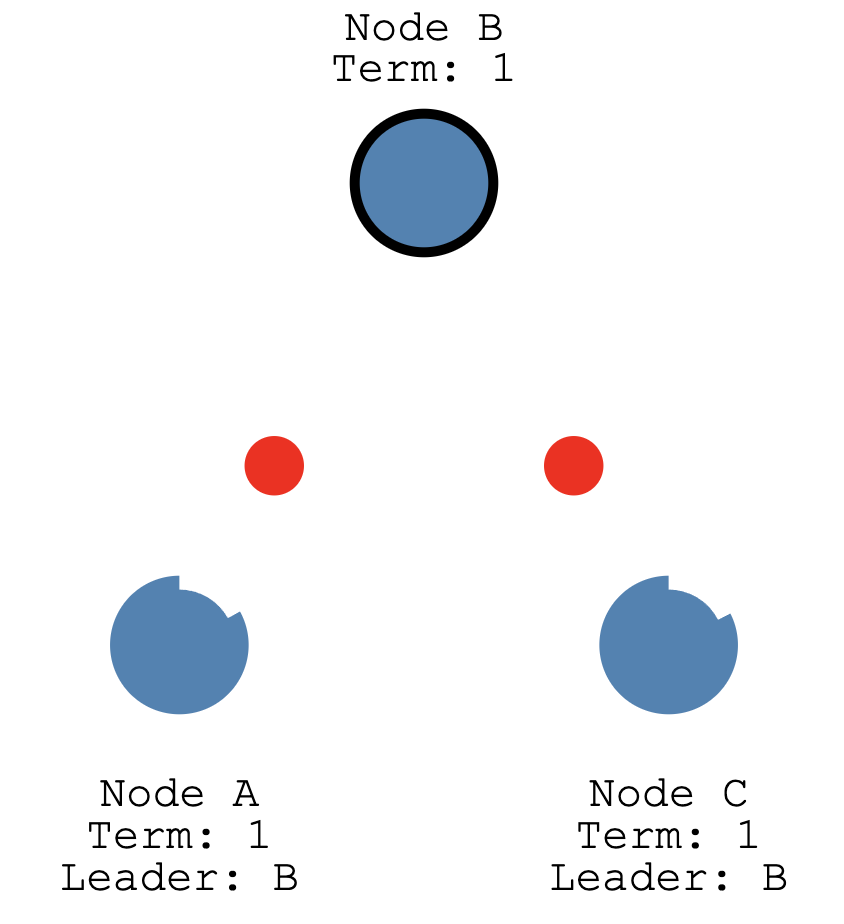
Raft集群节点身份见下图 网上扒的,比较清晰,
大概就是候选人,获得多数投票成为leader, 发现更高term的leader又会变成follower,先有个印象
有个网站把raft协议的动画整的比较好:
http://thesecretlivesofdata.com/raft/
先看选主的过程
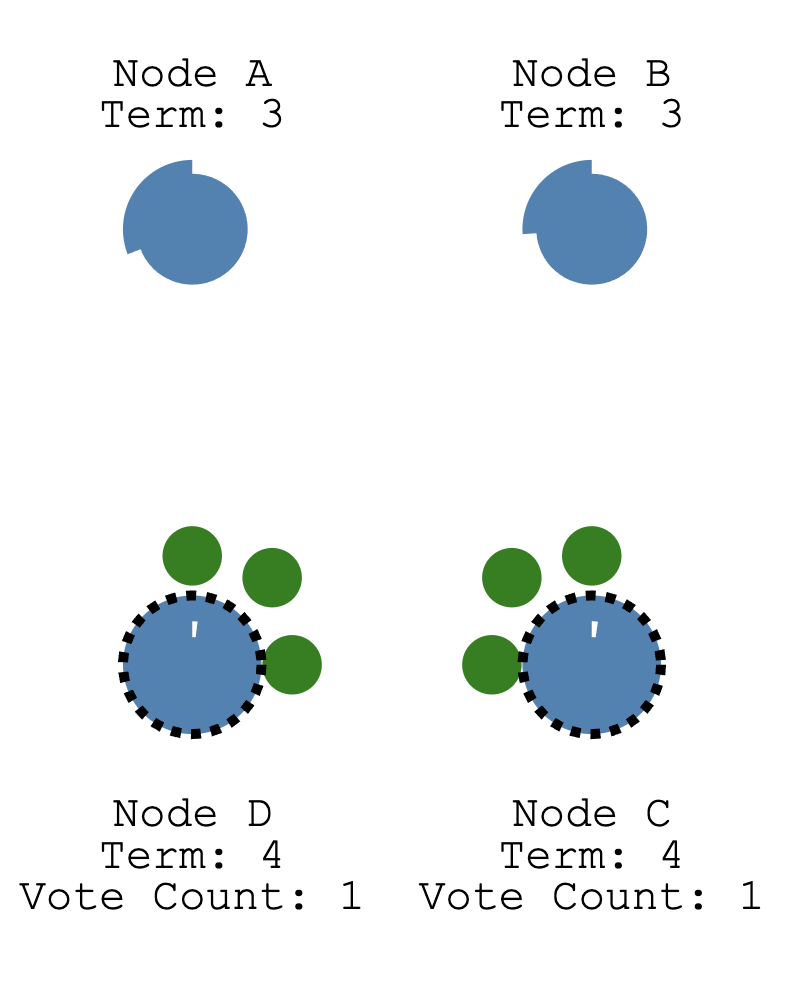
C和D竞争选主,在集群内广播
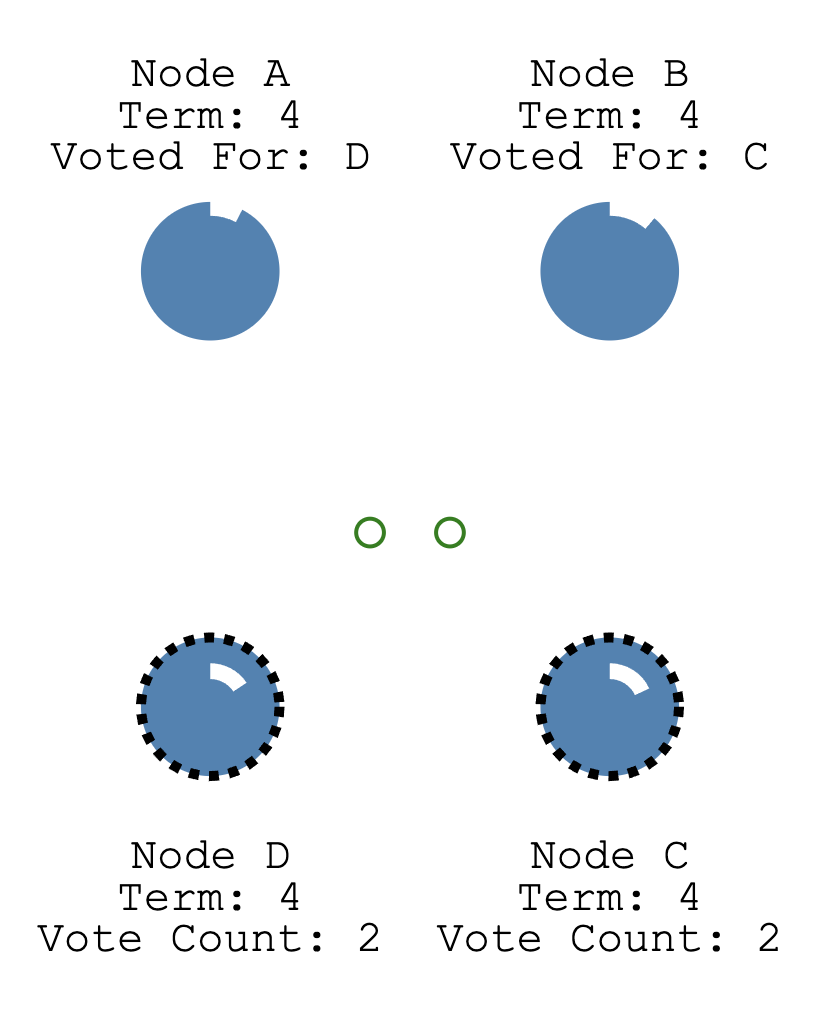
A给D投票,B给C投票,因此平票 (一般来说超过一半节点数量的得票会成为主,如果平票在zk的处理逻辑是选择主机id更小的记得是)
此时B在新的任期,广播自己要竞选主
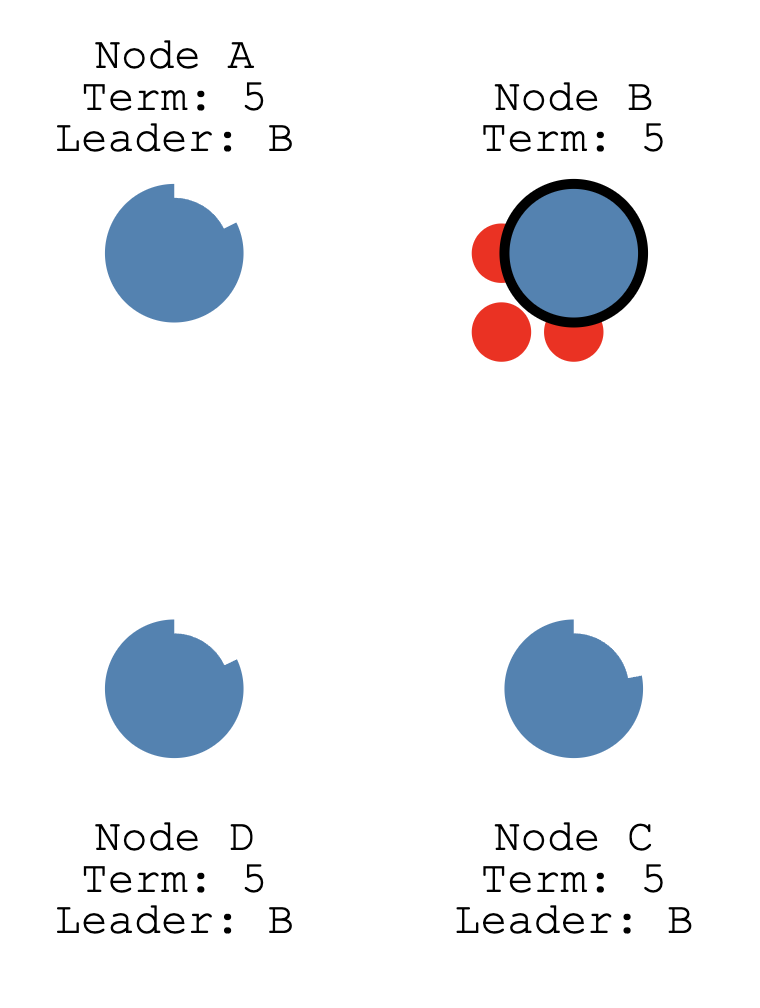
大家都投给了B ,B就成老大了
leader还会和各个节点保持周期的心跳
下一步看数据同步:
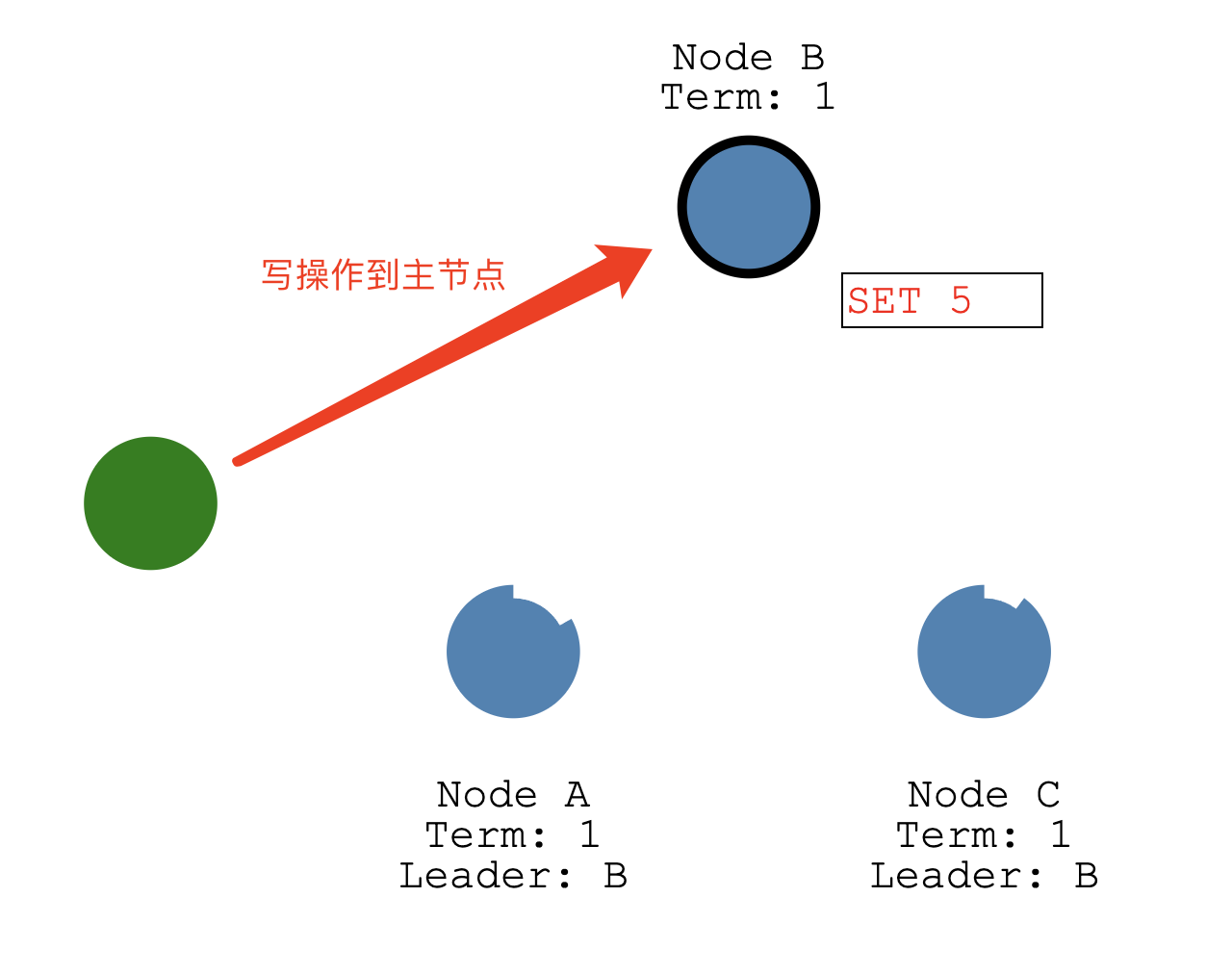
Once we have a leader elected we need to replicate all changes to our system to all nodes.
First a client sends a change to the leader.
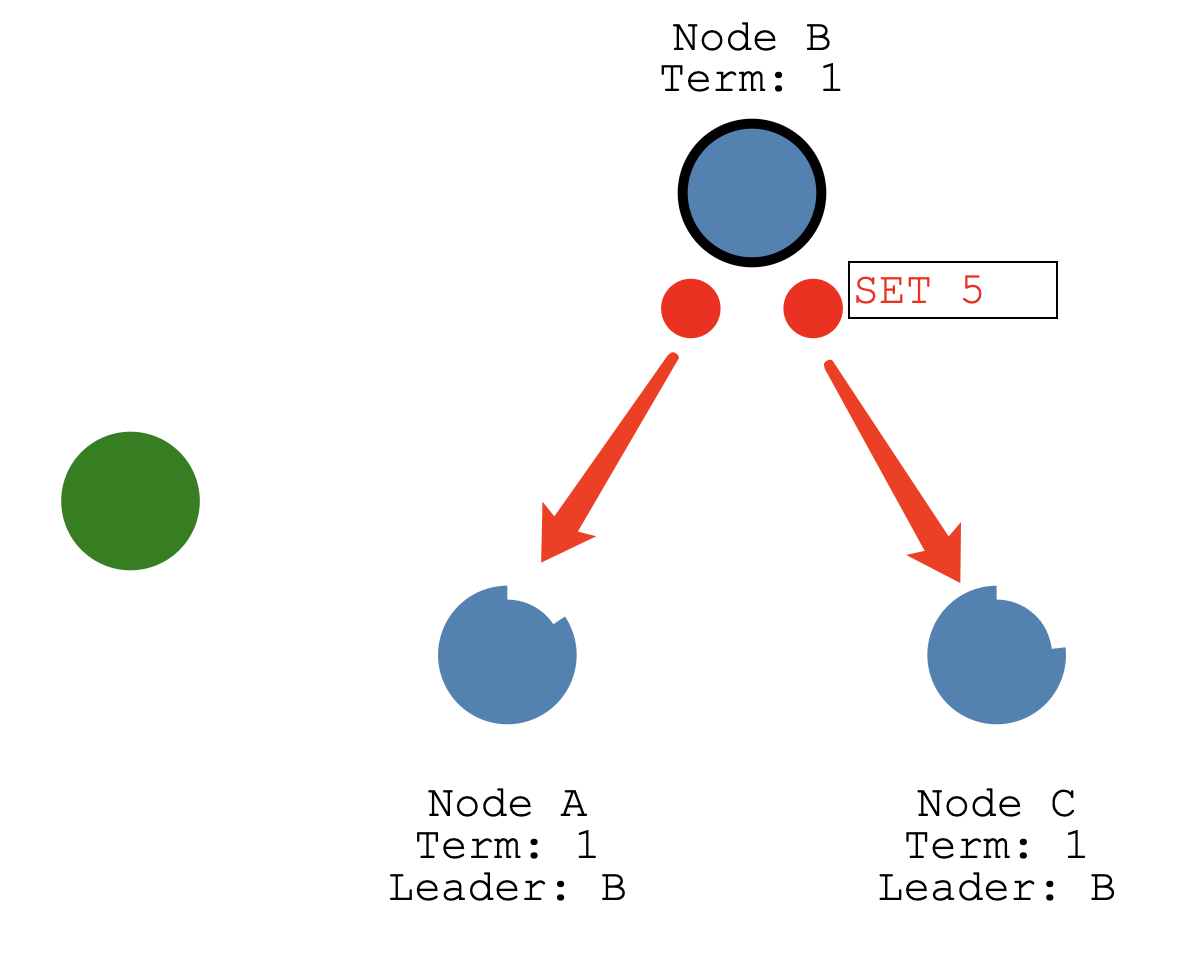
The change is appended to the leader’s log…
then the change is sent to the followers on the next heartbeat.
在下一次心跳会把变更发给从节点
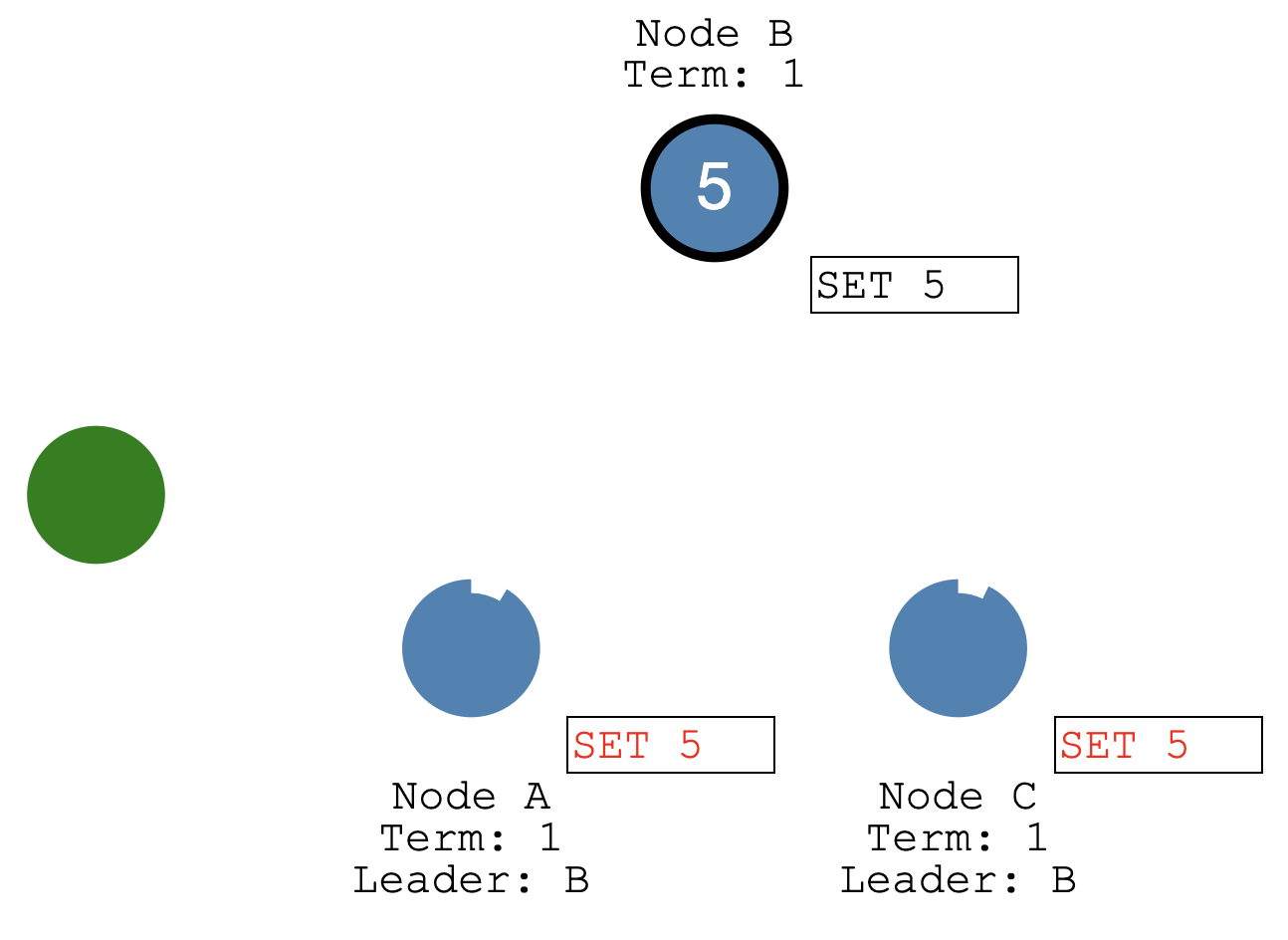
An entry is committed once a majority of followers acknowledge it… 过半协议
然后在分布式系统中还有一个比较常见的场景 网络分区
Raft ca n even stay consistent in the face of network partitions.
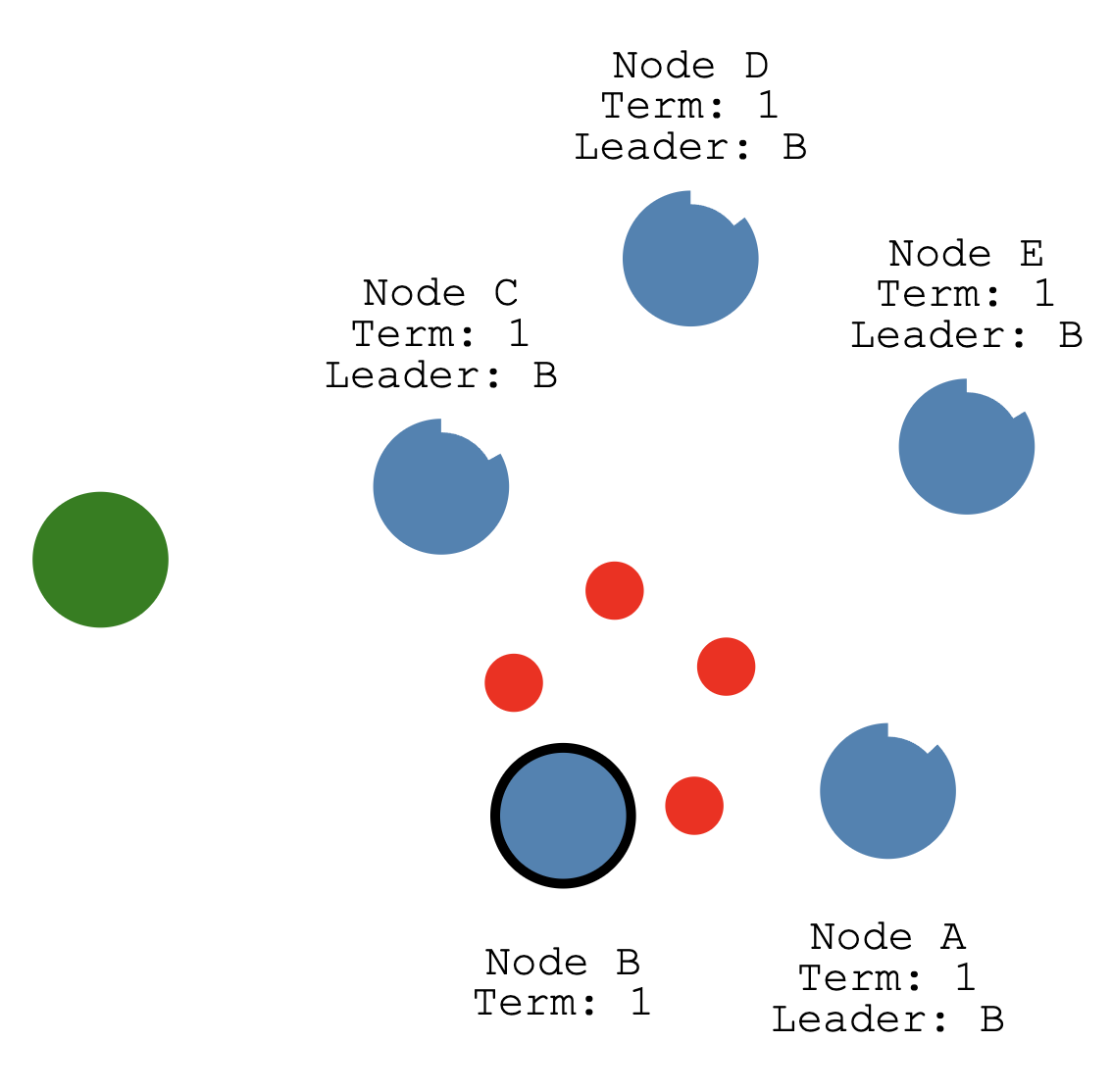
Let’s add a partition to separate A & B from C, D & E.
我们把节点分区
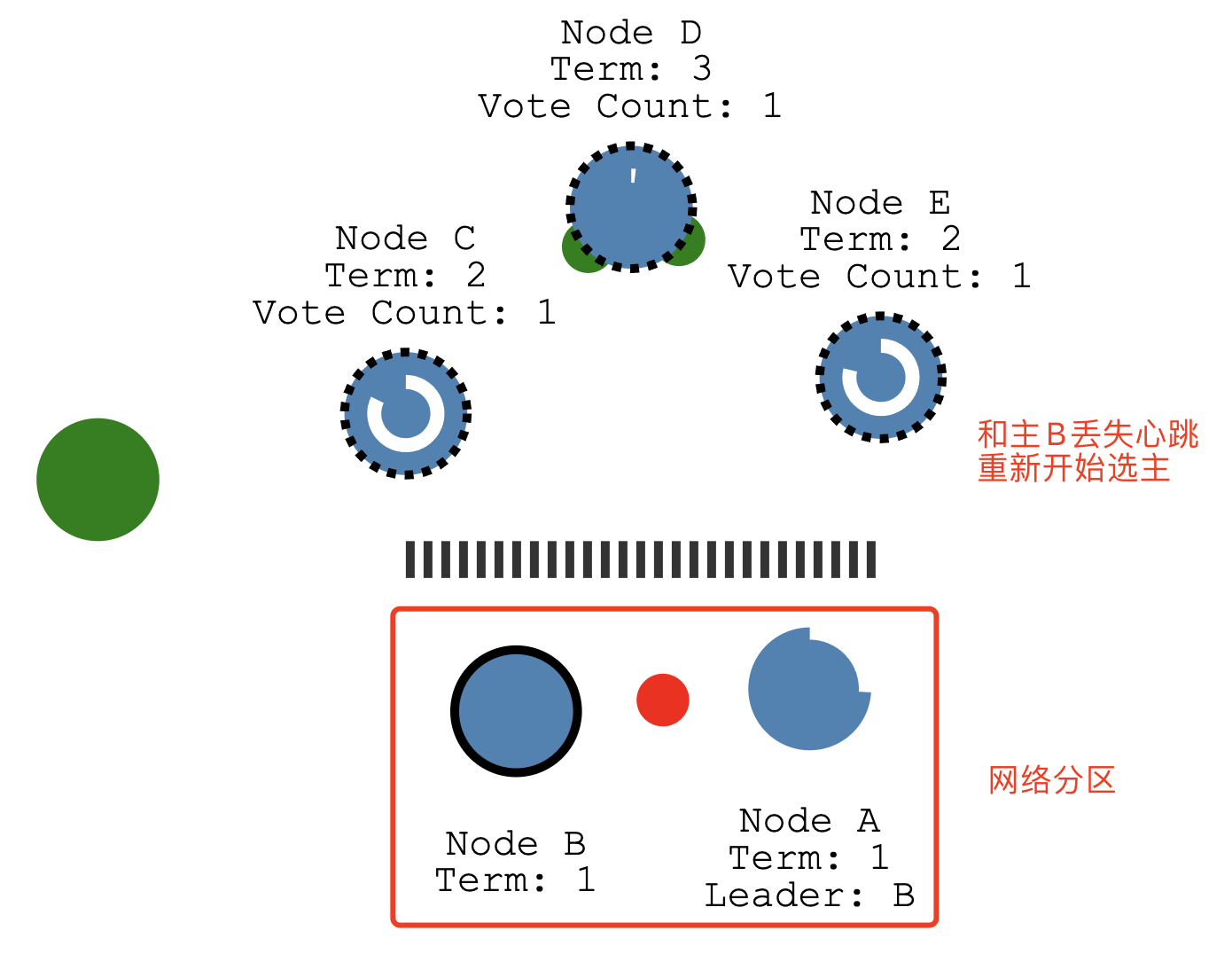
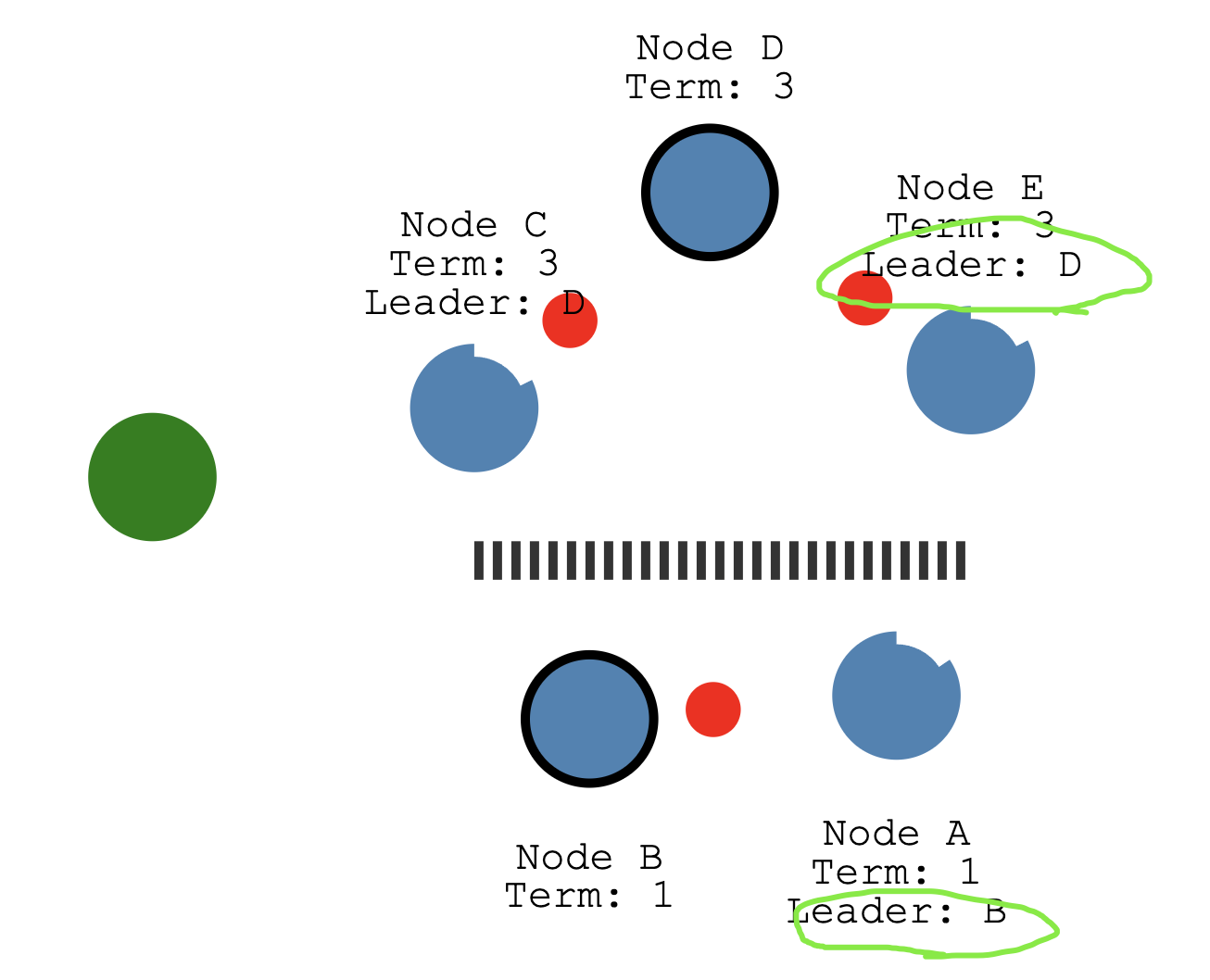
Because of our partition we now have two leaders in different terms.
现在有2个主了 =-=

Let’s add another client and try to update both leaders.
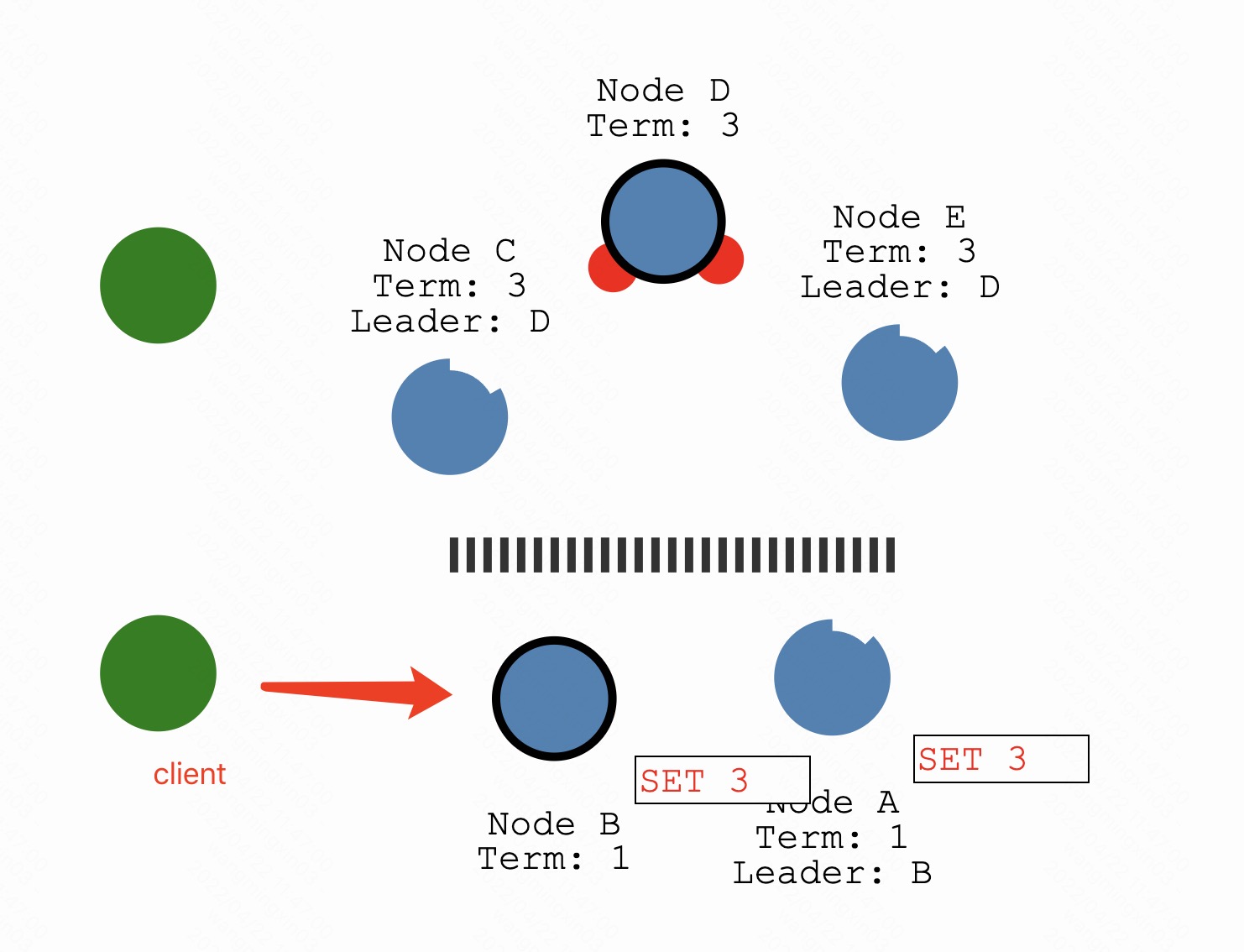
下面的分区人不够,没有办法提交
Node B cannot replicate to a majority so its log entry stays uncommitted.
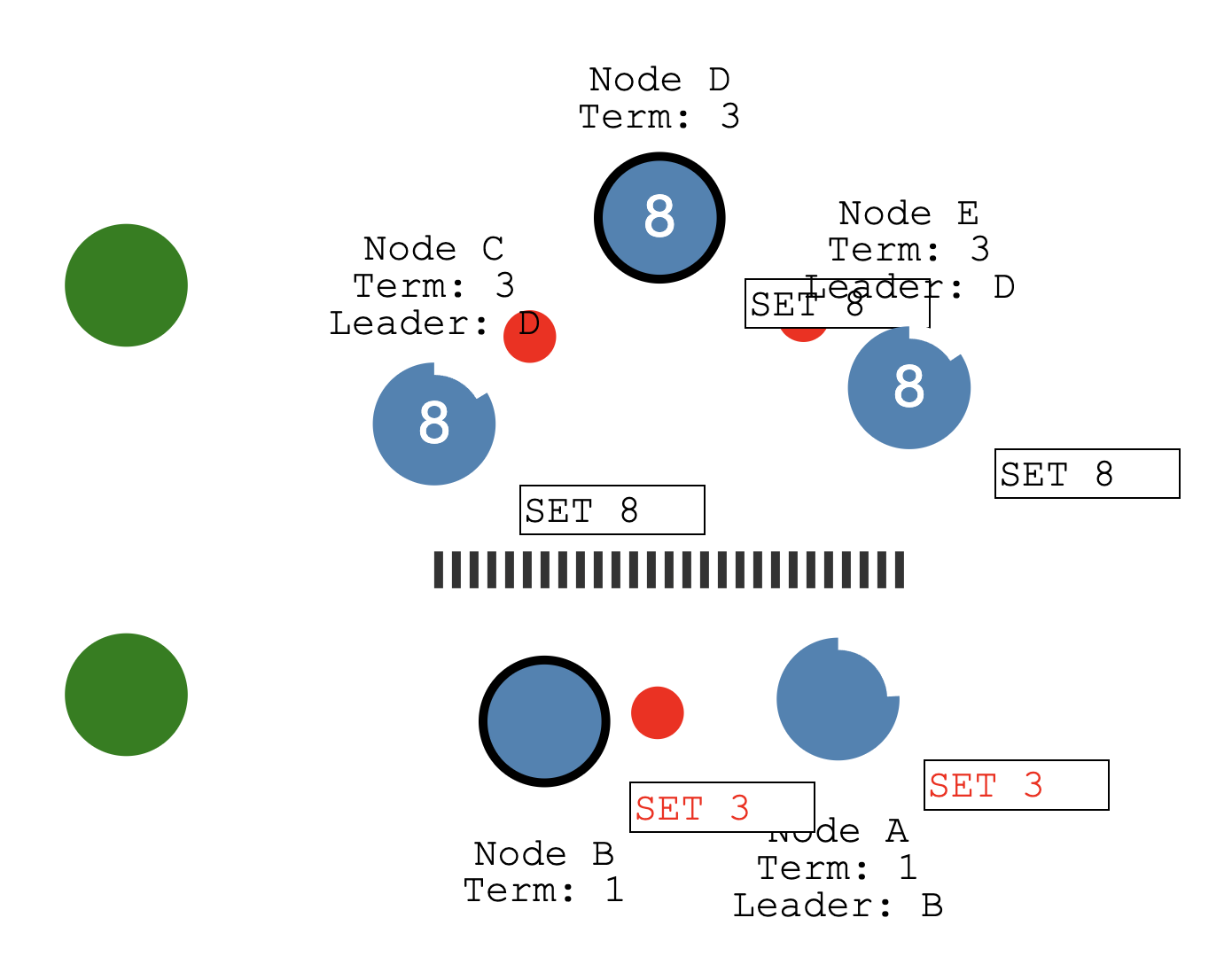
Now let’s heal the network partition.
修复网络分区
Node B will see the higher election term and step down.
Both nodes A & B will roll back their uncommitted entries and match the new leader’s log.
leader D的任期更高 3 > leader B的任期 1 —> B成为follower
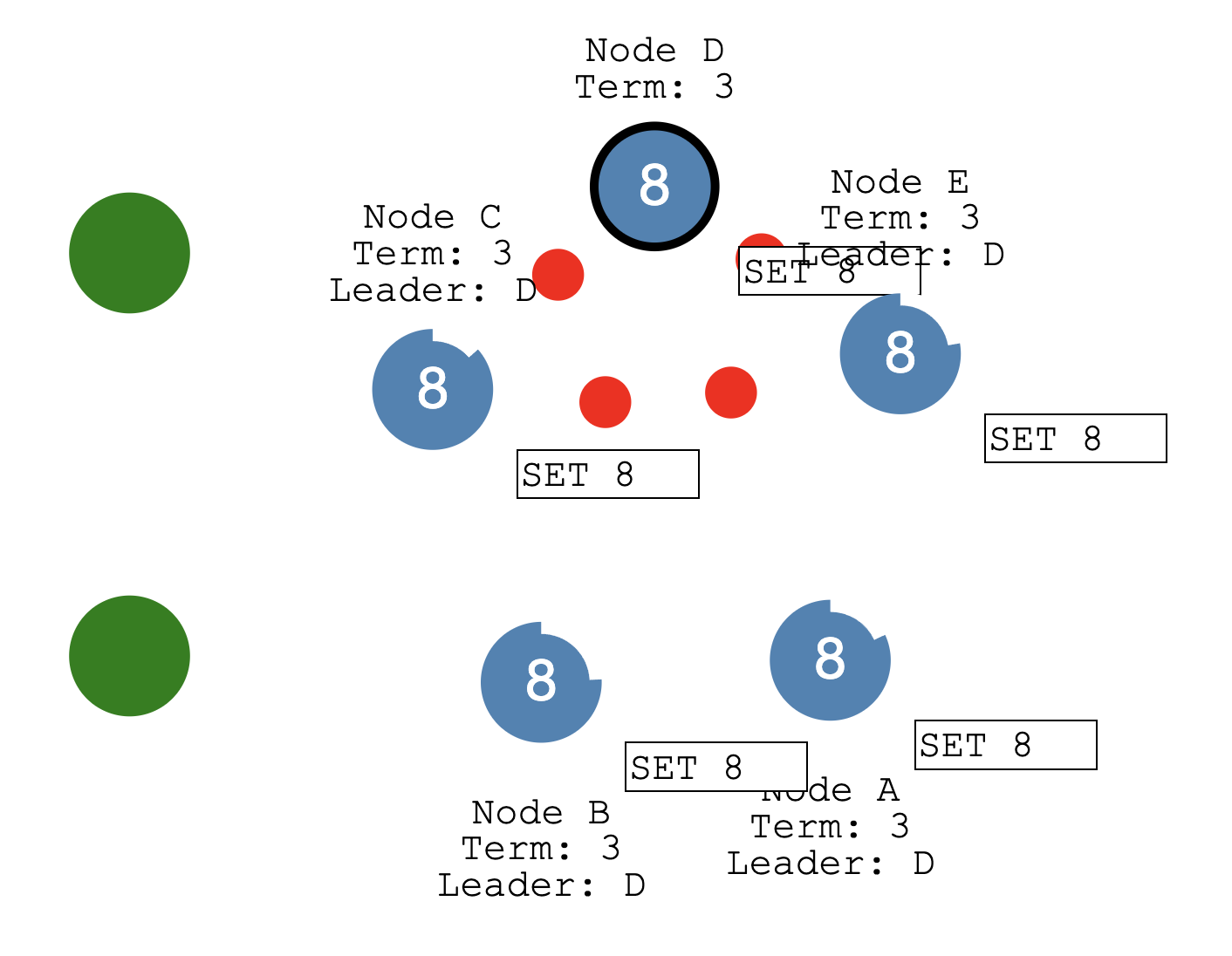
于是乎,集群的数据有恢复一致性

说点什么
您将是第一位评论人!