目录
缓存使用场景和心得
内存的诞生是为了弥补CPU和磁盘速度的不一致的问题
内存的价格都比磁盘要贵的多
CPU的多级缓存也是同理,把数据暂存于缓存,加速数据读取
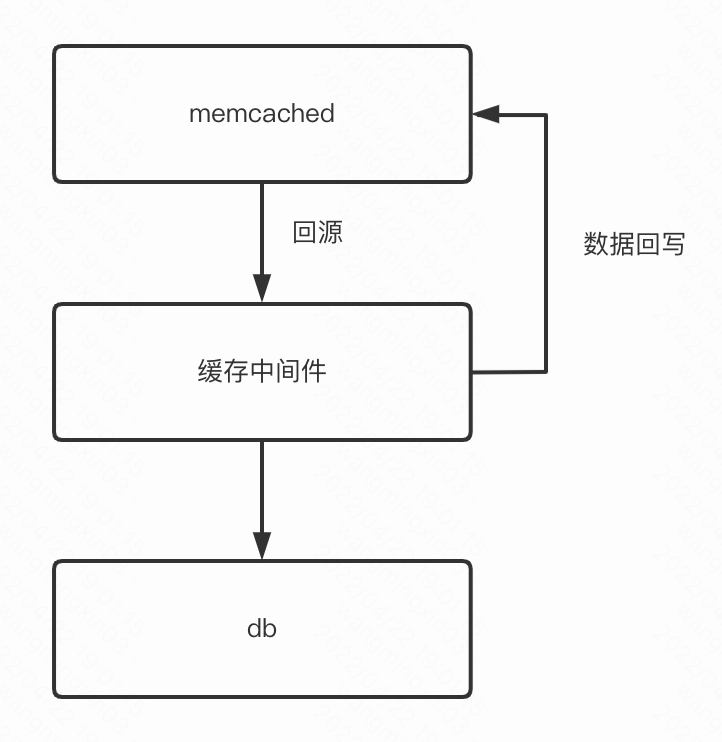
在业务中我们也常常使用缓存做读写分离,写操作落db
读流量打到缓存,用缓存抗读流量,用了缓存后又引入了一些其他的问题,如缓存和db的数据不一致怎么办?再比如缓存key大量过期了怎么办?缓存宕机了怎么办?
等等一系列的问题让我们使用起缓存来总是不能得心应手,运筹于帷幄中,决胜于千里之外~
那么文章的后面就是介绍这些事情的,有理论、有实践,也有从网上扒的,也有线上实际遇到过的。
当然缓存的使用和解决方案,可能每家公司都不同,甚至每个人的做法和想法也不是很相同,当然是根据当前业务的量级以及读写场景做最贴合的设计才是最好的。
我们工作中遇到最多的缓存无非是Redis、Memcached,还有一些本地缓存
其实大多数业务场景 Redis完全够用了,灵活的数据结构、基于内存的高性能操作、IO多路复用器、单线程、内存淘汰策略和机制、成熟的集群机制、活跃的社区!
还有很多开源的框架也很多用到缓存
比如Spring对象的缓存,Mybatis和Hibernate的缓存,nginx缓存,CDN缓存,太多啦。。。
好,继续往下整,大家选择性吸收哈,并不一定都是对的,有些也是野路子~
如何应对缓存带来的一些问题
这里说的问题是指缓存失效带来的问题
比如说缓存集中过期
一般需要我们在写入缓存时给定相对时间,而不是绝对时间expireAt
甚至有时我们需要对缓存过期做打散,比如说缓存过期时间 = 缓存base过期时间 + 随机打散国旗时间
避免key集中大量过期
还有一种场景,就是有黑产大量请求不存在的key, 触发大量回源请求到我们的db…
这个时候常规手段就是在缓存做emptyholder, 对key做空值缓存,避免大量回源影响系统
还有就是需要评估系统是否需要一些缓存的预热
尽可能保证缓存集群的可用性和灾备,避免缓存宕机了,所有请求抵达DB
那就GG了,一方面可以在可用性多点事情,另一方面可以预埋一些限流啊熔断啊的口子,作为保护存储层的最后一道关卡
还有一个比较有意思,如果有一个热key突然过期了。。。那么岂不是这些热点读流量也都到达DB
做法和上面类似,做一些限流
还有一个思路,针对这种场景,我们可以设置Key永远不过期,然后另外起一个定时任务不停的把DB的数据刷过来!是不是比较骚~
这样就不是redis过期了读不到,load到db,导致大量回源,而是通过永久key + 定时任务的方案替代。
当然还有一个做法,就是在缓存层和db层,会有一个中间件可以理解成是一个rpc, 相同key的请求会路由到一个实例,并且只有一个请求会抵达到DB,其他请求会阻塞住等待返回后,所有的请求再一起返回。。。这个快手就是这样的搞法!
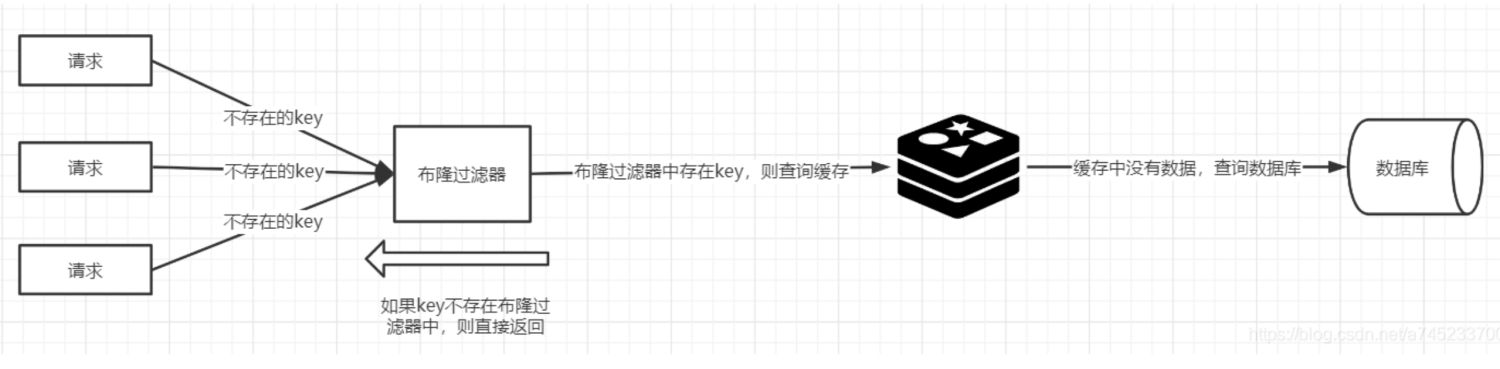
说到缓存不得不提的就是布隆过滤器了
对比请求中不存在的key可以直接返回
那么布隆过滤器的原理也在本文简单介绍下
会为每一个key分配二进制位
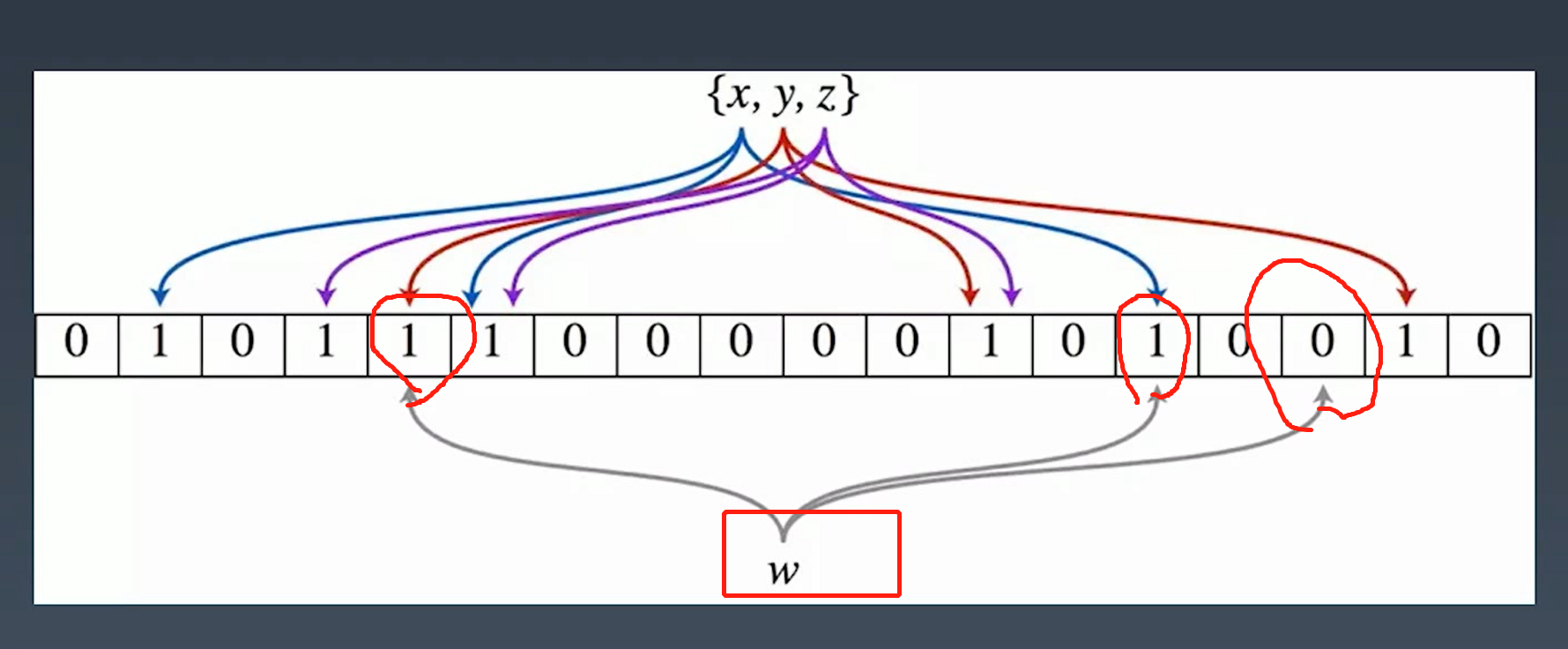
新key w 去校验分配的二进制位,发现有一位是0,说明一定不存在
但是布隆过滤器存在不一定百分百数据就在,有一定的误判,因此还需要往下层数据源查
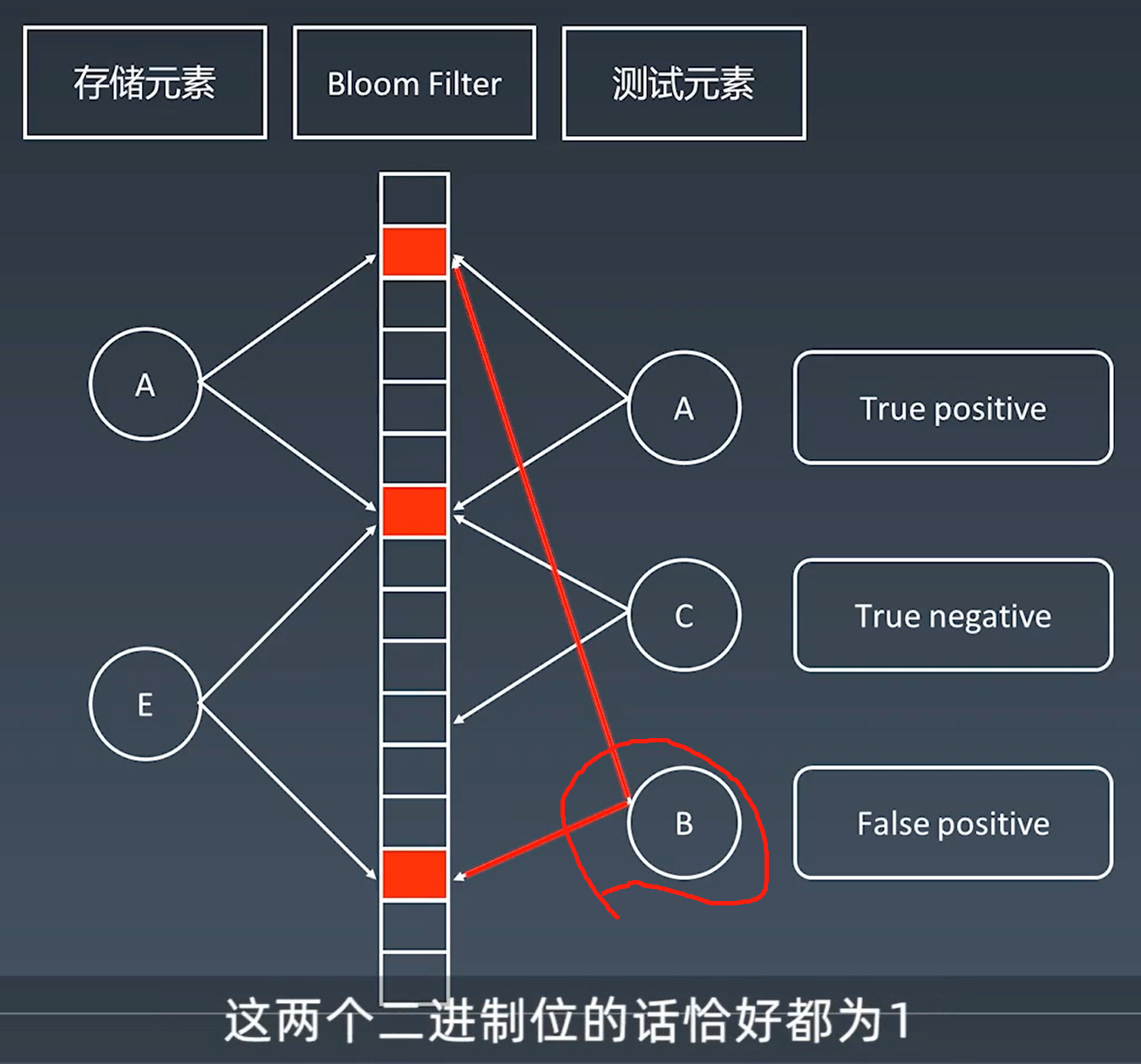
验证都为1 , 可能在里面,也可能不在!!! (请求需要抵达存储层)
验证有不为1的,肯定不在!!! (请求不用抵达存储层)
如何做好缓存数据一致性
缓存load到从库数据
有时候我们发现缓存的数据总会经常发生延迟
老是加载到旧数据,此时可以double check下缓存构建的方法是不是读到了从库
db主从延迟也会影响到缓存的数据,这里可以采用强制读主库
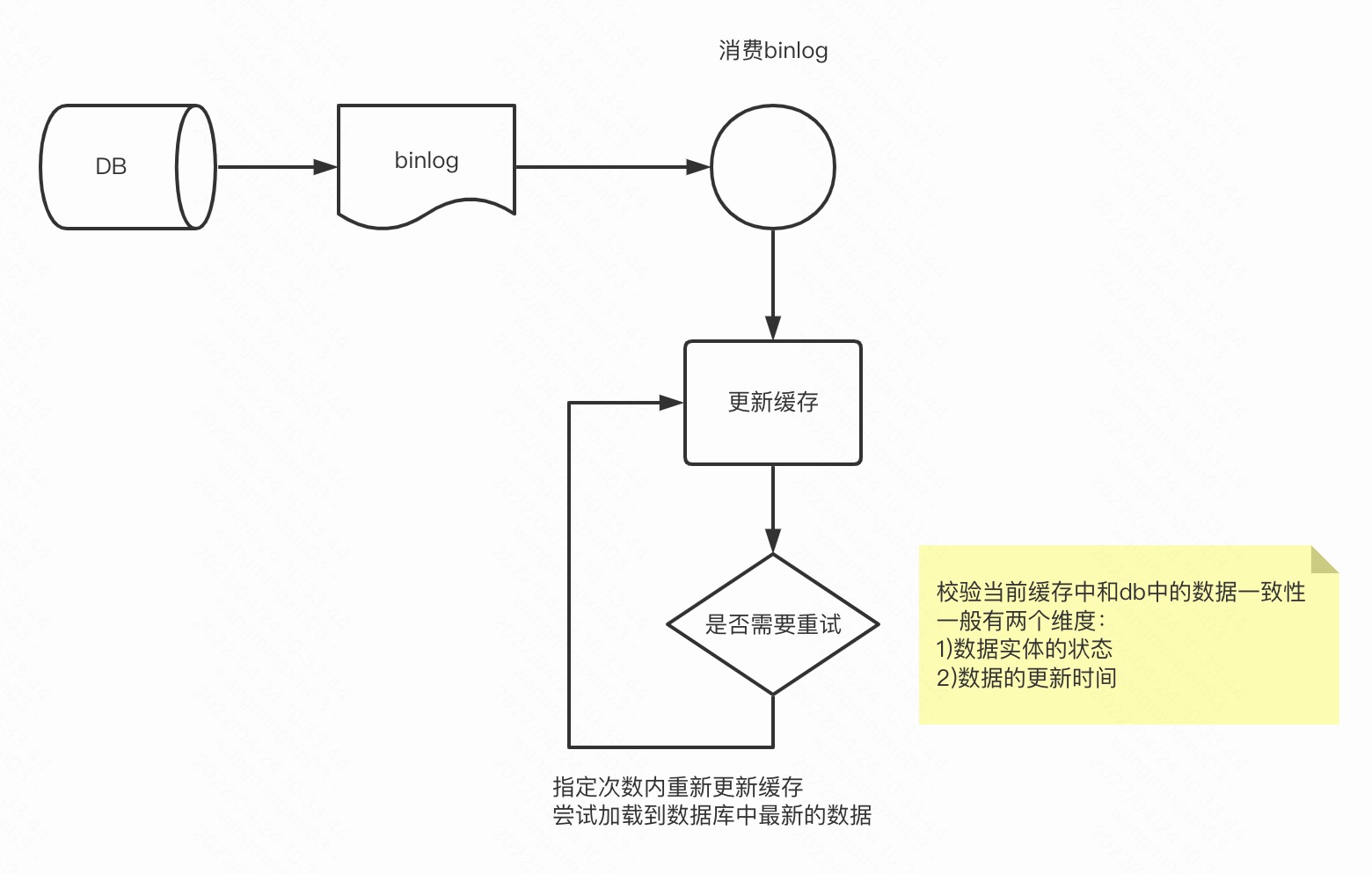
监听binlog 更新缓存
还有一个常规的操作,可以通过监听binlog去触发更新缓存
业内消费数据库binlog的组件是canal, 快手这边也有自研的组件
消费binlog还可能遇到一个问题,mysql是两阶段提交,先发binlog,再会持久化磁盘数据
因此binlog来了数据库的数据还读不到,一般这种情况我们可以重试更新缓存
Cache Aside
常见的几种缓存读写策略:
- Cache Aside Pattern
- Read Through
- Write Through
- Write Around
- Write Back(Write Behind)
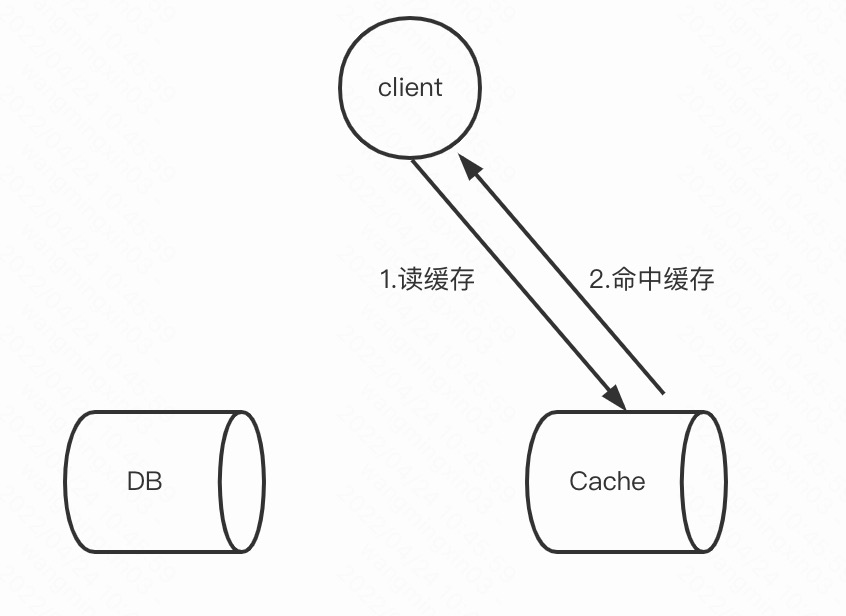
主要看下Cache Aside
读:
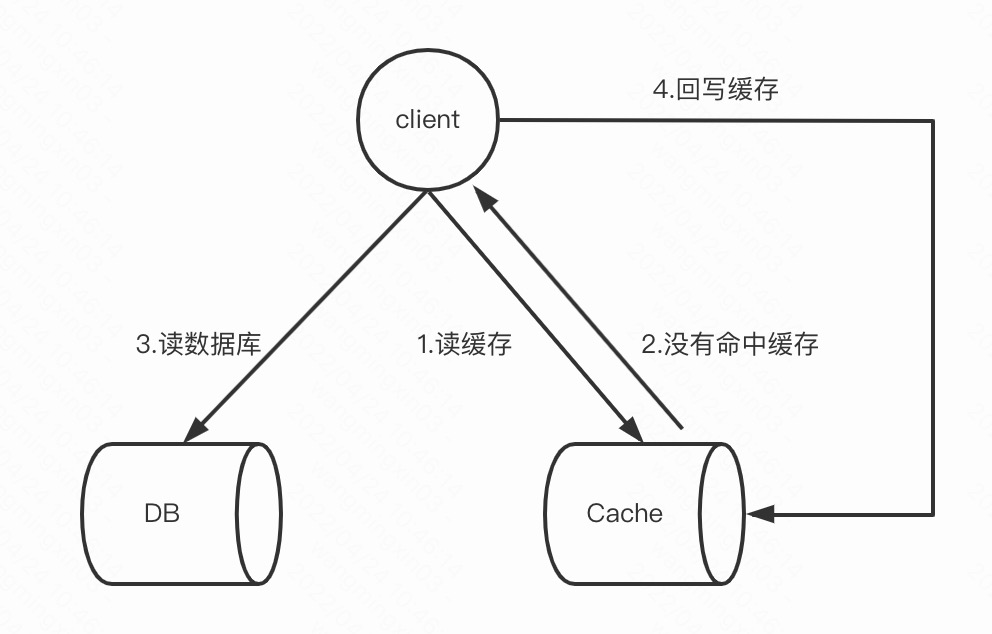
写:
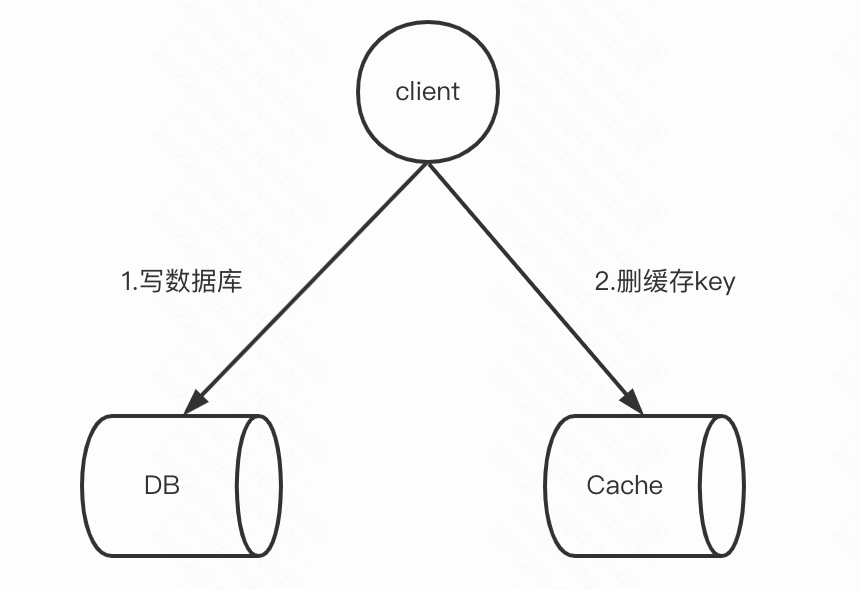
删key的话下一次读取时,缓存没有命中,再读DB,结果再写入缓存
为什么是删key,而不更新缓存呢?更新缓存会有一致性问题的
1. A写DB。
2. B写DB。
3. B修改缓存。
4. A修改缓存。并发情况下,写入了脏数据
为什么先写数据库,再删key呢,可以反过来不?
1. B删除缓存。
2. A读缓存,发现Cache Miss。
3. A读DB。
4. A更新缓存。
5. B写DB。这种case下缓存又是脏的了。。。
先写db再删key呢?
1. B写DB。
2. A读缓存,发现Cache Miss。
3. A读DB。
4. A更新缓存。
5. B删除缓存。
但在极端场景下,还是避免不了下面的case:
1. A读缓存,发现Cache Miss。
2. A读DB主库。
3. B写DB主库。
4. B删除缓存。
5. A更新缓存。
此时缓存又tm脏了,还有一个保底手段,就是延迟双删,就是等待一会再次触发删key
删key其实也带来另一个问题,如果读流量很大,热点场景也比较多,删key可能会使大量流量打到DB
兜底同步任务更新缓存
对比db 和 memcached数据状态是否一样,memcached数据还是脏数据的话就更新缓存
1.从数据库读取最近需要处理的数据
2.逐一对比db和缓存的数据
3.缓存的数据如果比db的旧,就触发更新缓存
redis 的瓶颈点
大Key问题:
string类型控制在10KB以内,hash、list、set、zset元素个数不要超过5000。
带来的危害:网卡爆、慢查询、阻塞
热Key问题:
由于Redis的单线程特性以及一个key最终只落在一个节点的特性,如果一个key执行的OPS超过了Redis的极限
(譬如10万,目前在测试多线程版本Redis),那有可能对整个集群造成摧毁
京东出了一个热key发现系统
https://gitee.com/jd-platform-opensource/hotkey
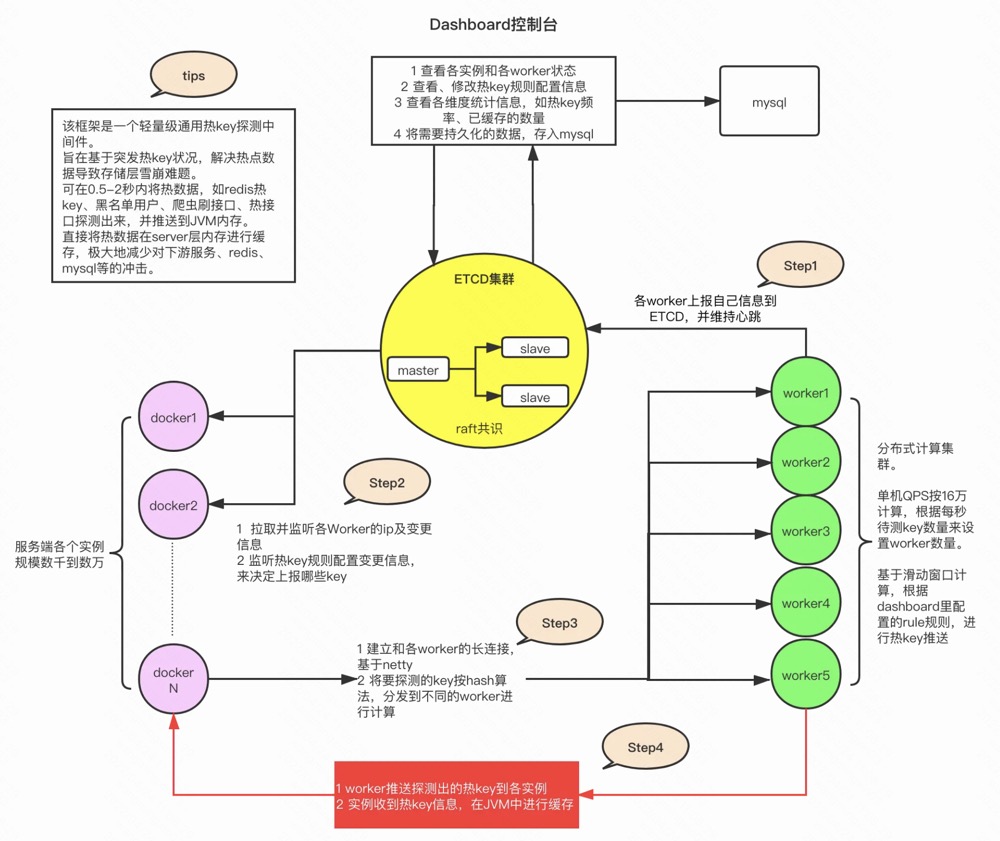
热key的解决方法一般是包一层loadingCache
或者把一个key分shard存储
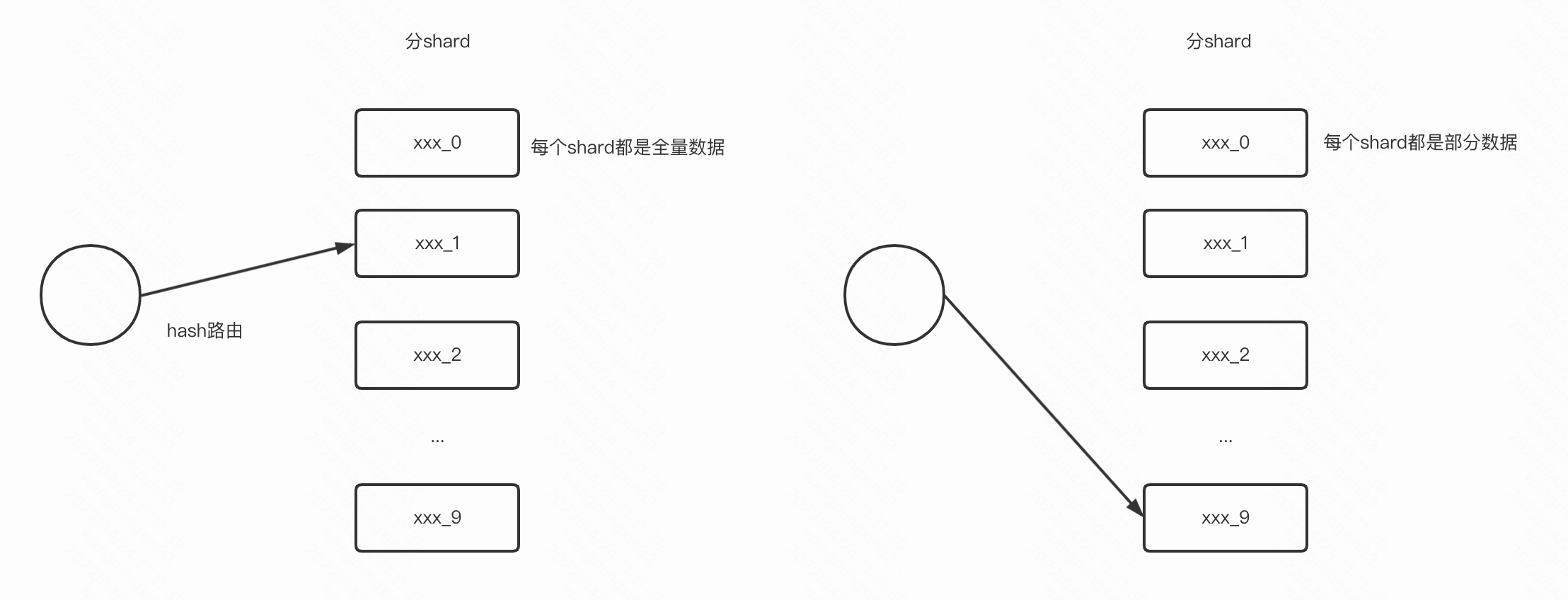
这样就把热点流量打散到多个分片了
一般还会做冷热分流处理
比如识别是热点数据走本地缓存,识别是非热点数据走普通缓存
也可以按需分片,比如无热点问题无需分片,热点问题分片数10,超强热点问题分片数100
Redis Key 逐出问题:
Redis 的输入缓冲区和输出缓冲区如果被打满,会导致key被逐出,不恰当的使用可能会导致线上重大事故!
具体可参考下面这篇文章
Redis主从切换问题:
比如我们使用redis加分布式锁,client1上锁成功,此时redis 发生主从切换,但是主从的复制还没有完成,从上还没有这个上分布式锁的key,导致client2也获取了锁,炸裂。。。
Memcached VS Redis
首先Redis优点大家也都知道,灵活的数据结构、优秀的持久化策略、成熟的集群模式等等
那么Memcached呢?为啥还有这个比的存在,存在即意义,memcached是完全基于内存的,没有持久化策略,且memcached是多线程的
抗高并发读流量吊打Redis,不过Redis 6.0 也做了多线程的改造和一些优化,不过具体还没有在线上投入过使用
memcached可以仅几个实例,可抗百万QPS,memcached的成本要低于Redis
Redis 需要几十个主,几十个从,数个哨兵,外加一些proxy实例,这样的redis集群规模,可以支撑几十万QPS,当然还要看机器配置
memcached内存分配方式是预分配内存池,Redis时时为数据分配内存。
Guava LoadingCache
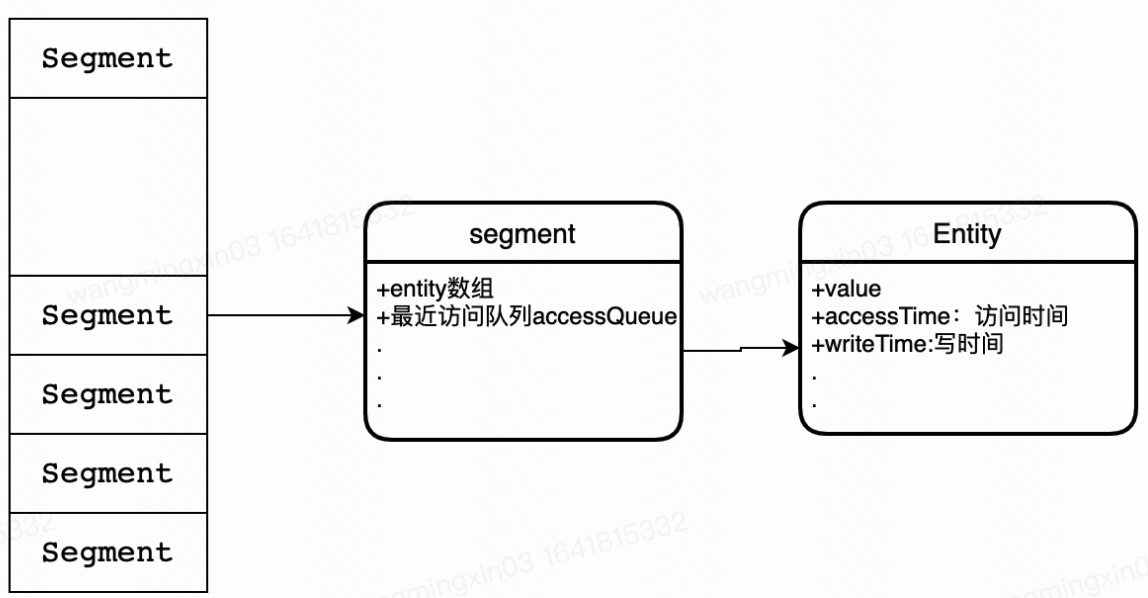
低层数据结构大概是这个鸟样,会记录数据的读写时间
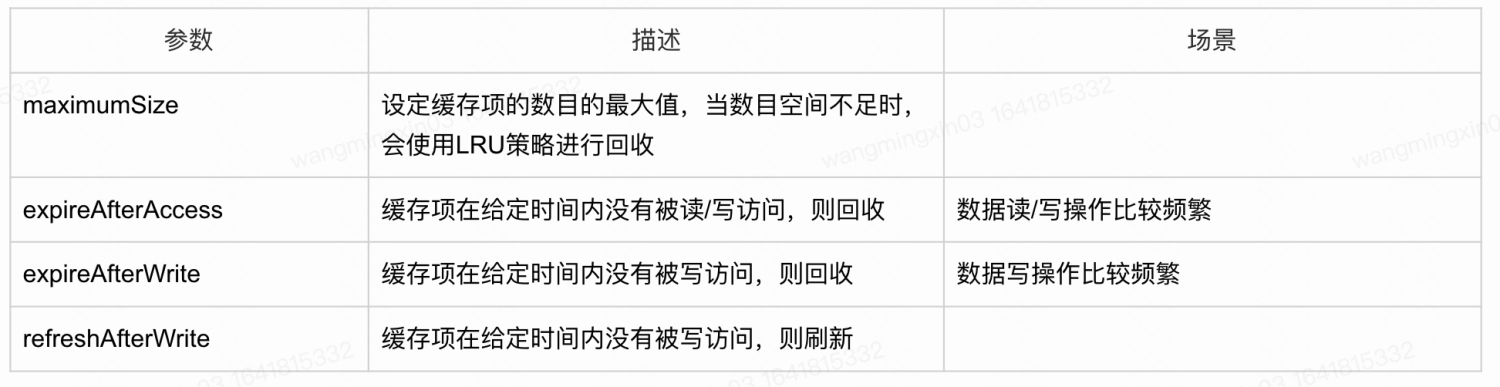
说到这里,使用本地缓存有一个注意点,就是并不是所有的读流量都适合加本地缓存
比如说我只有是热点问题,才去加本地缓存,什么叫热点问题,就是对单key有超高流量读,
举个例子比如说查询几十万人在一个直播间去redis查询当前主播的一个身份标识(不会经常变更),key就是主播id, 相当于几十万人都对这一个key做读操作,典型的热点问题
这样就可以使用本地缓存,key就是主播id,会回源到redis。
那一个用户进入直播间会查询用户的身份,这个场景适合本地缓存不?
显然不适合,用户太多了,用户唯独的请求不具备热点性,本地缓存可以local的数据也是有限的,如果这种场景用了本地缓存就会导致缓存的值会不停的被逐出,因为用户量大,用户请求大,缓存很快就满了,就会触发淘汰策略,且缓存的命中率极低,这种场景用了本地缓存反而tm是个负担。
Caffeine Cache-高性能Java本地缓存组件
//同步加载
LoadingCache<String, Object> cache = Caffeine.newBuilder()
.weakKeys()
.weakValues()
.maximumSize(100)
.expireAfterWrite(1, TimeUnit.MINUTES)
.build(k -> setValue(key).apply(key));
//异步加载
AsyncLoadingCache<String, Object> cache = Caffeine.newBuilder()
.maximumSize(100)
.expireAfterWrite(1, TimeUnit.MINUTES)
.buildAsync(k -> setAsyncValue(key).get());
基于Guava Cache优化而来,针对淘汰策略进行优化
基于ZK注册通知的本地缓存
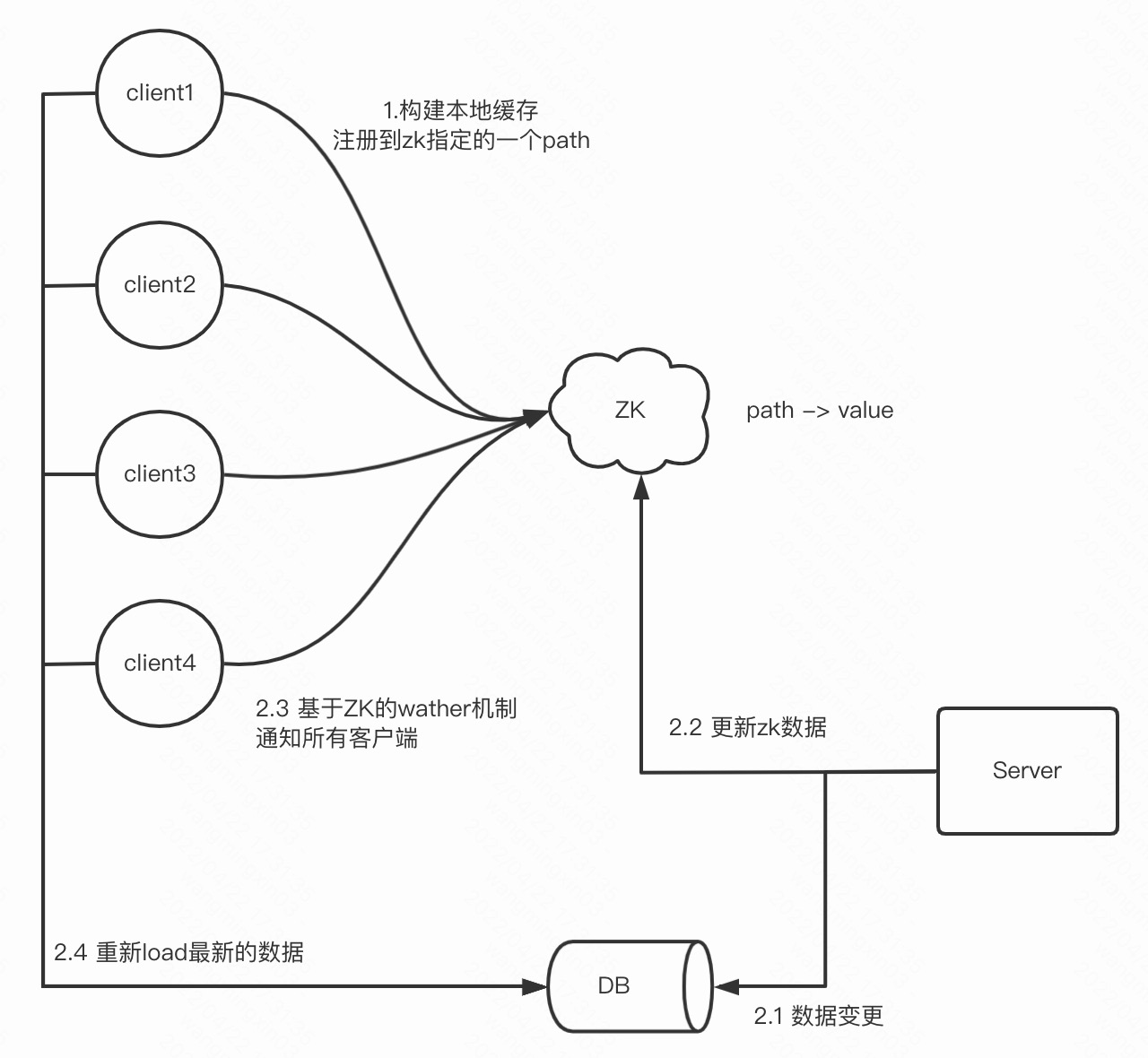
这个本地缓存是基于ZK构建的
是否需要重新加载最新的数据,需要ZK通知
这样的架构模式特别适用于读多写少的场景!
那ZK通知后,所有的客户端都会一起load最新的数据,这显然是一个洪荒流量
其实既然用了本地缓存,本身就避免不了本地缓存不一致问题
所以这里拉取最新的数据,可以做一个打散,比如客户端拉取时间打散到1分钟,每秒的qps就会骤降!
那这里还会有什么问题不?
对ZK的强依赖,如果ZK挂了,client端和zk通信丢失了,会导致缓存的数据一直不更新
所以这里还需要有一个兜底的自动刷新策略,比如说几分钟刷一次,就算没有ZK通知也去主动构建,保证缓存最终一致性
但这里其实还有一个问题。。。
客户端每次缓存的是全量数据,数据库有一行的变更,就要重新load全量数据,有很大的资源消耗
其实这里也可以基于本地缓存做一个版本号的增量缓存方案。
那么本地缓存最致命的问题还是本地缓存不一致
每一个客户端都会缓存数据,但可能拉取到的数据版本不一致,因为每个节点的网络情况和资源情况都是不同的,我的数据源一致,但没法保证每个节点缓存的数据都一致
虽然也是可以在一定时间后达到最终一致性。
那这样的情况会造成什么问题呢?
比如说A和B服务本地都local了一个数据源的数据,但由于2个服务缓存不一致造成了一些问题:
比如A看到的数据是10元,这个10元也是给用户看到的下单金额,但是中途有管理员在后台把下单金额改成了100元,但是A服务还没有拉到最新的数据,依然本地缓存的是10元,但是B服务已经拉到了最新的数据100元,那么对于A服务给用户看到10元,A下单服务调用B扣款服务,结果卡扣了100元,用户懵逼了。。。
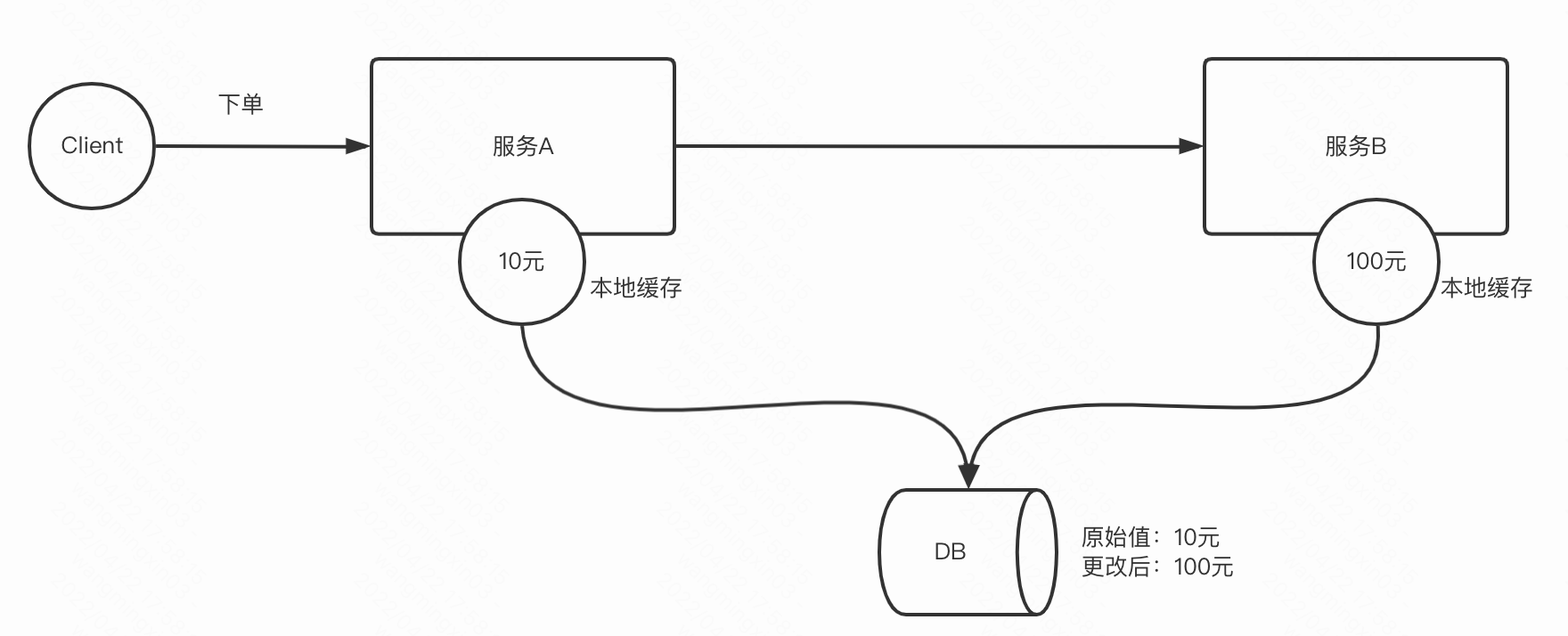
注:我这个例子举的不一定恰当哈,不过线上确实出现过类似的case
所以要不要用本地缓存还是要看业务场景的。
本地缓存更多的是承载高并发读流量,交易和对数据一致性比较高的功能尽量不要使用。
缓存多级回源机制
缓存一般是需要有回源机制的,因为一般缓存本身没有持久化
数据过期或者丢失需要回源,回源至持久层,一般是db
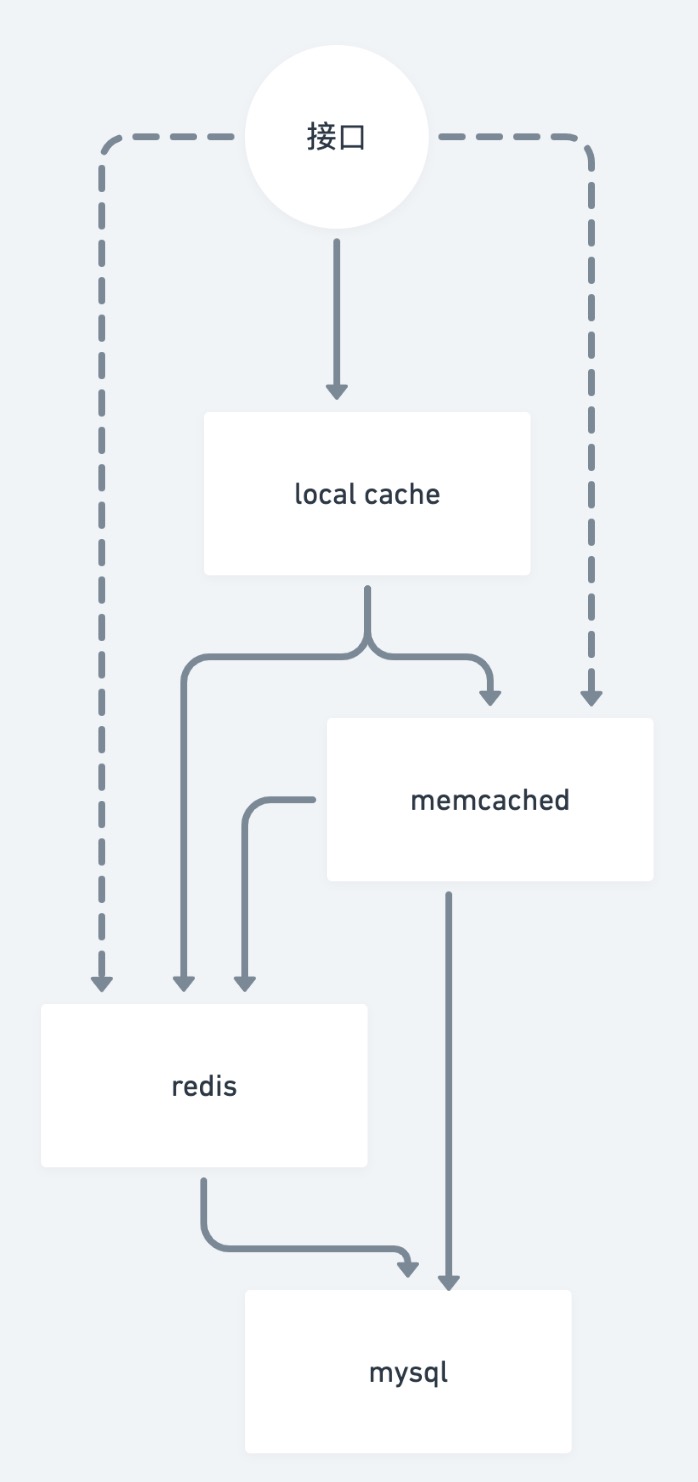
memcached 到mysql 的回源可以使用一个现有的组件
https://github.com/PhantomThief/retrieve-id-utils
List<Integer> ids = Arrays.asList(1, 2, 3, 4, 5);
Map<Integer, String> result = RetrieveIdUtils.get(ids, Arrays.asList( s//
new IMultiDataAccess<Integer, String>() {
@Override
public Map<Integer, String> get(Collection<Integer> keys) {
return ...; // 第一级缓存读取
}
@Override
public void set(Map<Integer, String> dataMap) {
// 第一级缓存回流
}
},
new IMultiDataAccess<Integer, String>() {
@Override
public Map<Integer, String> get(Collection<Integer> keys) {
return ...; // 第二级缓存读取
}
}));

说点什么
您将是第一位评论人!