Kafka为什么是高性能,高吞吐的?
1)取决于kafka的顺序写(Kafka可以每秒600M顺序读写 ),顺序写速读比随机写速度高很多
2)批量发送,在异步发送模式中。kafka允许进行批量发送,也就是先将消息缓存到内存中,然后一次请求批量发送出去。这样减少了磁盘频繁io以及网络 IO造成的性能瓶颈
3)零拷贝。消息从发送到落地保存,broker维护的消息日志本身就是文件目录,每个文件都是二进制保存,生产者和消费者使用相同的格式来处理。在消费者获取消息时,服务器先从硬盘读取数据到内存,然后把内存中的数据原封不懂的通过socket发送给消费者。虽然这个操作描述起来很简单,但实际上经历了很多步骤
对比两个图看一下零拷贝的优势:
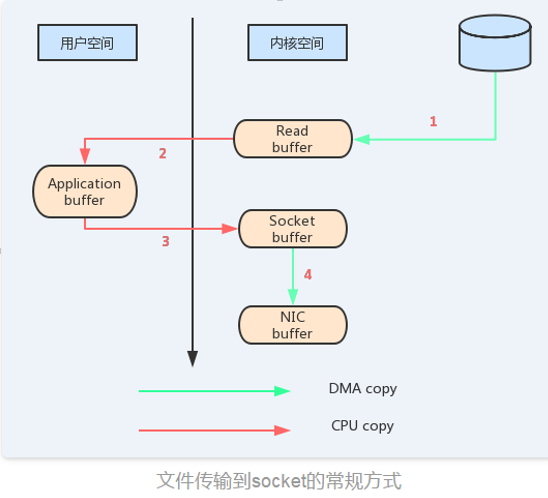
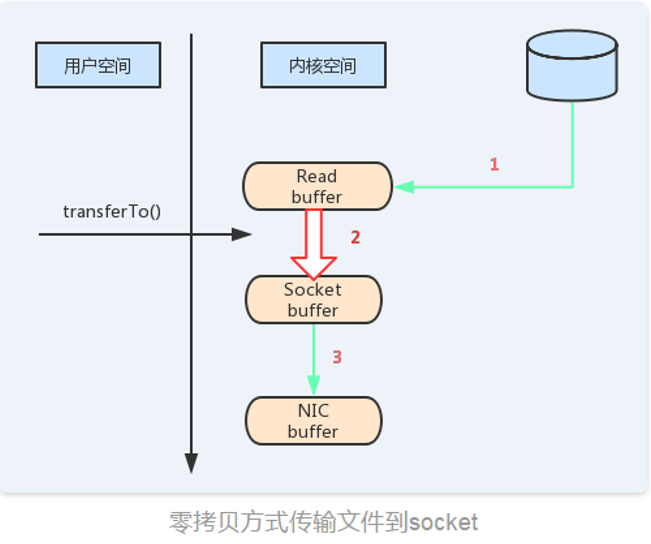
Kafka的日志策略:
1)日志保留策略
无论消费者是否已经消费了消息,kafka都会一直保存这些消息,但并不会像数据库那样长期保存。为了避免磁盘被占满,kafka会配置响应的保留策略(retention policy),以实现周期性地删除陈旧的消息
- 根据消息保留的时间,当消息在kafka中保存的时间超过了指定时间,就可以被删除;
- 根据topic存储的数据大小,当topic所占的日志文件大小大于一个阀值,则可以开始删除最旧的消息
2)日志压缩策略
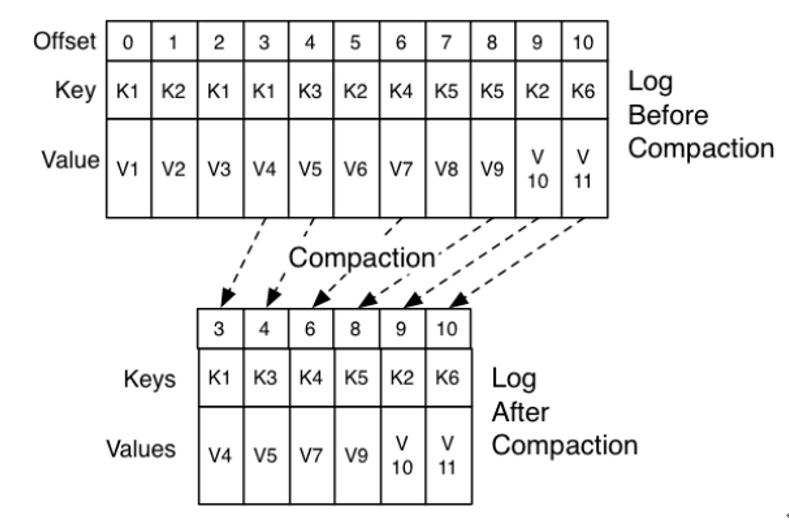
kafka的副本机制
–replication-factor 可以设置副本数
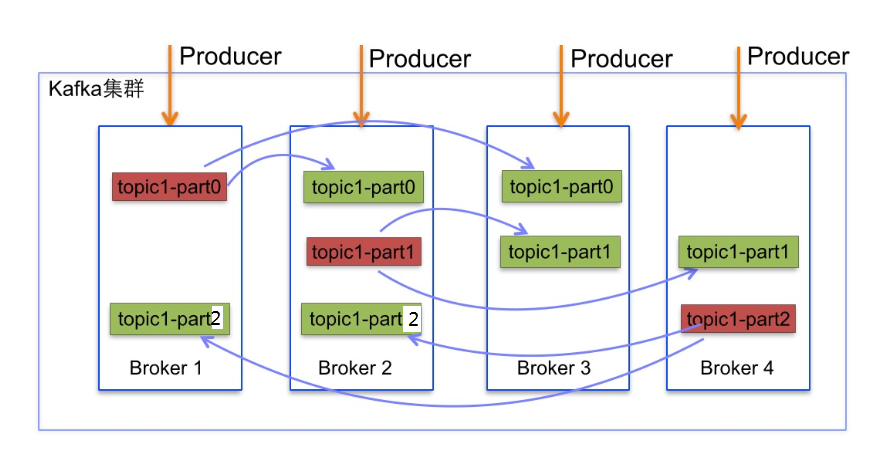
上图副本数为3,一主两从,从需要同步主的数据
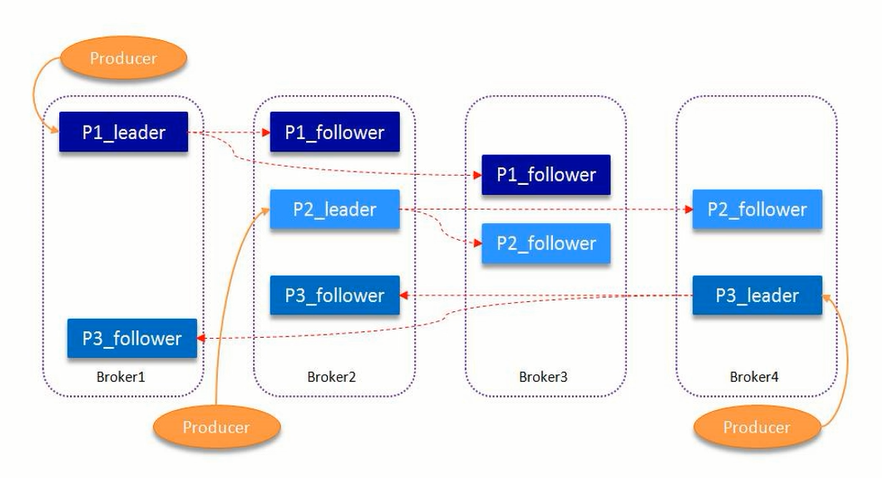
什么叫ISR (副本同步队列),维护有资格同步主的数据的从的队列
leader负责维护和跟踪ISR中所有follower滞后状态。
当生产者发送一条消息到Broker,leader写入消息并复制到所有follower。消息提交之后才被成功复制到所有的同步副本。消息复制延迟受最慢的follower限制,重要的是快速检测慢副本,如果follower”落后”太多或者失效,leader将会把它从replicas从ISR移除。
什么是HW和LEO?
HW : HighWatermark
LEO : Log End Offset
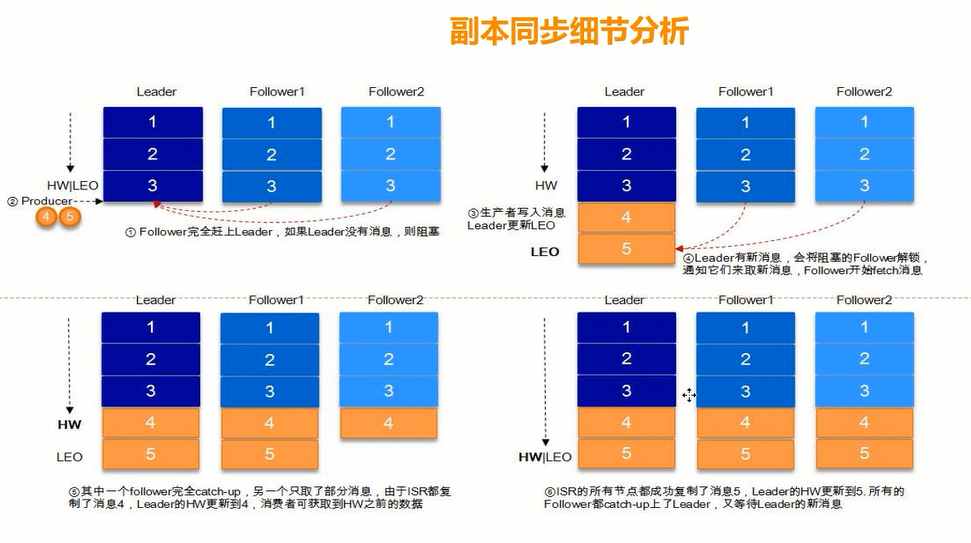
只有到HW的消息才可见,才可以消费
注意:副本数如果太多,同步数据,性能会造成影响,所以副本数也不能太多。
转载请注明:汪明鑫的个人博客 » 消息队列之Kafka的细节

说点什么
您将是第一位评论人!