“影子”的概念在技术侧最早诞生于阿里的大促全链路压测
那我们先来聊下全链路压测
由于业务不断的架构升级,引入分布式微服务
传统的线下测试已经不能满足我们的测试需求了,因此需要全链路压测
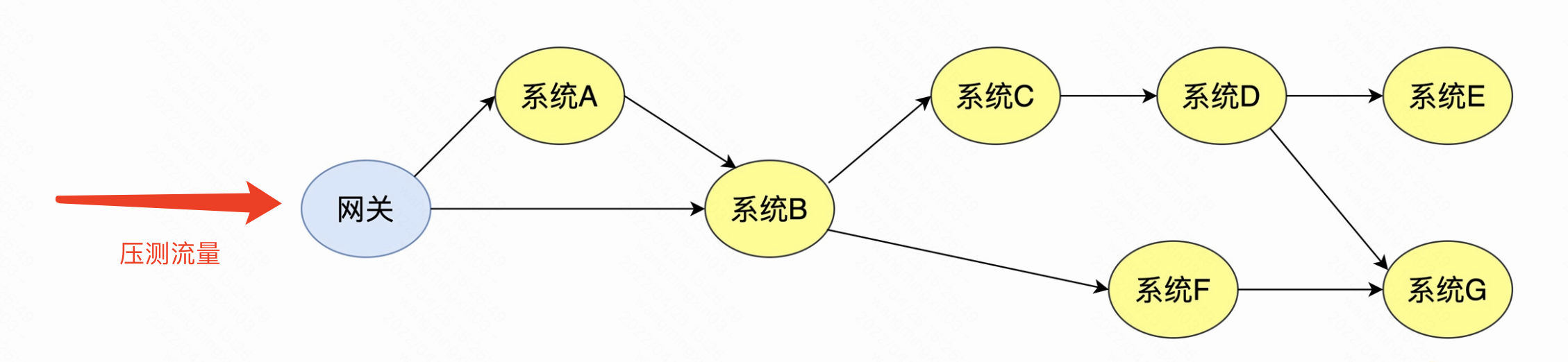
一般需要压测平台,创建配置压测计划,对接口进行发压
这样的压测流量是直接打到我们的线上环境的!
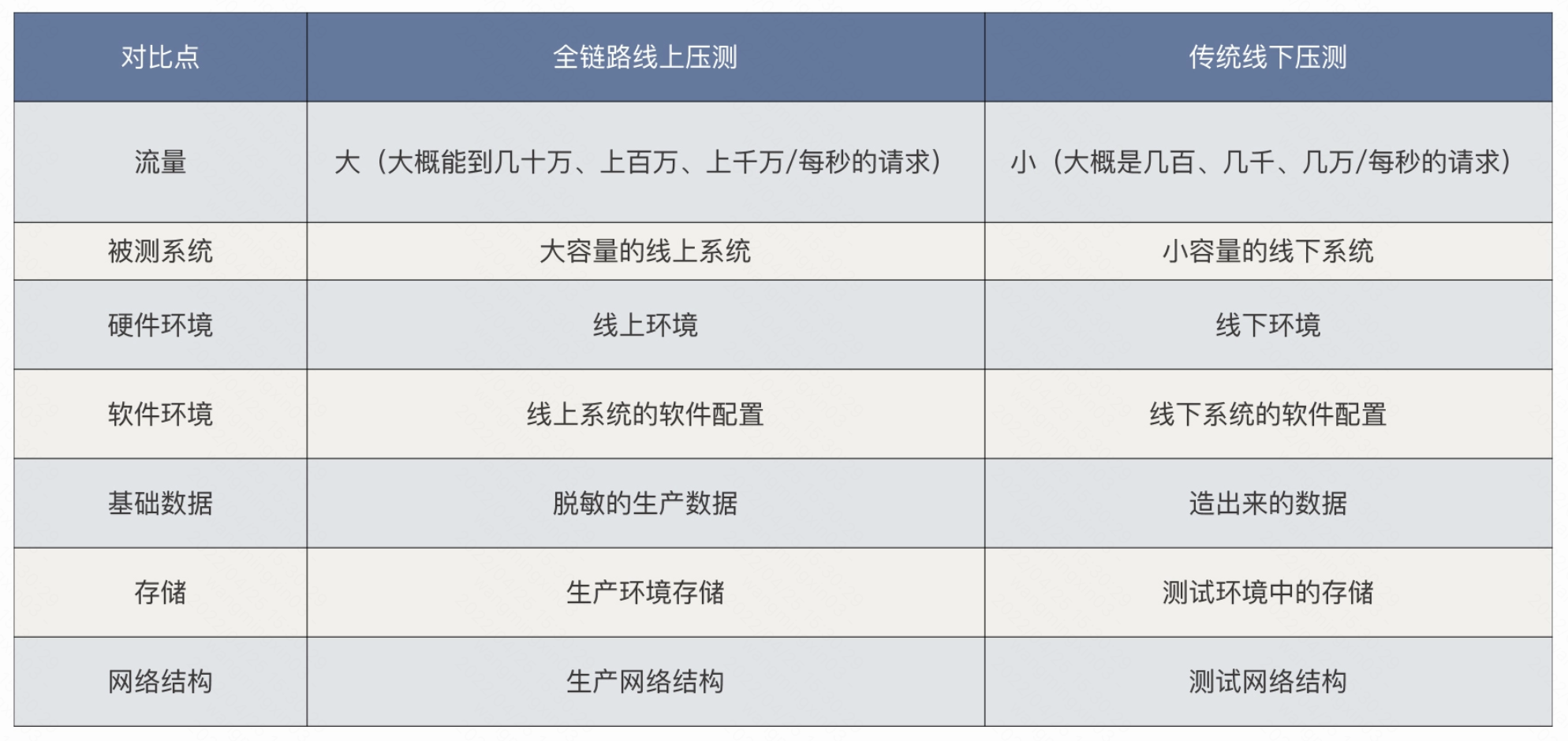
ok,那我们思考几个问题
是不是所有公司都需要全链路压测,是不是所有业务都需要全链路压测
你的企业有没有那么大的流量需求?
你的系统要不要做全链路线上压测?
你的系统能不能做全链路线上压测?
你的组织支持不支持你做真正的全链路线上压测?
一般我们需要在节假日前,大促前,大型活动前,
对核心接口、核心链路进行全链路压测,确定系统的真实抗压能力,确定系统的瓶颈点
按需进行限流、熔断、降级、预案等改造。
那么压测目前还有什么问题呢?
压测会对生产环境造成冲击,压测的数据会落到生产的数据库表,落到生产的缓存中,出现大量测试的脏数据
那我们可以在存储层对压测流量和真实流量做分流,做不同的多路由,于是乎就有了影子表、影子库、影子key、影子队列等的概念了
我们在调用链路中都是放行的,但在存储层做隔离
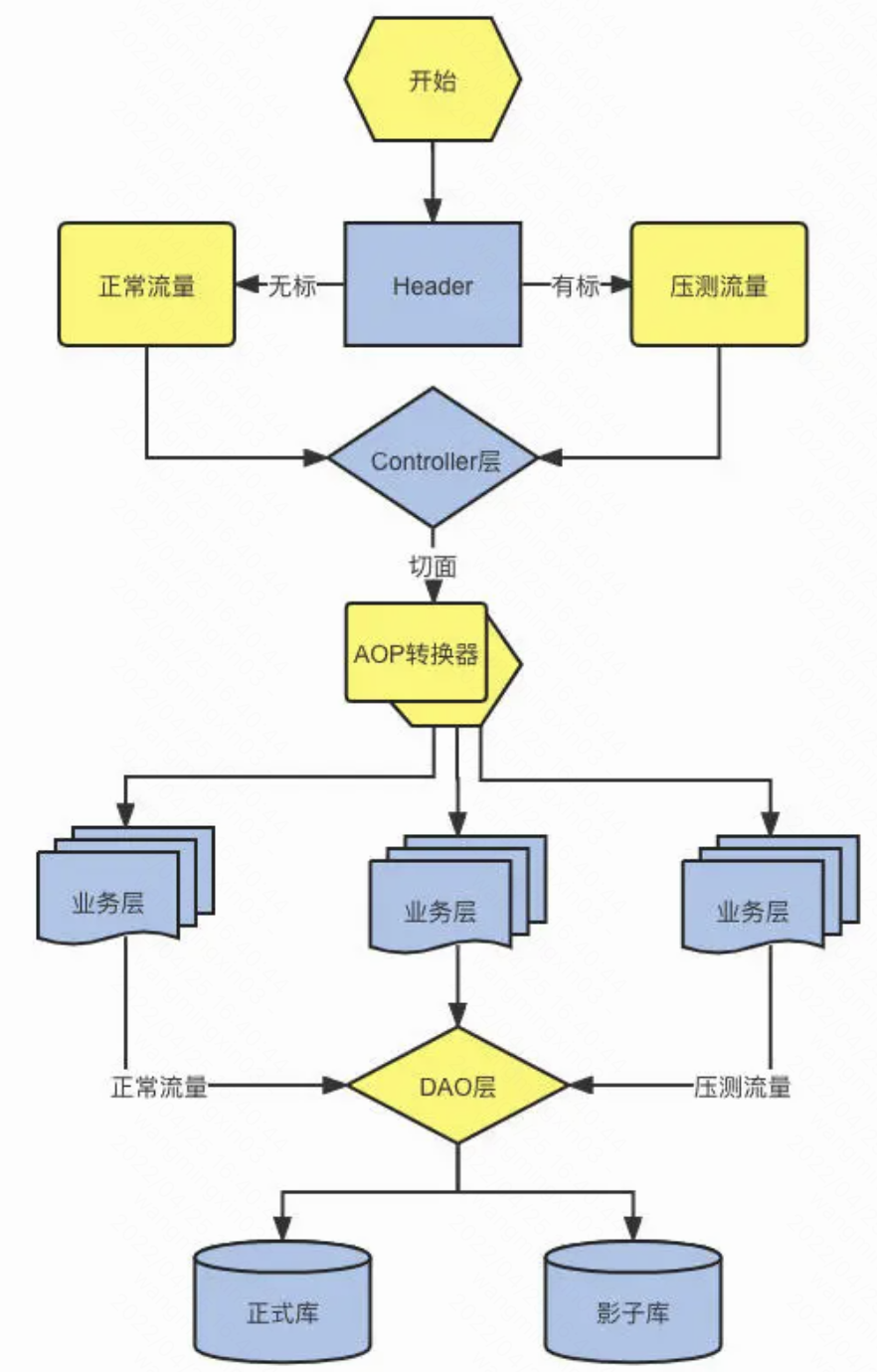
首先我们需要一个测试流量的标识,比如说在API层,需要在调用处在header传递一个标识,这个标识会由一个interceptor拦截器拦截识别出是测试流量
于是乎,会一直往下游透传测试标识,这就是流量的识别和流量的透传,刚才上面说的在存储层做隔离就说流量的隔离。
这就是压测中最重要的概念:流量识别、流量透传、流量隔离
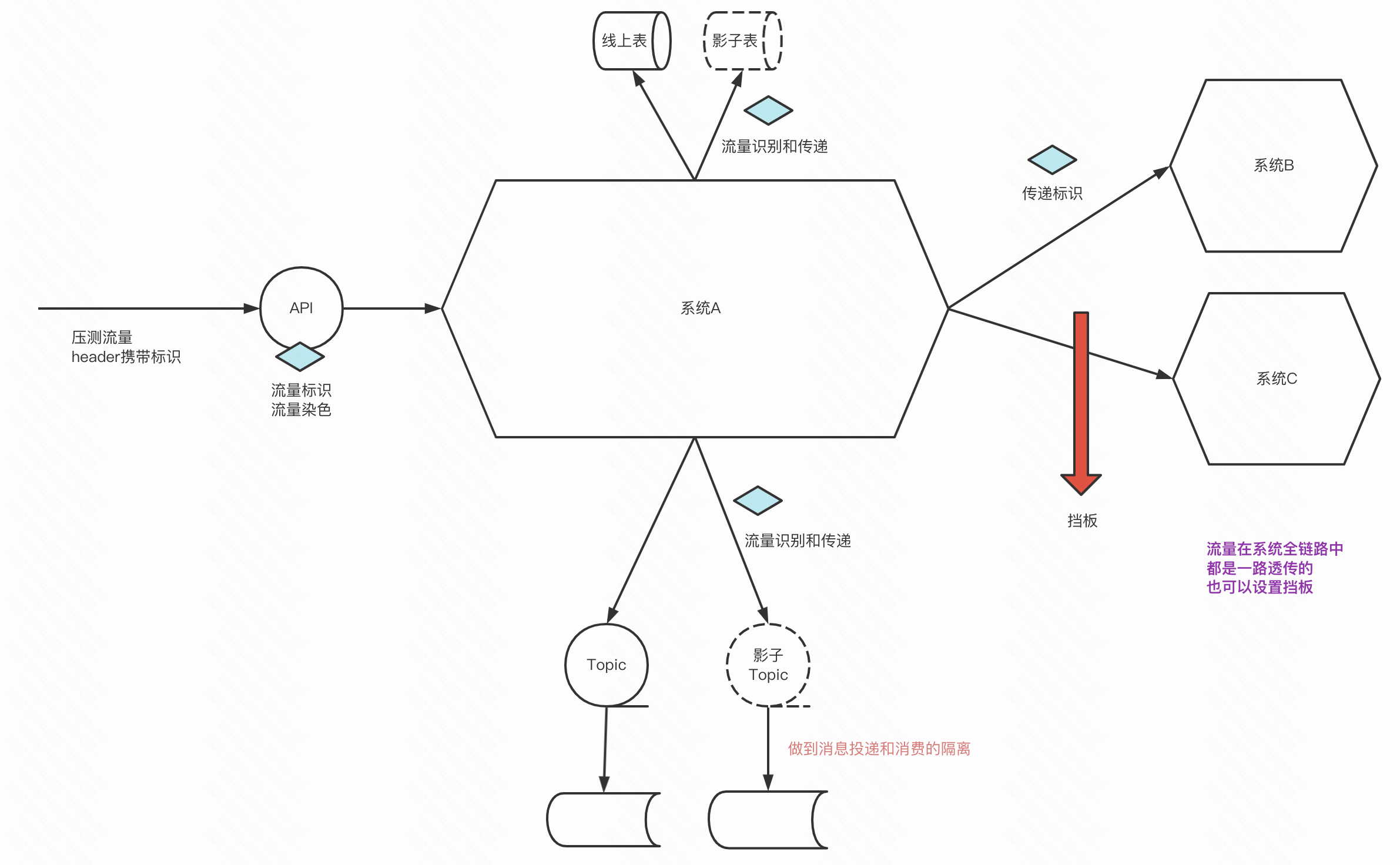
测试标识可以在全链路中透传,也可以设置挡板,比如在指定rpc断掉,还需要设置是否需要路由到影子表、影子key、影子队列
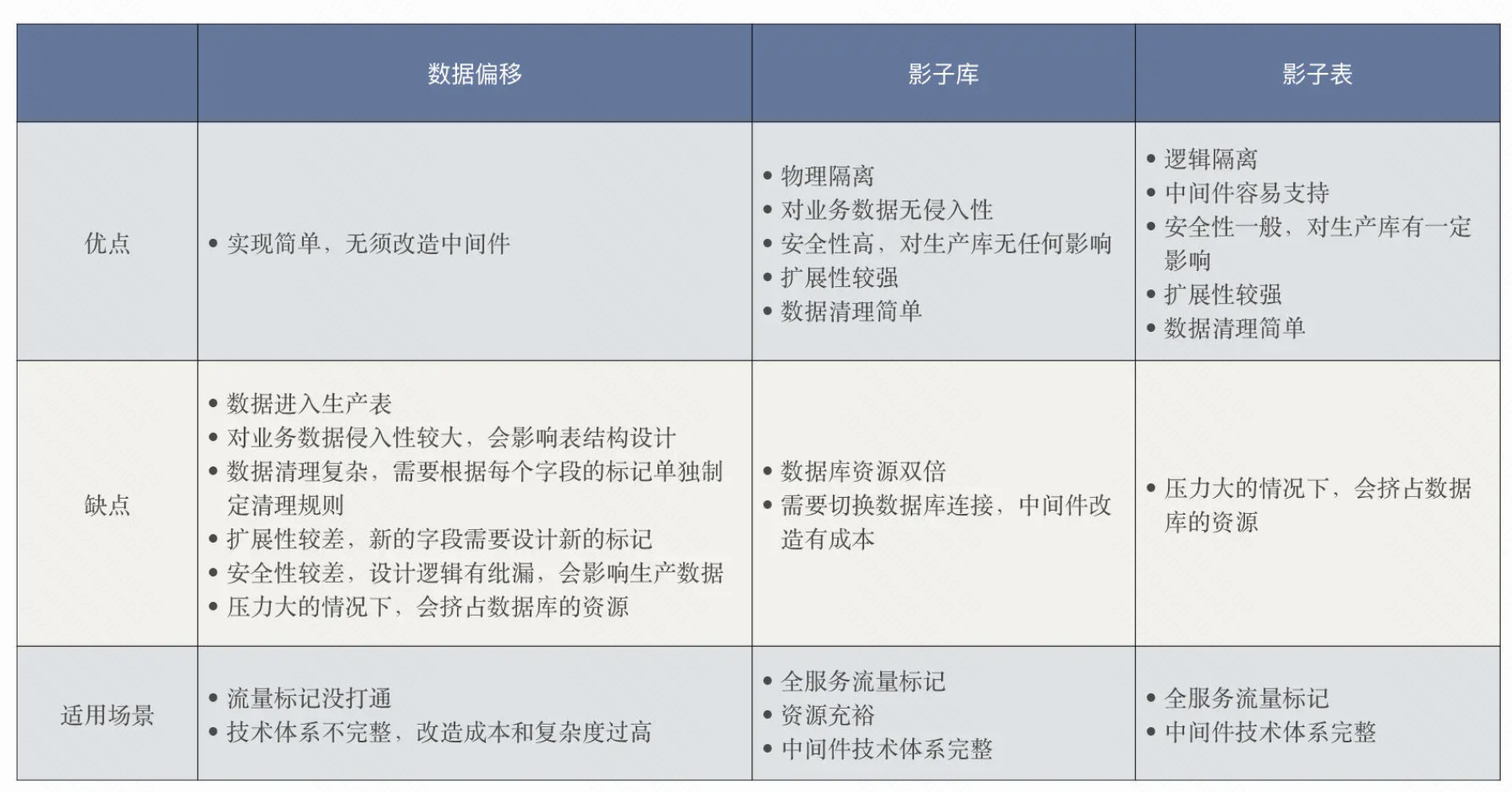
因此需要改造的有各个组件,比如需要创建一个和线上表同结构的影子表,唯一的区别就是影子表的表名就加了一个前缀,shadow_xxx
然后JDBC需要做个代理,识别出测试流量需要改写SQL,把测试流量路由到影子表
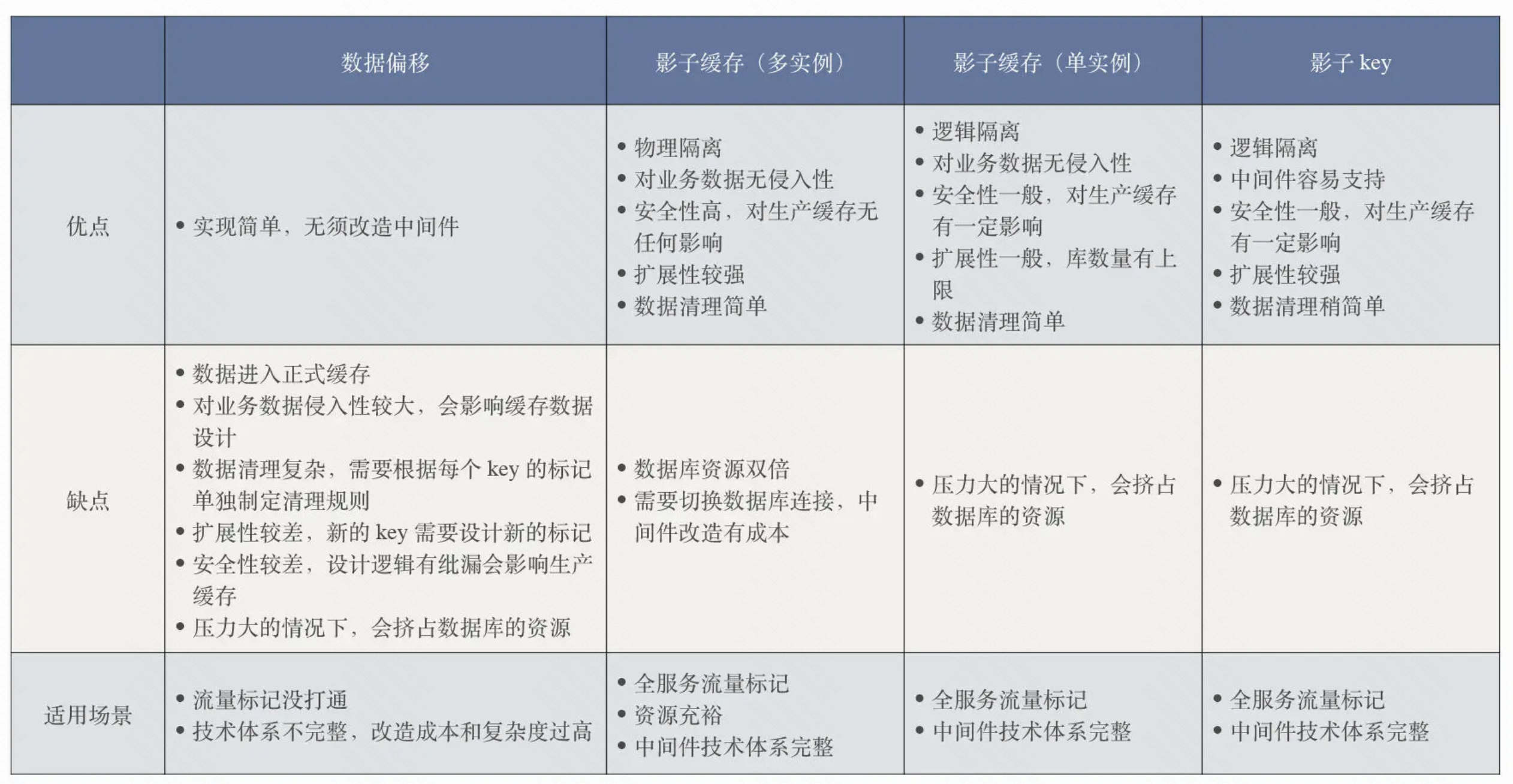
影子key没啥,就说在redis或者memcached缓存key拼一些前缀
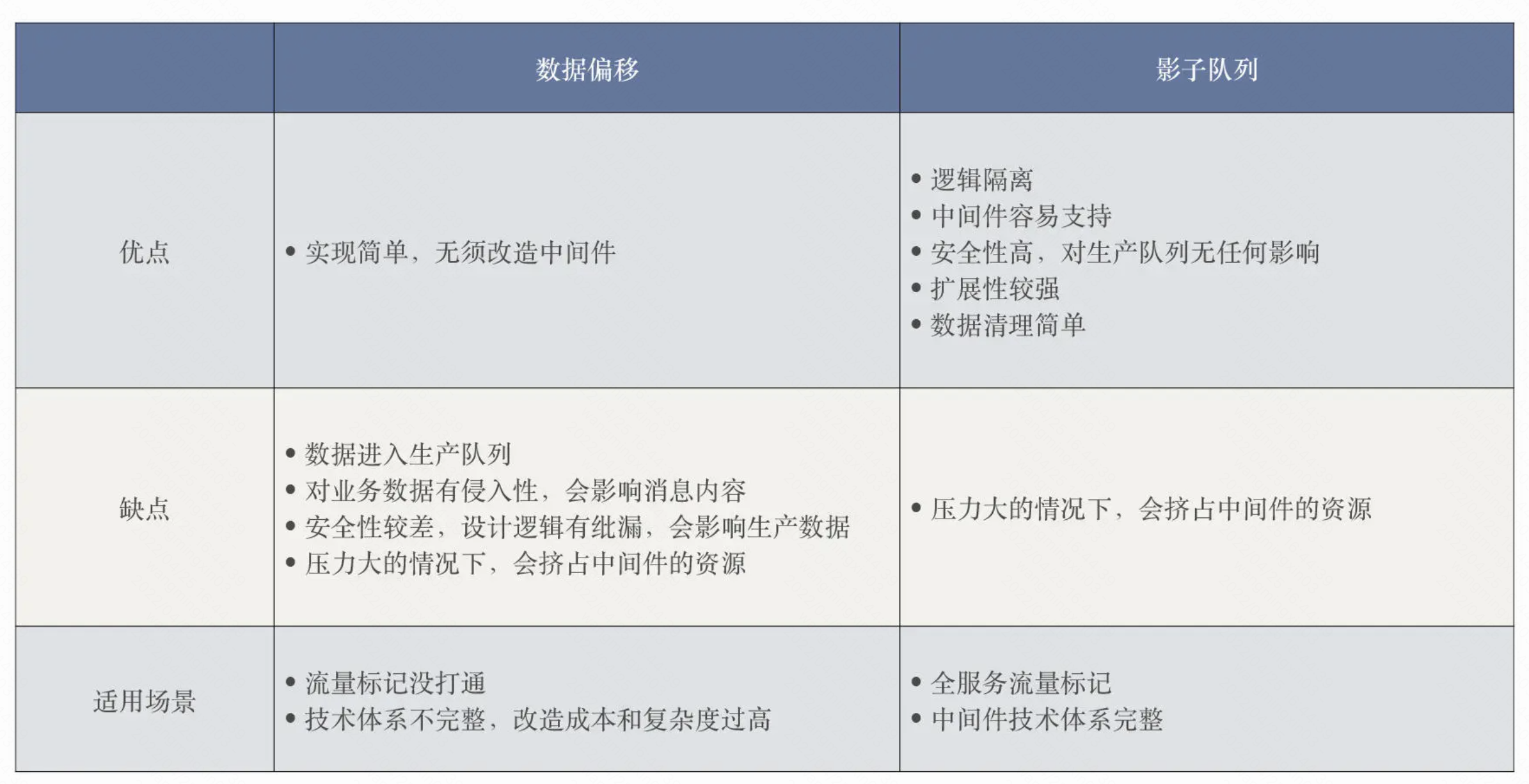
影子队列可以做到消息投递的和消费的隔离,申请一个影子队列,并且让kafka的生产端可以识别测试标识就行,把消息投递到不同的队列
我们不仅要在中间件层面做改造,还有一些组件,比如本地缓存、多线程、消费binlog的服务等,都需要支持测试标识的传递
我们还需要做到监控和日志的隔离
还有一个很关键的改造,就是一个 节点流量策略配置平台 ,这个平台是支持按照服务粒度去配置我们的组件和存储层应对测试流量的策略
比如一个测试流量来了,到了mysql是路由到线上表还是影子表,测试流量可以透传到下游rpc嘛,是否设置挡板
为了安全性,我们的测试流量的读流量默认都是可以读线上的,比如读到mysql就说读线上表,读到redis就说默认读线上key
测试流量的写操作一般默认是短路或者写抛异常,出于安全角度考虑避免写操作写入到线上真实的存储中
然后我们再对流量存储隔离这块多做点介绍吧~
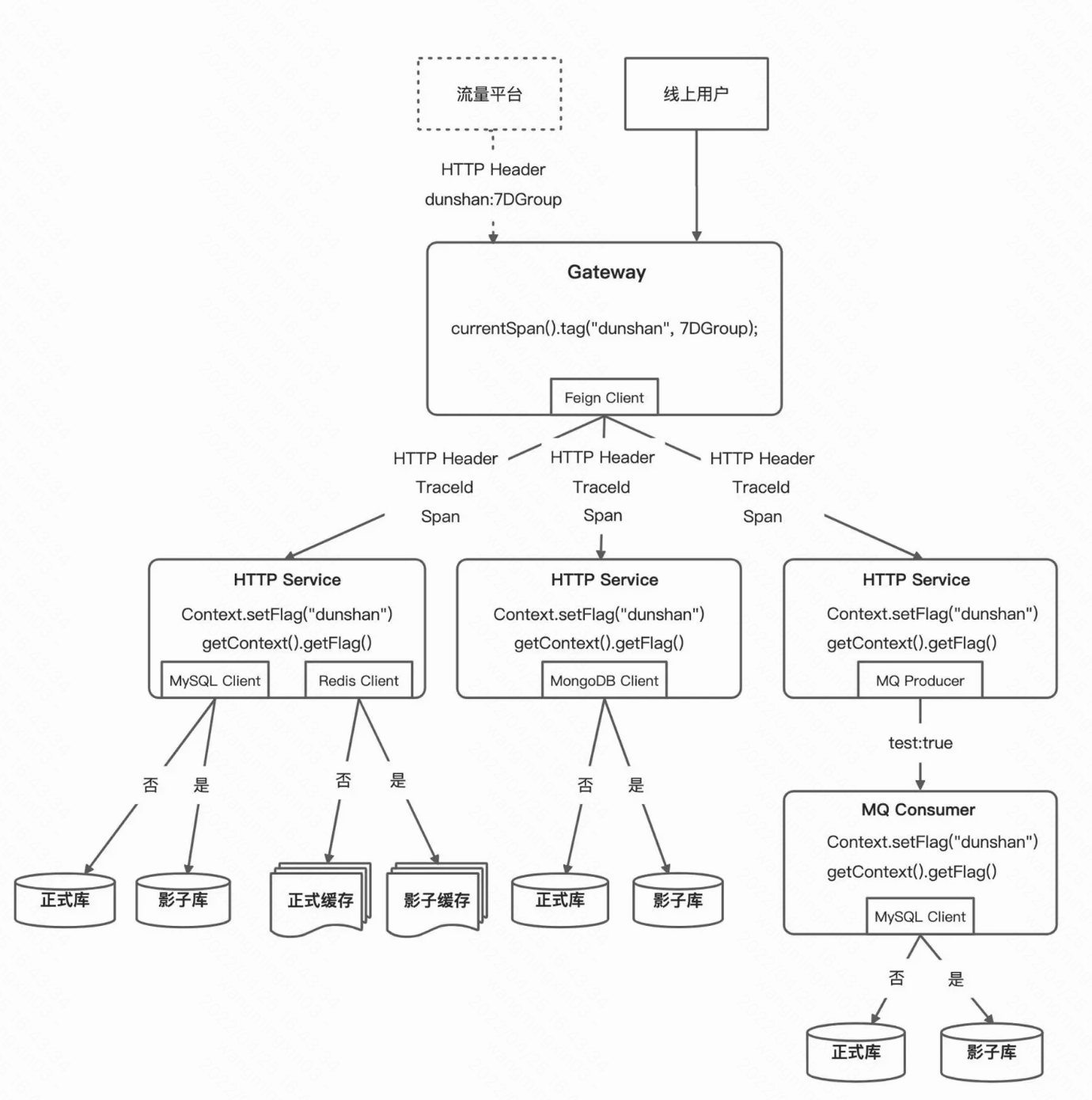
数据库隔离方案
Redis隔离方案
消息队列隔离方案
最后扩展下,我们能否复用全链路压测这套底层做线上测试呢?
比如这套能力我们支持不同的测试流量,支持压测、支持人工测试、支持自动化测试
不同测试我们都有不同的节点流量策略配置
比如压测我们只关注一些核心借口、核心链路,可以把一些非核心的短路掉,让压测流量不抵达下游
再比如像人工测试流量我们更希望高仿真、高还原,因此链路都需要是通的,只不过在一些存储层做些影子隔离
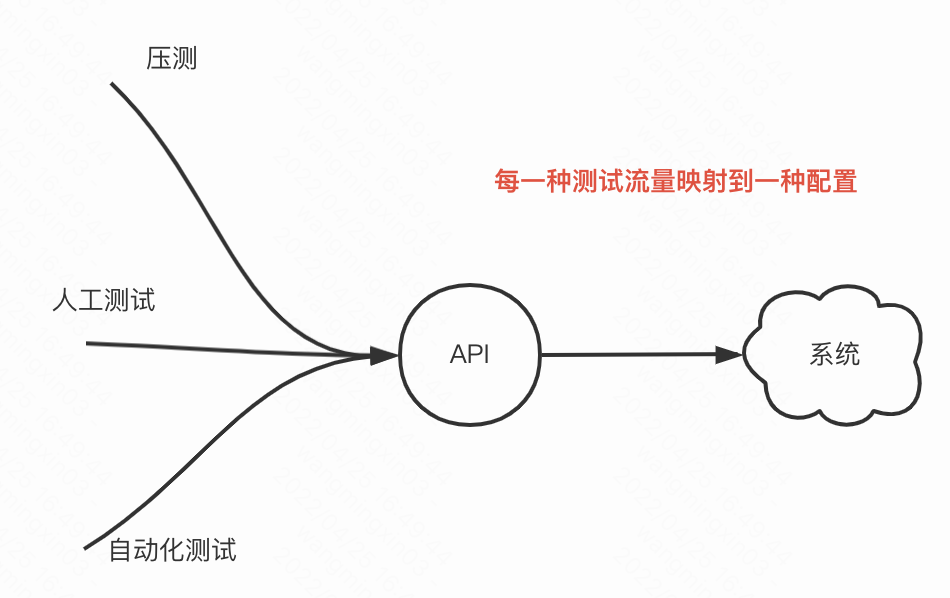
那基于这一套能力我们有什么应用场景呢?
哈哈,说下我们目前用这个的一个场景,大家想想一些业务有线上付费功能的话,是不是需要我们申请预算,或者自己充钱去验证,或者需要业务做改造支持一些mock能力
那现在我们可以怎么搞呢?
我们一个用户可以创建一个影子账户钱包,我在线上测试的时候,给付费接口传递影子标识,那读写流量就可以路由到影子的钱包,那这些钱包本身就是影子表里的,不是真实的钱,我们可以往影子表里无限充钱,同理我们可以在线上无限的去做线上付费功能的验证,美滋滋~
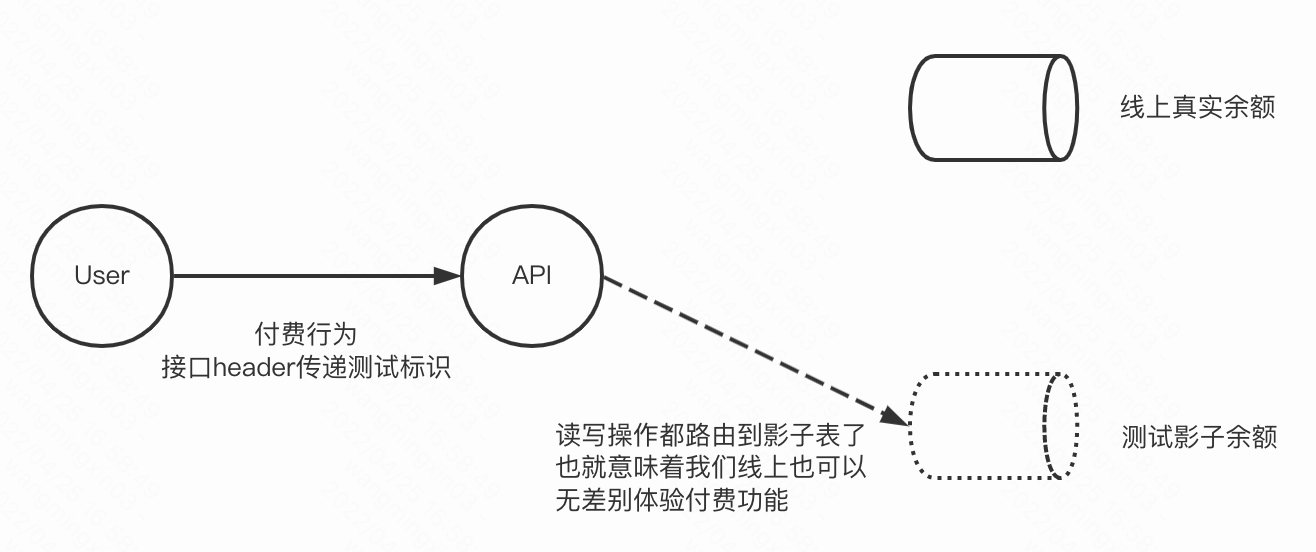
这种搞法我在生产环境也算是落地成功了,哈哈
淦完了,结束,累死。。。

说点什么
您将是第一位评论人!